
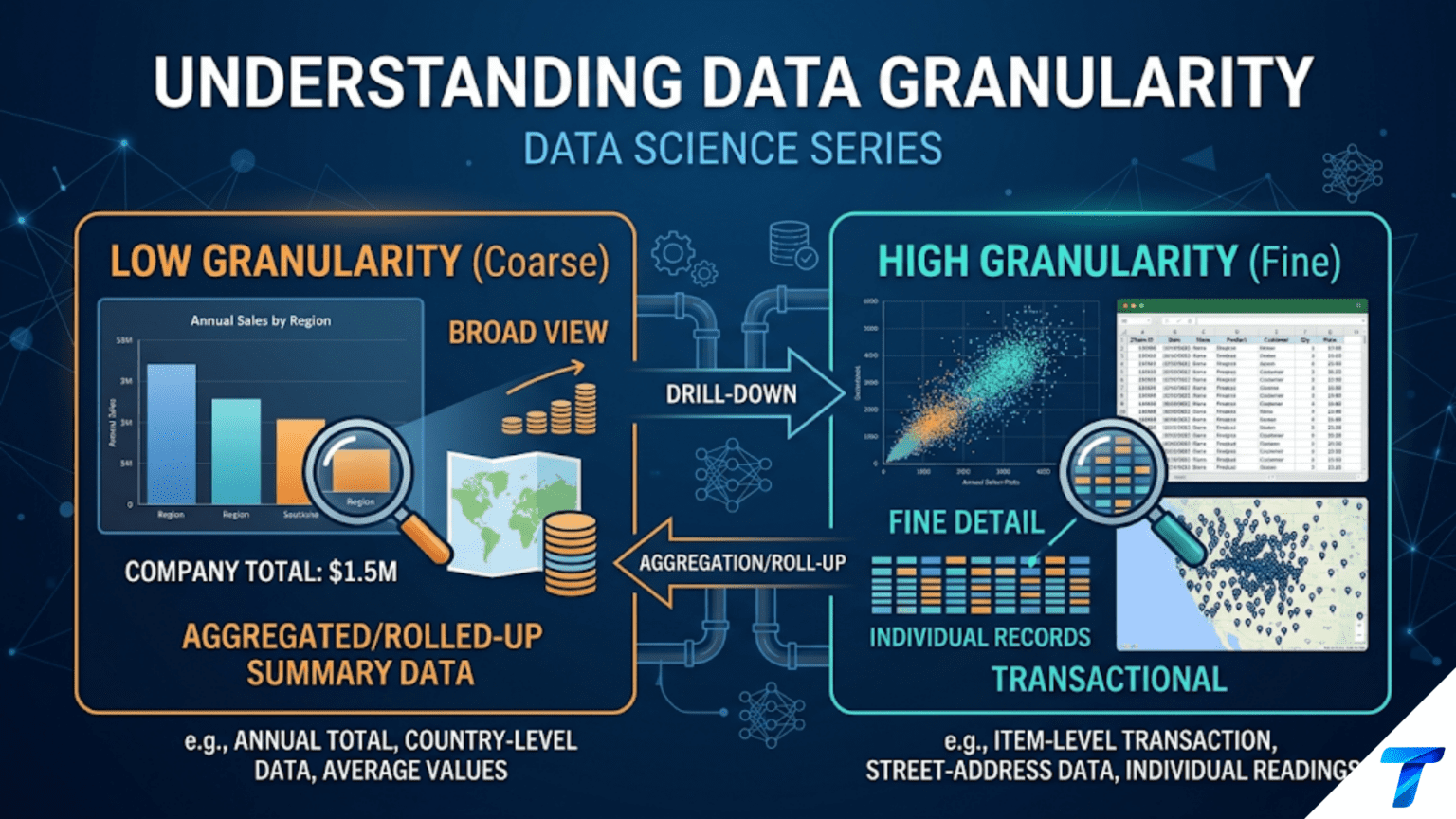
Data granularity (also called the “grain” of a dataset) refers to the level of detail at which data is recorded the answer to the question “what does one row represent?” A transaction-level dataset has one row per purchase; a daily summary has one row per customer per day; a monthly cohort report has one row per cohort per month. Granularity determines what analyses are possible, what joins make sense, and what errors can silently corrupt results. Joining or comparing datasets at different granularities — without first aligning them — is one of the most common sources of inflated counts, double-counted revenue, and subtly wrong aggregations in data science work.
