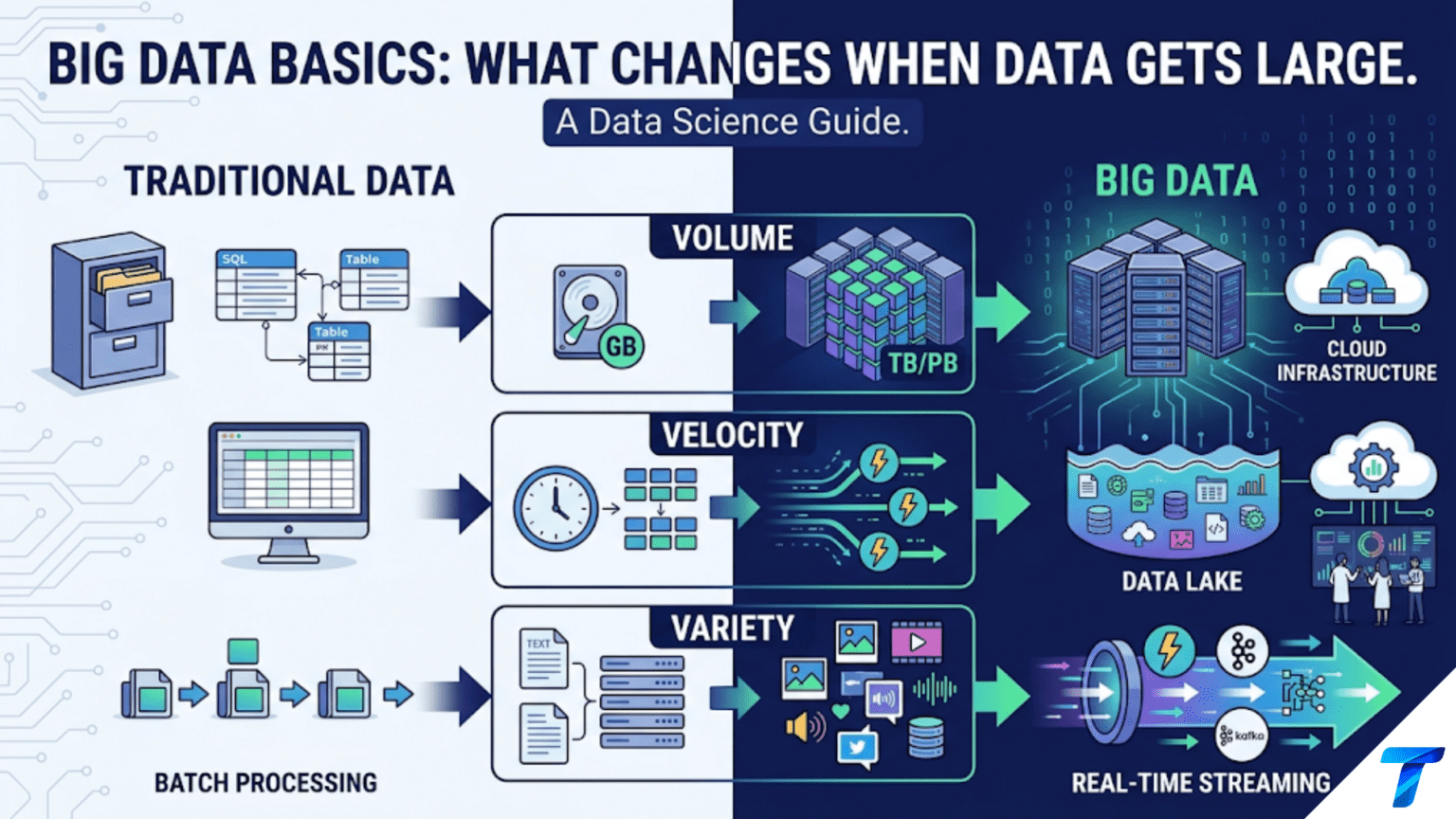
“Big data” is not a precise size threshold, it is the point at which your current tools can no longer process data within acceptable time and memory constraints. For most data scientists, this happens in three phases: single-machine memory limits (when a dataset exceeds available RAM, typically 8–64 GB), single-machine compute limits (when processing takes too long even if data fits in memory), and distributed computing limits (when a single server can no longer store or process the data at all). Each phase requires different tools: chunked processing and efficient formats for memory issues, Polars or Dask for compute-bound single-machine problems, and Apache Spark or cloud data warehouses for truly distributed workloads.
Introduction
There is a moment in every data scientist’s career when their trusted tools stop working. The pandas DataFrame that’s handled every project until now takes 20 minutes to load — or simply crashes with a MemoryError. The CSV file the stakeholder sent is 80 GB. The SQL query that used to return in seconds now times out on 10 billion rows. The model training loop that took an hour now projects to take three weeks.
This moment is not a failure. It is a transition — from the “small data” world where your laptop handles everything to the “large data” world where data processing requires deliberate engineering decisions. The tools, techniques, and mental models change, but the goal remains the same: extract insight from data.
This article explains what actually changes when data gets large — conceptually and practically. We’ll cover the three failure modes of at-scale data, the specific limitations of pandas and standard tools, the spectrum of solutions from pragmatic quick fixes to full distributed systems, and the practical techniques that let you work effectively with large data on a standard laptop. The goal is not to make you a distributed systems engineer — it’s to give you a clear mental model of the landscape so you can choose the right tool for each situation.
What “Big Data” Actually Means
The phrase “big data” entered the industry lexicon with a lot of hype and very little precision. Let’s define it functionally.
Data is “big” relative to your tools. One hundred gigabytes is trivial for a Spark cluster and impossible for a 16 GB laptop. Ten terabytes is routine for BigQuery and impossible for most single servers. The relevant question is not “is this big data?” but “does my current tool handle this data within acceptable constraints?”
The Three Axes of Scale
Big data problems typically manifest along one or more of three dimensions:
Volume — the sheer size of the data. This is what most people mean by “big data.” A company’s full transaction history for 10 years. All social media posts ever made. Every sensor reading from a factory floor. Volume is the most tractable dimension — more storage is relatively cheap, and more compute can be rented.
Velocity — the rate at which new data arrives. A financial exchange processes millions of trades per second. A social media platform ingests millions of posts per minute. IoT devices emit continuous streams. High-velocity data can’t be processed in batch — it requires streaming architectures that process data as it arrives.
Variety — the diversity of data formats and sources. Combining structured transaction records with unstructured text, images, audio, and semi-structured JSON logs. Variety is often the hardest dimension because it requires integration across fundamentally different representations.
Most data scientists primarily encounter volume problems. This article focuses there.
The Practical Size Thresholds
| Dataset Size | Typical Situation | Primary Bottleneck |
|---|---|---|
| < 100 MB | Fits comfortably in memory | Nothing — pandas works perfectly |
| 100 MB – 1 GB | Fits in memory, takes a few seconds to load | Convenience; use Parquet instead of CSV |
| 1 GB – 10 GB | May fit in memory on large machines; slow with CSV | Memory and format; Parquet + Polars |
| 10 GB – 100 GB | Exceeds typical laptop RAM | Memory; chunked processing or Dask |
| 100 GB – 10 TB | Single machine can’t hold in memory | Distributed computing; Spark or warehouse |
| > 10 TB | Requires distributed storage | Cloud data warehouse (BigQuery, Redshift, Snowflake) |
These are guidelines, not hard boundaries. A 5 GB CSV with 200 text columns might be slower to process than a 50 GB Parquet file with 10 numeric columns. Memory and compute constraints interact with data structure, operations performed, and available hardware.
How pandas Fails at Scale
Understanding why pandas fails at scale helps you understand what alternatives are solving.
Failure Mode 1: Loading Everything Into Memory
pandas stores the entire DataFrame in memory at once. When you call pd.read_csv("large_file.csv"), pandas reads every byte and allocates RAM for every value before you can do anything with it.
import pandas as pd
import sys
# This works fine for a 500 MB file on a 16 GB machine
df = pd.read_csv("data/medium_file.csv")
print(f"DataFrame memory: {df.memory_usage(deep=True).sum() / 1e9:.2f} GB")
# This crashes or swaps to disk for a 20 GB file on the same machine
try:
df_large = pd.read_csv("data/large_file.csv") # MemoryError!