Introduction
Every dataset has a grain — a precise definition of what one row represents. Understanding that grain is not optional background information; it is the most fundamental thing you need to know about any dataset before you can use it correctly.
When the grain is misunderstood or mismatched, the consequences are silently wrong results. You join a customer table (one row per customer) to an orders table (one row per order) without aggregating first, and suddenly every customer metric is inflated — one row per order × the customer’s attributes means a customer with 5 orders has their annual income counted 5 times in any SUM. You merge daily sales summaries with hourly event logs and accidentally multiply counts. You average a pre-aggregated average and get a result that’s meaningless. These bugs are common, hard to detect, and embarrassing when discovered.
This article is about developing precise thinking about data granularity. What it is, how to identify it, how mismatched granularities cause bugs, how to align datasets at different grains, when to aggregate versus when to keep fine-grained data, and the practical techniques for working with hierarchical and multi-level data structures in pandas.
What Is Data Granularity?
Granularity is the level of detail captured in a dataset. More granular means more detail, finer resolution — one row per transaction rather than one row per day. Less granular means more summarized, coarser resolution — one row per quarter rather than one row per month.
The grain is the precise, complete answer to: “What does exactly one row in this dataset represent?”
This is not always obvious. The grain is determined by the combination of all the fields that, together, uniquely identify a row. The primary key (or composite key) defines the grain.
Identifying the Grain: Examples
| Dataset | Grain Statement | Primary Key |
|---|---|---|
| Raw website clickstream | One row per page view per user session | (session_id, event_sequence_num) |
| E-commerce order items | One row per product per order | (order_id, product_id) |
| Daily sales summary | One row per store per day | (store_id, date) |
| Monthly revenue by region | One row per region per month | (region, year_month) |
| Customer lifetime value | One row per customer (all time) | customer_id |
| Sensor readings | One row per device per second | (device_id, timestamp) |
| Survey responses | One row per question per respondent | (respondent_id, question_id) |
Notice that the grain is always defined by its key — the combination of columns that makes every row unique. If you can’t state the grain precisely, you don’t fully understand the dataset.
A Visual Example of Different Granularities
The same underlying data at four levels of granularity:
Transaction grain (finest detail — one row per individual purchase):
transaction_id | customer_id | date | product | amount
TXN_0001 | CUST_001 | 2024-09-01 | Headphones| 149.99
TXN_0002 | CUST_001 | 2024-09-01 | USB Hub | 49.99
TXN_0003 | CUST_002 | 2024-09-01 | Shoes | 89.99
TXN_0004 | CUST_001 | 2024-09-03 | Book | 34.99
TXN_0005 | CUST_003 | 2024-09-03 | Yoga Mat | 29.99Customer-day grain (one row per customer per day):
customer_id | date | num_transactions | total_spend
CUST_001 | 2024-09-01 | 2 | 199.98
CUST_001 | 2024-09-03 | 1 | 34.99
CUST_002 | 2024-09-01 | 1 | 89.99
CUST_003 | 2024-09-03 | 1 | 29.99Customer grain (one row per customer — all time):
customer_id | num_transactions | lifetime_value | first_purchase | last_purchase
CUST_001 | 3 | 234.97 | 2024-09-01 | 2024-09-03
CUST_002 | 1 | 89.99 | 2024-09-01 | 2024-09-01
CUST_003 | 1 | 29.99 | 2024-09-03 | 2024-09-03Daily grain (one row per day — all customers aggregated):
date | num_transactions | num_customers | total_revenue
2024-09-01 | 3 | 2 | 339.97
2024-09-03 | 2 | 2 | 64.98All four tables represent the same five transactions. The grain determines what questions each can answer and what joins are valid.