except MemoryError:
print("Not enough RAM to load this file")
# Diagnose available memory
import psutil
available_gb = psutil.virtual_memory().available / 1e9
total_gb = psutil.virtual_memory().total / 1e9
print(f"Available RAM: {available_gb:.1f} GB / {total_gb:.1f} GB total")Failure Mode 2: Inefficient Memory Use
Even when data fits in memory, pandas often uses far more RAM than the data actually requires:
import pandas as pd
import numpy as np
# Demonstrate pandas memory inefficiency
n = 1_000_000
df = pd.DataFrame({
"id": range(n),
"country": ["USA", "UK", "DE", "FR", "JP"] * (n // 5), # 5 unique values
"status": ["active", "inactive", "pending"] * (n // 3 + 1), # 3 unique values
"score": np.random.uniform(0, 1, n),
"count": np.random.randint(0, 1000, n)
})
print("Memory usage with default dtypes:")
print(df.memory_usage(deep=True))
print(f"Total: {df.memory_usage(deep=True).sum() / 1e6:.1f} MB")
# country and status stored as object (Python strings) — very inefficient!
# Optimize with appropriate types
df_optimized = df.copy()
df_optimized["country"] = df["country"].astype("category") # 5 unique values
df_optimized["status"] = df["status"].astype("category") # 3 unique values
df_optimized["score"] = df["score"].astype("float32") # float64 → float32
df_optimized["count"] = df["count"].astype("int16") # int64 → int16 (fits 0-1000)
print("\nMemory usage after optimization:")
print(df_optimized.memory_usage(deep=True))
print(f"Total: {df_optimized.memory_usage(deep=True).sum() / 1e6:.1f} MB")
# Often 5-10x reduction!Failure Mode 3: Single-Core Processing
pandas operations run on a single CPU core by default. A machine with 16 cores and 64 GB of RAM runs a complex groupby-transform on a 5 GB DataFrame using exactly 1/16 of its available compute power. For computationally intensive operations, this is a severe bottleneck.
Failure Mode 4: Copy-Heavy Operations
pandas creates copies of data for many operations — filtering, assigning new columns, concatenating. Each copy consumes additional RAM, making the peak memory usage during an operation 2-3× the size of the input DataFrame.
import pandas as pd
# This apparently simple pipeline creates multiple copies
result = (df
.query("status == 'active'") # Creates a copy
.assign(score_pct=lambda x: x["score"] * 100) # Creates another copy
.groupby("country")["score_pct"].mean() # Yet another intermediate
)
# Peak RAM usage: 3-4× the size of dfTier 1: Fix the Format and Types
Before reaching for any new tool, fix the two most common causes of unnecessary slowness: wrong file format and wrong data types. This alone often eliminates 80% of performance problems.
Switch from CSV to Parquet
import pandas as pd
import time, os
# Measure the difference for a realistic 2 GB CSV
# (Run once to create Parquet)
df = pd.read_csv("data/transactions.csv")
df.to_parquet("data/transactions.parquet", index=False)
# Compare read times
t0 = time.time()
df_csv = pd.read_csv("data/transactions.csv")
csv_time = time.time() - t0
csv_mb = os.path.getsize("data/transactions.csv") / 1e6
t0 = time.time()
df_parquet = pd.read_parquet("data/transactions.parquet")
parquet_time = time.time() - t0
parquet_mb = os.path.getsize("data/transactions.parquet") / 1e6
print(f"CSV: {csv_mb:.0f} MB, {csv_time:.1f}s to load")
print(f"Parquet: {parquet_mb:.0f} MB, {parquet_time:.1f}s to load")
print(f"Size reduction: {csv_mb/parquet_mb:.1f}× | Speed: {csv_time/parquet_time:.1f}×")
# Typical result: 6-8× smaller, 5-15× faster
# Read only the columns you need (Parquet's killer feature)
t0 = time.time()
df_cols = pd.read_parquet(
"data/transactions.parquet",
columns=["customer_id", "amount", "transaction_date"] # 3 of 20 columns
)
print(f"Parquet (3 cols only): {time.time()-t0:.2f}s")
# Often 5-10× faster than reading all columnsOptimize Data Types in pandas
import pandas as pd
import numpy as np
def optimize_dataframe(df: pd.DataFrame) -> pd.DataFrame:
"""
Automatically downcast numeric columns and categorize
low-cardinality string columns to minimize memory usage.
Parameters
----------
df : pd.DataFrame
DataFrame to optimize.
Returns
-------
pd.DataFrame
Memory-optimized copy of the DataFrame.