Why Granularity Matters: The Bugs It Causes
The Fan-Out Bug: Joining Tables at Different Grains
The most common and dangerous granularity mistake is joining a higher-grain table (fewer, summarized rows) to a lower-grain table (more, detailed rows) without accounting for the multiplication of rows.
import pandas as pd
# Customers table: one row per customer (customer grain)
customers = pd.DataFrame({
"customer_id": ["CUST_001", "CUST_002", "CUST_003"],
"customer_name": ["Jane Smith", "Bob Johnson", "Alice Williams"],
"annual_income": [85000, 62000, 110000], # income repeated once per customer
"city": ["Austin", "Seattle", "Chicago"]
})
# Orders table: one row per order (order grain)
orders = pd.DataFrame({
"order_id": ["ORD_001", "ORD_002", "ORD_003", "ORD_004", "ORD_005"],
"customer_id": ["CUST_001", "CUST_001", "CUST_001", "CUST_002", "CUST_003"],
"amount": [199.98, 34.99, 149.99, 49.99, 89.99],
"order_date": ["2024-07-05", "2024-08-01", "2024-09-10",
"2024-07-12", "2024-08-20"]
})
print("Customers (customer grain):")
print(customers)
# 3 rows — one per customer
print("\nOrders (order grain):")
print(orders)
# 5 rows — one per order (CUST_001 has 3 orders)
# ── THE BUG: Joining without aggregating first ─────────────────────
# Jane Smith has 3 orders, so she appears 3 times after this join
joined_naive = pd.merge(customers, orders, on="customer_id", how="inner")
print("\nNaive join (WRONG grain — customer fields duplicated per order):")
print(joined_naive[["customer_id", "annual_income", "amount"]])
# The bug in action: "sum of annual income" is nonsensical
wrong_total_income = joined_naive["annual_income"].sum()
print(f"\nWRONG total income: ${wrong_total_income:,.0f}")
# $85,000 × 3 (Jane's rows) + $62,000 + $110,000 = $427,000
# WRONG! Real total should be $85,000 + $62,000 + $110,000 = $257,000
wrong_avg_income = joined_naive["annual_income"].mean()
print(f"WRONG avg income: ${wrong_avg_income:,.0f}")
# Weighted toward CUST_001 because she has 3 rows — not the true customer averageThe correct approaches:
# ── FIX OPTION 1: Aggregate orders first, then join ───────────────
# Bring orders UP to customer grain before joining
order_summary = orders.groupby("customer_id").agg(
num_orders=("order_id", "count"),
total_spend=("amount", "sum"),
avg_order=("amount", "mean"),
first_order=("order_date", "min"),
last_order=("order_date", "max")
).reset_index()
# Now both tables are at customer grain — safe to join
customer_features = pd.merge(customers, order_summary, on="customer_id", how="left")
print("\nCorrect customer-grain table:")
print(customer_features[["customer_id", "annual_income", "num_orders", "total_spend"]])
# Now income calculations are correct
correct_total = customer_features["annual_income"].sum()
correct_avg = customer_features["annual_income"].mean()
print(f"\nCorrect total income: ${correct_total:,.0f}") # $257,000
print(f"Correct avg income: ${correct_avg:,.0f}") # $85,667
# ── FIX OPTION 2: Keep at order grain, only use order-level metrics─
# Never aggregate customer-level attributes in this table
order_analysis = pd.merge(orders, customers[["customer_id", "city"]], on="customer_id")
# Only use columns that make sense at order grain:
# order_id, amount, order_date, customer_id, city
# NEVER: SUM(annual_income) on this table — the grain is wrong for that
revenue_by_city = order_analysis.groupby("city")["amount"].sum()
print("\nRevenue by city (correct — aggregating order-grain metric):")
print(revenue_by_city)The Averaging-of-Averages Bug
A related problem: averaging pre-aggregated averages doesn’t give you the true average.
import pandas as pd
import numpy as np
# Regional summaries (pre-aggregated — regional grain)
regional = pd.DataFrame({
"region": ["East", "West", "Central"],
"avg_order_value": [85.40, 112.30, 67.80],
"num_orders": [12450, 4230, 8900] # Regions have very different volumes!