"""
df = df.copy()
before_mb = df.memory_usage(deep=True).sum() / 1e6
for col in df.columns:
col_type = df[col].dtype
# Downcast integers
if col_type in ["int64", "int32"]:
df[col] = pd.to_numeric(df[col], downcast="integer")
# Downcast floats
elif col_type in ["float64", "float32"]:
df[col] = pd.to_numeric(df[col], downcast="float")
# Categorize low-cardinality strings
elif col_type == "object":
n_unique = df[col].nunique()
n_total = len(df[col])
# If fewer than 5% unique values: use category dtype
if n_unique / n_total < 0.05:
df[col] = df[col].astype("category")
after_mb = df.memory_usage(deep=True).sum() / 1e6
print(f"Memory: {before_mb:.1f} MB → {after_mb:.1f} MB "
f"({(1 - after_mb/before_mb)*100:.0f}% reduction)")
return df
# Apply to a real DataFrame
df_raw = pd.read_csv("data/transactions.csv")
df_opt = optimize_dataframe(df_raw)Use Chunked Reading for Files Too Large to Load
When the file genuinely doesn’t fit in RAM, process it in chunks:
import pandas as pd
# Process a 20 GB CSV in 500k-row chunks without loading all into memory
CHUNK_SIZE = 500_000
# Example: compute total revenue by product category
category_revenue = {}
for chunk_num, chunk in enumerate(pd.read_csv("data/large_transactions.csv",
chunksize=CHUNK_SIZE,
dtype={"product_id": str})):
# Process each chunk
chunk_agg = chunk.groupby("category")["amount"].sum()
for category, revenue in chunk_agg.items():
category_revenue[category] = category_revenue.get(category, 0) + revenue
if chunk_num % 10 == 0:
rows_processed = (chunk_num + 1) * CHUNK_SIZE
print(f"Processed ~{rows_processed:,} rows...")
# Convert to DataFrame
result = pd.Series(category_revenue).sort_values(ascending=False)
print(result)Tier 2: Polars — Faster pandas on a Single Machine
Polars is a DataFrame library written in Rust that is designed from the ground up for performance. For datasets that fit in memory (or nearly fit), Polars is often the best single upgrade you can make — it’s typically 5-50× faster than pandas for complex operations, uses multi-core processing by default, and has a more consistent API.
pip install polarsimport polars as pl
import time
# Read a large Parquet file
t0 = time.time()
df = pl.read_parquet("data/transactions.parquet")
print(f"Polars read: {time.time()-t0:.2f}s")
# Polars uses lazy evaluation — build a query plan, execute when needed
# This is the recommended pattern for large data
query = (
pl.scan_parquet("data/transactions.parquet") # Lazy scan — no data loaded yet
.filter(pl.col("status") == "completed")
.filter(pl.col("amount") > 10.0)
.group_by(["customer_id", pl.col("transaction_date").dt.month().alias("month")])
.agg([
pl.col("amount").sum().alias("monthly_spend"),
pl.col("amount").count().alias("n_transactions"),
pl.col("amount").mean().alias("avg_transaction"),
])
.sort("monthly_spend", descending=True)
)
# Execute the full query — Polars optimizes it automatically
t0 = time.time()
result = query.collect()
print(f"Polars lazy query: {time.time()-t0:.2f}s")
print(result.head(10))
# Polars syntax is similar to pandas but uses method chaining consistently
result = (
pl.read_parquet("data/transactions.parquet")
.filter(pl.col("amount") > 50)
.with_columns([
(pl.col("amount") * 1.1).alias("amount_with_tax"),
pl.col("transaction_date").dt.year().alias("year"),
pl.col("transaction_date").dt.month().alias("month"),
])
.group_by(["year", "month", "category"])
.agg([
pl.col("amount").sum().alias("revenue"),
pl.col("customer_id").n_unique().alias("unique_customers"),
])
.sort(["year", "month"])
)
print(result)Polars vs. pandas: Key Differences
| Feature | pandas | Polars |
|---|---|---|
| Core language | Python/C | Rust |
| Multi-core by default | No | Yes |
| Memory model | Eager (load all now) | Lazy (plan then execute) |
| Null handling | NaN (float) + None | null (explicit) |
| String indexing | Yes (df["col"]) | Yes, but .loc/.iloc limited |
| Ecosystem integration | Mature (sklearn, etc.) | Growing |
| Learning curve | Familiar | New syntax |
For datasets between 1 GB and ~100 GB on a single machine, Polars is often the best choice. For smaller data where developer time matters more than compute time, pandas remains fine.
Tier 3: Dask — Parallel pandas on a Single Machine (or Small Cluster)
Dask provides a pandas-compatible API that scales to datasets larger than RAM by partitioning the data into chunks and processing them in parallel. If you know pandas, you almost know Dask.
pip install dask[dataframe]import dask.dataframe as dd
import pandas as pd
import time
# Read a dataset too large for RAM into a Dask DataFrame
# (no data is loaded yet — Dask creates a task graph)
ddf = dd.read_parquet("data/large_transactions/") # Can be a directory of Parquet files
print(ddf)
# Dask DataFrame: rows unknown, partitions=24
# Dask operations look exactly like pandas
result = (
ddf[ddf["status"] == "completed"]
.groupby("category")["amount"]
.agg(["sum", "count", "mean"])
)
# .compute() triggers execution — processes all partitions in parallel
t0 = time.time()
result_df = result.compute()
print(f"Dask compute: {time.time()-t0:.2f}s")
print(result_df)
# Read from CSV with Dask (create one partition per file)
ddf_csv = dd.read_csv("data/monthly_files/*.csv",
dtype={"customer_id": str},
parse_dates=["transaction_date"])
print(f"Partitions: {ddf_csv.npartitions}")
# Delayed computation pattern
total_revenue = ddf_csv["amount"].sum()
print(total_revenue) # dask.array<sum-aggregate, dtype=float64>
print(total_revenue.compute()) # Execute — returns the actual number
# pandas operations not supported by Dask: need to use .map_partitions
# Apply an arbitrary function to each partition
def add_features(partition):
"""This function runs on each partition separately."""
partition = partition.copy()
partition["month"] = partition["transaction_date"].dt.month
partition["is_weekend"] = partition["transaction_date"].dt.dayofweek >= 5
return partition
ddf_features = ddf_csv.map_partitions(add_features)When Dask Fits — and When It Doesn’t
Dask works best when:
- Data is 2-10× larger than RAM on a single machine
- Operations decompose naturally into independent chunk-level tasks
- You want pandas syntax with minimal code changes
Dask struggles when:
- Operations require shuffling data across partitions (complex joins, sort-then-window)
- Data is genuinely hundreds of GBs — consider a cluster or Spark instead
- You need the full pandas API (some operations are not yet implemented)
Tier 4: Apache Spark — Truly Distributed Processing
Apache Spark is the dominant framework for distributed data processing at scale — terabytes to petabytes. It runs a cluster of machines (workers) coordinated by a driver, distributes data across the cluster, and executes operations in parallel.
For most data scientists, Spark is encountered through managed services: Databricks, Amazon EMR, Google Dataproc, or directly through cloud notebooks.
# PySpark: Python API for Apache Spark
from pyspark.sql import SparkSession
from pyspark.sql import functions as F
# Create (or connect to) a Spark session
spark = SparkSession.builder \
.appName("TransactionAnalysis") \
.config("spark.sql.adaptive.enabled", "true") \
.getOrCreate()
# Read data distributed across the cluster (could be S3, HDFS, GCS)
df = spark.read.parquet("s3://company-data-lake/transactions/year=2024/")
print(f"Total rows: {df.count():,}")
print(f"Partitions: {df.rdd.getNumPartitions()}")
# Spark DataFrame API — similar to pandas/SQL
result = (
df
.filter(F.col("status") == "completed")
.filter(F.col("amount") > 10)
.withColumn("year", F.year("transaction_date"))
.withColumn("month", F.month("transaction_date"))
.groupBy("year", "month", "category")
.agg(
F.sum("amount").alias("revenue"),
F.count("*").alias("n_transactions"),
F.countDistinct("customer_id").alias("unique_customers"),
F.avg("amount").alias("avg_transaction")
)
.orderBy("year", "month")
)
# Show results (triggers execution — Spark is lazy like Polars)
result.show(20)
# Convert to pandas for final analysis (only when result is small enough)
result_pdf = result.toPandas()
# Spark SQL: write transformations in SQL
df.createOrReplaceTempView("transactions")
sql_result = spark.sql("""
SELECT
DATE_TRUNC('month', transaction_date) AS month,
category,
SUM(amount) AS revenue,
COUNT(*) AS n_transactions
FROM transactions
WHERE status = 'completed'
GROUP BY 1, 2
ORDER BY 1, 2
""")
sql_result.show()
# Save results back to storage
result.write \
.mode("overwrite") \
.partitionBy("year", "month") \
.parquet("s3://company-data-lake/monthly_revenue_summary/")
spark.stop()The Spark Mental Model
Spark differs from pandas in critical ways data scientists must understand:
Lazy evaluation: Spark builds a DAG (directed acyclic graph) of transformations when you write code, but executes nothing until you call an action (.count(), .show(), .collect(), .write). This enables Spark to optimize the entire query plan before running it.
Distributed storage: Data is split into partitions distributed across worker nodes. Operations run in parallel on each partition. Shuffling data between workers (for joins, sorts, window functions) is expensive — avoid it when possible.