})
# WRONG: Simple average of regional averages
wrong_overall_avg = regional["avg_order_value"].mean()
print(f"WRONG overall average: ${wrong_overall_avg:.2f}")
# (85.40 + 112.30 + 67.80) / 3 = $88.50
# This ignores that East has 3× more orders than West!
# CORRECT: Weighted average by number of orders
correct_overall_avg = np.average(
regional["avg_order_value"],
weights=regional["num_orders"]
)
print(f"Correct overall average: ${correct_overall_avg:.2f}")
# (85.40×12450 + 112.30×4230 + 67.80×8900) / (12450+4230+8900)
# Or equivalently, always compute from the transaction grain if available:
# transaction_level_df["amount"].mean() # Always correctThe Duplicate-Row Inflation Bug
Sometimes joins produce unexpected duplicates that inflate metrics:
import pandas as pd
# Products: one row per product (product grain)
products = pd.DataFrame({
"product_id": ["PROD_001", "PROD_002", "PROD_003"],
"product_name": ["Headphones", "USB Hub", "Shoes"],
"category": ["Electronics", "Electronics", "Apparel"]
})
# Product tags: one row per product-tag combination (product-tag grain)
product_tags = pd.DataFrame({
"product_id": ["PROD_001", "PROD_001", "PROD_001", "PROD_002", "PROD_003"],
"tag": ["wireless", "premium", "audio", "usb", "running"]
})
print(f"Products: {len(products)} rows")
print(f"Product tags: {len(product_tags)} rows")
# WRONG: Joining product info to tags without thinking about grain change
merged = pd.merge(products, product_tags, on="product_id")
print(f"After merge: {len(merged)} rows")
# 5 rows! PROD_001 now appears 3 times (one per tag)
# Counting products: len(merged) = 5 — WRONG, there are only 3 products
# If you then calculate avg price per category:
merged["price"] = [149.99, 149.99, 149.99, 49.99, 89.99] # Duplicated for tags
wrong_avg = merged.groupby("category")["price"].mean()
print("WRONG avg price (inflated by tags):")
print(wrong_avg)
# Electronics: (149.99 + 149.99 + 149.99 + 49.99) / 4 = 124.99 (too high!)
# CORRECT: Know the grain after the join has changed
# Either: aggregate to get back to product grain
product_grain_back = merged.groupby("product_id").agg(
product_name=("product_name", "first"),
category=("category", "first"),
price=("price", "first"), # De-duplicate
tags=("tag", lambda x: "|".join(x)) # Collect all tags
).reset_index()
print(f"\nBack to product grain: {len(product_grain_back)} rows")Identifying and Verifying the Grain
Before working with any dataset, verify its grain programmatically:
import pandas as pd
def verify_grain(df: pd.DataFrame, key_columns: list, verbose: bool = True) -> dict:
"""
Verify that specified columns form the unique key (grain) of a DataFrame.
Parameters
----------
df : pd.DataFrame
DataFrame to verify.
key_columns : list
Column(s) expected to uniquely identify each row.
verbose : bool
If True, print a detailed report.
Returns
-------
dict
Verification results including whether grain holds and duplicate details.
"""
n_rows = len(df)
n_unique = df[key_columns].drop_duplicates().shape[0]
n_dupes = n_rows - n_unique
grain_holds = n_dupes == 0
if verbose:
print(f"Grain Verification: {key_columns}")
print(f" Total rows: {n_rows:,}")
print(f" Unique keys: {n_unique:,}")
print(f" Duplicates: {n_dupes:,}")
print(f" Grain holds: {'✓ YES' if grain_holds else '✗ NO — DUPLICATES FOUND'}")
if not grain_holds:
# Show the most duplicated keys
dupes = (
df[key_columns]
.value_counts()
.reset_index()
.rename(columns={0: "count"})
.query("count > 1")
.head(5)
)
print(f"\n Most duplicated keys (top 5):")
print(dupes.to_string(index=False))
return {
"grain_holds": grain_holds,
"n_rows": n_rows,
"n_unique": n_unique,
"n_duplicates": n_dupes
}
# Test on our datasets
verify_grain(customers, ["customer_id"])
# Grain Verification: ['customer_id']
# Total rows: 3
# Unique keys: 3
# Grain holds: ✓ YES
verify_grain(orders, ["order_id"])
# Grain holds: ✓ YES
verify_grain(orders, ["customer_id"])
# Grain holds: ✗ NO — DUPLICATES FOUND (CUST_001 appears 3 times)
# Verify composite key
order_items = pd.DataFrame({
"order_id": ["ORD_001", "ORD_001", "ORD_002", "ORD_002"],
"product_id": ["PROD_001", "PROD_002", "PROD_001", "PROD_003"],
"quantity": [1, 2, 3, 1]
})
verify_grain(order_items, ["order_id", "product_id"])
# Grain holds: ✓ YES
verify_grain(order_items, ["order_id"])
# Grain holds: ✗ NO (order_id alone is not unique — need product_id too)Discovering the Grain in an Unknown Dataset
When you receive a dataset without documentation, discover its grain:
import pandas as pd
def discover_grain(df: pd.DataFrame, max_combinations: int = 4) -> list:
"""
Attempt to discover the grain of a DataFrame by finding the minimal
set of columns that uniquely identifies each row.
Tests single columns first, then pairs, then triplets, up to max_combinations.
Parameters
----------
df : pd.DataFrame
DataFrame to analyze.
max_combinations : int
Maximum number of columns to try in combination.
Returns
-------
list
Minimal column combination(s) that form a unique key.
"""
from itertools import combinations
n_rows = len(df)
candidate_keys = []
for n_cols in range(1, min(max_combinations + 1, len(df.columns) + 1)):
for cols in combinations(df.columns, n_cols):
cols = list(cols)
n_unique = df[cols].drop_duplicates().shape[0]
if n_unique == n_rows:
candidate_keys.append(cols)
# Only print the first (smallest) key found
if len(cols) == n_cols:
print(f"✓ Unique key found ({n_cols} column{'s' if n_cols > 1 else ''}): {cols}")
# Stop after finding minimal keys
minimal = [k for k in candidate_keys if len(k) == n_cols]
if minimal and n_cols == 1:
break
elif minimal:
break
if not candidate_keys:
print(f"✗ No unique key found with up to {max_combinations} columns")
print(f" (Dataset may have true duplicate rows)")
return candidate_keys
# Apply to our sample datasets
print("=== Orders table ===")
discover_grain(orders)
# ✓ Unique key found (1 column): ['order_id']
print("\n=== Order items table ===")
discover_grain(order_items)
# ✓ Unique key found (2 columns): ['order_id', 'product_id']Granularity Levels and the Hierarchy
Data typically exists in a natural hierarchy of granularity levels. Understanding this hierarchy helps you know what aggregations are valid and what drill-down paths are available.
Temporal Hierarchy
Second → Minute → Hour → Day → Week → Month → Quarter → Yearimport pandas as pd
import numpy as np
# Start with event-level (finest grain) data
events = pd.DataFrame({
"event_id": range(1, 21),
"timestamp": pd.date_range("2024-09-01", periods=20, freq="6h"),
"user_id": [f"U_{i%5+1:03d}" for i in range(20)],
"event_type": (["purchase", "view", "click"] * 7)[:20],
"amount": np.where(
[et == "purchase" for et in (["purchase", "view", "click"] * 7)[:20]],
np.random.uniform(20, 200, 20),
0.0
)
})
# Aggregate to different temporal grains
daily = events.groupby(events["timestamp"].dt.date).agg(
n_events=("event_id", "count"),
n_users=("user_id", "nunique"),
revenue=("amount", "sum")
).reset_index()
weekly = events.groupby(events["timestamp"].dt.isocalendar().week.astype(int)).agg(
n_events=("event_id", "count"),
revenue=("amount", "sum")
).reset_index()
# Each level of the hierarchy answers different questions:
print("Event grain: 'Which users clicked on product X between 2-3pm yesterday?'")