Fault tolerance: If a worker node fails, Spark recomputes the lost partition from the lineage (the record of transformations applied). This is why Spark doesn’t need to checkpoint every intermediate result.
Not pandas: Spark DataFrames have a different API, different performance characteristics, and different failure modes. Many pandas idioms don’t translate. Write Spark code thinking about distributed execution.
Tier 5: Cloud Data Warehouses — SQL at Scale
For analytical workloads on very large datasets (100 GB – petabytes), cloud data warehouses are often the most practical solution for data scientists. They handle all the distributed infrastructure automatically — you write SQL and get results.
The Major Platforms
Google BigQuery:
from google.cloud import bigquery
import pandas as pd
client = bigquery.Client(project="my-project")
# Query 10 billion rows in seconds — BigQuery handles the scale
query = """
SELECT
DATE_TRUNC(transaction_timestamp, MONTH) AS month,
product_category,
SUM(amount) AS revenue,
COUNT(DISTINCT customer_id) AS unique_customers
FROM `my-project.analytics.transactions`
WHERE DATE(transaction_timestamp) >= '2024-01-01'
GROUP BY 1, 2
ORDER BY 1, 2
"""
# Execute and return as pandas DataFrame
result = client.query(query).to_dataframe()
print(f"Result: {result.shape}")Snowflake:
import snowflake.connector
import pandas as pd
conn = snowflake.connector.connect(
user=os.environ["SNOWFLAKE_USER"],
password=os.environ["SNOWFLAKE_PASSWORD"],
account=os.environ["SNOWFLAKE_ACCOUNT"],
warehouse="ANALYTICS_WH",
database="PROD",
schema="PUBLIC"
)
cursor = conn.cursor()
cursor.execute("""
SELECT
customer_id,
COUNT(*) AS num_orders,
SUM(total_amount) AS lifetime_value,
MAX(order_date) AS last_order_date
FROM orders
WHERE order_date >= DATEADD(year, -2, CURRENT_DATE())
GROUP BY customer_id
HAVING COUNT(*) >= 2
""")
df = cursor.fetch_pandas_all()
conn.close()DuckDB (local data warehouse — often the best choice for 1 GB – 200 GB on a single machine):
import duckdb
import pandas as pd
# DuckDB can query Parquet files directly with SQL — no loading required
result = duckdb.query("""
SELECT
strftime(transaction_date, '%Y-%m') AS year_month,
category,
SUM(amount) AS revenue,
COUNT(DISTINCT customer_id) AS unique_customers
FROM read_parquet('data/transactions_*.parquet')
WHERE status = 'completed'
GROUP BY 1, 2
ORDER BY 1, 2
""").df()
print(result.head())
# DuckDB can also query pandas DataFrames
df_pandas = pd.read_parquet("data/customers.parquet")
customer_stats = duckdb.query("""
SELECT
country,
COUNT(*) AS n_customers,
AVG(lifetime_value) AS avg_ltv,
SUM(lifetime_value) AS total_ltv
FROM df_pandas -- References the pandas variable directly!
GROUP BY country
ORDER BY total_ltv DESC
""").df()DuckDB is particularly powerful because it:
- Requires no server setup — runs in-process like SQLite
- Queries Parquet files directly without loading them
- Supports full SQL including window functions, CTEs, and advanced analytics
- Achieves performance close to dedicated data warehouses on a single machine
- References pandas DataFrames directly in SQL queries
The Shuffle Problem: Why Distributed Computing Is Hard
One of the most important concepts for working with distributed data is understanding shuffles — the redistribution of data across worker nodes.
Most DataFrame operations are embarrassingly parallel: filter rows, transform columns, aggregate within groups. Each partition is processed independently. Fast.
Some operations require shuffling: joins on arbitrary keys, global sorts, window functions across partition boundaries. Data from many partitions must be collected, sorted, and redistributed. Slow and expensive — often the dominant cost in a Spark job.