print("Daily grain: 'How many purchases happened each day this week?'")
print("Weekly grain: 'How did revenue compare week-over-week?'")
print("Monthly grain:'What is our month-over-month user growth?'")Business/Organizational Hierarchy
Individual Transaction → Customer → Segment → Region → Company
Product Variation → Product → Sub-category → Category → Departmentimport pandas as pd
# Geographic hierarchy
transactions = pd.DataFrame({
"txn_id": range(1, 11),
"store_id": [f"STR_{i:03d}" for i in [1,1,2,2,3,3,4,4,5,5]],
"city": ["Austin","Austin","Austin","Austin",
"Seattle","Seattle","Seattle","Seattle",
"Chicago","Chicago"],
"state": ["TX","TX","TX","TX","WA","WA","WA","WA","IL","IL"],
"region": ["South"]*4 + ["West"]*4 + ["Midwest"]*2,
"amount": [120, 85, 200, 45, 150, 300, 75, 90, 110, 220]
})
# Roll up through the geographic hierarchy
city_summary = (
transactions
.groupby(["city", "state", "region"])
.agg(revenue=("amount", "sum"), n_txns=("txn_id", "count"))
.reset_index()
)
state_summary = (
transactions
.groupby(["state", "region"])
.agg(revenue=("amount", "sum"), n_txns=("txn_id", "count"))
.reset_index()
)
region_summary = (
transactions
.groupby("region")
.agg(revenue=("amount", "sum"), n_txns=("txn_id", "count"))
.reset_index()
)
print("City grain:")
print(city_summary)
print("\nState grain:")
print(state_summary)
print("\nRegion grain:")
print(region_summary)Aggregating: Moving Up the Granularity Ladder
Aggregating (rolling up) moves from finer to coarser grain. It always works — you can always summarize detail. The critical question is: which aggregation function is right for each metric?
import pandas as pd
import numpy as np
def aggregate_to_grain(
df: pd.DataFrame,
group_cols: list,
agg_spec: dict
) -> pd.DataFrame:
"""
Aggregate a DataFrame to a coarser grain with validation.
Parameters
----------
df : pd.DataFrame
Source DataFrame (fine grain).
group_cols : list
Columns that define the target (coarser) grain.
agg_spec : dict
Column → aggregation function. Use descriptive function names
that document intent: 'sum', 'mean', 'first', 'nunique', etc.
Returns
-------
pd.DataFrame
Aggregated DataFrame at the target grain.
"""
result = df.groupby(group_cols).agg(agg_spec).reset_index()
print(f"Aggregated: {len(df):,} rows → {len(result):,} rows")
print(f"Grain: {group_cols}")
return resultChoosing the Right Aggregation Function
This is where many errors occur — using the wrong aggregation function for a metric’s type:
| Metric Type | Additive? | Correct Aggregation | Common Mistake |
|---|---|---|---|
| Revenue, count, quantity | Fully additive | SUM | AVG of SUM (loses volume info) |
| Average order value | Semi-additive | Weighted SUM/COUNT | Simple AVG (wrong if groups differ in size) |
| Percentage, ratio | Non-additive | Recompute from numerator/denominator | AVG of percentages (ignores denominators) |
| Max temperature, balance | Semi-additive | MAX or snapshot | SUM (meaningless) |
| Status flags (active/inactive) | Non-additive | MODE or business logic | AVG (produces meaningless float) |
| Distinct count | Non-additive | COUNT DISTINCT (may need HyperLogLog at scale) | SUM of distinct counts (always overcounts) |
import pandas as pd
import numpy as np
# Transaction-grain data
transactions = pd.DataFrame({
"customer_id": ["C1", "C1", "C1", "C2", "C2", "C3"],
"month": ["Jan", "Jan", "Feb", "Jan", "Feb", "Feb"],
"amount": [100, 150, 80, 200, 120, 90],
"conversion": [1, 0, 1, 1, 0, 1], # 1=purchased, 0=visited only
"customer_type": ["premium", "premium", "premium", "standard", "standard", "premium"]
})
# Correct aggregation to customer-month grain
customer_month = transactions.groupby(["customer_id", "month"]).agg(
# Additive: SUM
total_spend = ("amount", "sum"),
n_transactions= ("amount", "count"),
# Average: compute correctly from components
avg_transaction = ("amount", "mean"), # OK here: aggregating raw values
# Ratio: compute from components, not by averaging ratios
total_conversions = ("conversion", "sum"),
total_visits = ("conversion", "count"),
# conversion_rate should be computed AFTER aggregation: total_conversions/total_visits
# Attribute (same for all rows in group): use first
customer_type = ("customer_type", "first")
).reset_index()
customer_month["conversion_rate"] = (
customer_month["total_conversions"] / customer_month["total_visits"]
)
print(customer_month)
# WRONG way to aggregate conversion rate
wrong_agg = transactions.groupby(["customer_id", "month"]).agg(
avg_conversion_rate = ("conversion", "mean") # This IS actually OK for 0/1 variables
# But for pre-aggregated rates (like "60% conversion"), averaging rates is WRONG
).reset_index()
# Demonstrate the pre-aggregated average mistake
regional_rates = pd.DataFrame({
"region": ["East", "West"],
"conversion_rate": [0.60, 0.40], # Pre-aggregated
"n_visitors": [10000, 1000] # Very different volumes
})
wrong_overall = regional_rates["conversion_rate"].mean()
correct_overall = np.average(
regional_rates["conversion_rate"],
weights=regional_rates["n_visitors"]
)
print(f"\nWRONG overall conversion: {wrong_overall:.1%}") # 50.0%
print(f"Correct overall conversion: {correct_overall:.1%}") # 58.2%Fanout Factor: Detecting and Controlling Row Multiplication
When you join datasets and rows multiply unexpectedly, compute the fanout factor to detect and quantify the problem:
import pandas as pd
def join_with_grain_check(
left: pd.DataFrame,
right: pd.DataFrame,
on: str | list,
how: str = "inner",
left_name: str = "left",
right_name: str = "right"
) -> pd.DataFrame:
"""
Perform a join and report the fanout factor to detect row multiplication.
A fanout factor of 1.0 means rows didn't multiply (clean join).
A fanout factor > 1.0 means left rows expanded after joining right.
"""
n_left = len(left)
merged = pd.merge(left, right, on=on, how=how)
n_merged = len(merged)
fanout = n_merged / n_left if n_left > 0 else 0
print(f"\nJoin: {left_name} ({n_left:,} rows) + {right_name}")
print(f"Result: {n_merged:,} rows")
print(f"Fanout factor: {fanout:.2f}×")
if fanout > 1.5:
print(f"⚠️ WARNING: Significant row multiplication detected!")
print(f" Expected one-to-one or one-to-many. Check grain alignment.")
elif fanout > 1.0:
print(f"ℹ️ Row multiplication occurred (one-to-many join)")
else:
print(f"✓ No row multiplication (one-to-one join)")
return merged
# Demonstrate fanout detection
customers_df = pd.DataFrame({
"customer_id": ["C1", "C2", "C3"],
"name": ["Alice", "Bob", "Carol"],
"plan": ["premium", "standard", "premium"]
})
orders_df = pd.DataFrame({
"order_id": ["O1", "O2", "O3", "O4", "O5"],
"customer_id": ["C1", "C1", "C1", "C2", "C3"],
"amount": [100, 200, 150, 75, 300]
})
# This will show fanout factor of 5/3 = 1.67× (Alice has 3 orders)
result = join_with_grain_check(
customers_df, orders_df,
on="customer_id",
left_name="customers"
)Working with Multiple Granularities in One Analysis
Real analyses often need to combine data at different grains. The key is to always be explicit about what grain you’re working at and to aggregate or filter before joining.