# PySpark: understanding shuffle operations
# CHEAP: Filter, projection, partition-local aggregation
cheap = df.filter(F.col("status") == "completed") \
.select("customer_id", "amount") \
.groupBy("status").count() # Group key already partitioned
# EXPENSIVE: Joins require shuffle when keys aren't co-partitioned
expensive_join = transactions_df.join(
customers_df, on="customer_id", how="inner"
) # Triggers shuffle if not pre-partitioned by customer_id
# OPTIMIZATION: Repartition by join key before joining
transactions_repartitioned = transactions_df.repartition(200, "customer_id")
customers_repartitioned = customers_df.repartition(200, "customer_id")
cheap_join = transactions_repartitioned.join(
customers_repartitioned, on="customer_id", how="inner"
) # No shuffle needed — data already co-located
# BROADCAST JOIN: When one table is small, broadcast it to all workers
from pyspark.sql.functions import broadcast
cheap_broadcast_join = transactions_df.join(
broadcast(customers_df), # Send entire customers table to each worker
on="customer_id", how="inner"
) # Very fast — no shuffleThe general rule: minimize shuffles. Filter and aggregate as early as possible to reduce data volume before any operation that requires cross-partition communication.
Memory Management: The Art of Fitting Data in RAM
Even when using distributed tools, efficient memory management on individual workers matters. Key techniques:
1. Select Only the Columns You Need
# The most impactful single optimization — often 5-10× memory reduction
# WRONG: Load everything, use 5 columns
df = pd.read_parquet("data/transactions.parquet") # All 25 columns
subset = df[["customer_id", "amount", "date", "category", "status"]]
# RIGHT: Load only what you need
subset = pd.read_parquet(
"data/transactions.parquet",
columns=["customer_id", "amount", "date", "category", "status"]
)2. Filter Early — Before Joining or Aggregating
# WRONG: Load everything, filter late
df = pd.read_parquet("data/10_years_transactions.parquet")
df_2024 = df[df["year"] == 2024] # 10× too much data loaded
# RIGHT: Filter at read time (Parquet predicate pushdown)
df_2024 = pd.read_parquet(
"data/10_years_transactions.parquet",
filters=[("year", "==", 2024)] # Parquet skips irrelevant row groups
)3. Use Generators for Large Pipelines
import pandas as pd
from pathlib import Path
def process_large_dataset(input_dir: str, output_path: str):
"""
Process all Parquet files in a directory without loading all into RAM.
Uses generator pattern to keep memory bounded.
"""
parquet_files = sorted(Path(input_dir).glob("*.parquet"))
total_files = len(parquet_files)
def chunk_generator():
for i, filepath in enumerate(parquet_files):
print(f"Processing file {i+1}/{total_files}: {filepath.name}")
chunk = pd.read_parquet(
filepath,
columns=["customer_id", "amount", "category", "status"]
)
# Process each chunk
chunk = chunk[chunk["status"] == "completed"]
chunk["amount"] = chunk["amount"].astype("float32")
yield chunk
# Aggregate across all chunks
result_parts = []
for chunk in chunk_generator():
agg = chunk.groupby("category")["amount"].agg(["sum", "count"])
result_parts.append(agg)
# Combine all chunk-level results
final = pd.concat(result_parts).groupby(level=0).sum()
final.to_parquet(output_path)
print(f"Results saved to {output_path}")Choosing the Right Tool: A Decision Framework
Start here: What is the data size?
< 1 GB
└── Use pandas with Parquet format. Done.
1 GB – 10 GB
├── Fits in RAM? → pandas + optimize dtypes + Parquet
└── Close to RAM limit? → Polars (faster) or DuckDB (SQL interface)
10 GB – 100 GB
├── Need pandas compatibility? → Dask (chunked parallel pandas)
├── Prefer SQL? → DuckDB (queries Parquet files directly, very fast)
└── Need speed above all? → Polars lazy evaluation
100 GB – 10 TB
├── One-time or ad-hoc queries? → Cloud data warehouse (BigQuery, Snowflake)
├── Recurring batch pipeline? → Spark (managed: Databricks, EMR)
└── Already in a warehouse? → SQL in the warehouse, pull summary to Python
> 10 TB
└── Cloud data warehouse or dedicated Spark/Hadoop cluster.
This is infrastructure engineering, not just data science.The Mindset Shift: Push Computation to the Data
The most important conceptual shift when working with large data is pushing computation toward the data rather than pulling data toward your code.
Small data mindset: Pull all the data to my laptop, then compute in Python.
Large data mindset: Express the computation in the language of the system where the data lives (SQL for databases/warehouses, Spark transformations for data lakes), let that system compute the result using its distributed resources, then pull only the summarized result to Python for final analysis and modeling.
# Small data mindset (wrong for large data)
df = pd.read_parquet("s3://bucket/10-billion-row-table/") # Impossible
result = df.groupby("region")["revenue"].sum()
# Large data mindset (right for large data)
# Push the computation to BigQuery, pull only the ~50-row result
result = client.query("""
SELECT region, SUM(revenue) AS total_revenue
FROM `project.dataset.transactions`
GROUP BY region
ORDER BY total_revenue DESC
""").to_dataframe() # Only ~50 rows returned
# Then use pandas/matplotlib/sklearn on the small result
result.plot.bar(x="region", y="total_revenue")This principle — compute where the data lives, pull only what you need — is the unifying concept across all big data tools. Whether you’re writing SQL for BigQuery, Spark transformations on EMR, or Polars lazy expressions on a laptop, the pattern is the same: describe the computation first, execute late, pull small results to Python.
Practical Quick-Start Checklist
Before concluding, here’s a concrete checklist for when you first encounter a “too large” dataset:
import pandas as pd
import os
def large_data_diagnostic(filepath: str):
"""
Quick diagnostic for a large data file.
Suggests appropriate tool without loading the full file.
"""
# File size
size_gb = os.path.getsize(filepath) / 1e9
print(f"File size: {size_gb:.2f} GB")
# Available RAM
import psutil
ram_gb = psutil.virtual_memory().available / 1e9
print(f"Available RAM: {ram_gb:.1f} GB")
# Peek at schema
if filepath.endswith(".parquet"):
import pyarrow.parquet as pq
schema = pq.read_schema(filepath)
meta = pq.read_metadata(filepath)
print(f"Rows: {meta.num_rows:,}")
print(f"Columns: {meta.num_columns}")
print(f"Schema:\n{schema}")
elif filepath.endswith(".csv"):
peek = pd.read_csv(filepath, nrows=5)
print(f"Columns: {list(peek.columns)}")
print(f"Sample:\n{peek}")
# Tool recommendation
print("\n--- RECOMMENDATION ---")
if size_gb < 1:
print("✓ pandas: file is small, use normally")
elif size_gb < ram_gb * 0.5:
print("✓ pandas: fits in RAM; consider Parquet + dtype optimization")
elif size_gb < ram_gb * 2:
print("→ Polars or DuckDB: near RAM limit; use lazy evaluation")
elif size_gb < 100:
print("→ Dask or DuckDB: exceeds RAM; use chunked or distributed processing")
else:
print("→ Spark or cloud data warehouse: requires distributed infrastructure")
# large_data_diagnostic("data/large_transactions.parquet")Summary
Big data is not a category — it is a continuum. The same analytical goal requires different tools at different scales, and knowing when to upgrade tools is as important as knowing which tool to use. The practical progression: fix the format (CSV → Parquet) and data types first, because this alone often eliminates the problem. Then try Polars or DuckDB for single-machine scale-up. Use Dask when you need pandas-compatible chunked parallel processing. Reach for Spark or a cloud data warehouse when data is genuinely distributed or larger than a single machine can handle.
The unifying principle across all these tools is lazy, distributed computation: describe what you want rather than how to compute it, and let the engine optimize and execute the plan using available resources. Whether you’re writing Polars lazy expressions, Dask task graphs, Spark DAGs, or SQL in BigQuery, the same principle applies — push computation toward the data, pull only the results you need.
Key Takeaways
- “Big data” is not a fixed size — it’s the point where your current tools fail to process data within acceptable time and memory; the practical thresholds are roughly: pandas works fine < 1 GB, needs help at 1–10 GB, needs replacement at > 10 GB
- pandas fails at scale through four mechanisms: loading everything into memory at once, inefficient memory use (object dtype strings, int64 for small integers), single-core processing, and copy-heavy operations — fixing dtype and format first often eliminates 80% of performance problems
- Parquet over CSV is the single highest-impact change for large data: typically 6–10× smaller, 10–30× faster to read, preserves types, and supports column pruning and predicate pushdown
- Polars is the best single-machine replacement for pandas when data fits in memory: Rust-based, multi-core by default, lazy evaluation, and typically 5–50× faster for complex operations
- Dask extends the pandas API to datasets larger than RAM through chunked parallel processing; DuckDB provides SQL directly on Parquet files with near-data-warehouse performance on a laptop
- Apache Spark is the industry standard for distributed processing at terabyte to petabyte scale; understand its lazy DAG execution model, the high cost of shuffle operations, and broadcast joins for small tables
- Cloud data warehouses (BigQuery, Snowflake, Redshift) are the most practical solution for analytical queries on very large datasets — write SQL, get results, let the warehouse handle infrastructure
- The core mindset shift: push computation to where the data lives (SQL in the warehouse, transformations in Spark) and pull only small summarized results to Python — never try to move all the data to your code