import pandas as pd
import numpy as np
# ── Scenario: Customer churn analysis ─────────────────────────────
# We have data at three different grains that need to be combined.
# 1. Customer profile (customer grain)
customers_df = pd.DataFrame({
"customer_id": ["C1", "C2", "C3", "C4", "C5"],
"signup_date": pd.to_datetime(["2022-01-15", "2022-03-20", "2023-06-01",
"2021-11-08", "2023-01-30"]),
"plan": ["premium", "standard", "premium", "standard", "premium"],
"country": ["USA", "USA", "UK", "USA", "CA"]
})
# 2. Monthly activity (customer-month grain)
np.random.seed(42)
months = pd.date_range("2024-01-01", periods=9, freq="ME")
customer_months = pd.DataFrame([
{"customer_id": cid, "month": m,
"n_logins": np.random.poisson(10),
"n_purchases": np.random.poisson(1.5),
"revenue": np.random.uniform(20, 200)}
for cid in customers_df["customer_id"]
for m in months
])
# 3. Support tickets (ticket grain — multiple per customer per month)
tickets = pd.DataFrame({
"ticket_id": range(1, 16),
"customer_id": ["C1","C1","C2","C2","C2","C3","C4","C4","C4","C4","C5","C1","C3","C2","C5"],
"month": pd.to_datetime(
["2024-01-31","2024-03-31","2024-01-31","2024-02-29","2024-04-30",
"2024-02-29","2024-01-31","2024-02-29","2024-03-31","2024-05-31",
"2024-03-31","2024-05-31","2024-04-30","2024-06-30","2024-06-30"]
),
"severity": ["low","high","medium","low","high",
"medium","low","medium","low","high",
"low","medium","high","low","medium"]
})
# ── Step 1: Aggregate tickets to customer-month grain ─────────────
ticket_summary = tickets.groupby(["customer_id", "month"]).agg(
n_tickets = ("ticket_id", "count"),
n_high_severity = ("severity", lambda x: (x == "high").sum()),
has_high_ticket = ("severity", lambda x: int((x == "high").any()))
).reset_index()
# Verify grain
assert ticket_summary[["customer_id", "month"]].duplicated().sum() == 0, \
"Grain violation: customer-month not unique!"
# ── Step 2: Join ticket summary to customer-month activity ────────
# Both are now at customer-month grain — safe to join
activity = pd.merge(
customer_months,
ticket_summary,
on=["customer_id", "month"],
how="left"
).fillna({"n_tickets": 0, "n_high_severity": 0, "has_high_ticket": 0})
# ── Step 3: Aggregate to customer grain ───────────────────────────
# Build one row per customer with features from all months
customer_features = activity.groupby("customer_id").agg(
total_revenue = ("revenue", "sum"),
avg_monthly_revenue= ("revenue", "mean"),
total_purchases = ("n_purchases", "sum"),
avg_monthly_logins = ("n_logins", "mean"),
total_tickets = ("n_tickets", "sum"),
months_with_high_ticket = ("has_high_ticket", "sum"),
last_month_revenue = ("revenue", "last"), # Most recent month
revenue_trend = ("revenue", lambda x: x.iloc[-1] - x.iloc[0])
).reset_index()
# ── Step 4: Join customer profile (also customer grain) ───────────
final_df = pd.merge(customers_df, customer_features, on="customer_id")
final_df["tenure_days"] = (
pd.Timestamp("2024-09-30") - final_df["signup_date"]
).dt.days
print("Final customer-grain feature table:")
print(final_df.columns.tolist())
print(f"Shape: {final_df.shape}")
print(final_df[["customer_id", "plan", "total_revenue",
"total_tickets", "tenure_days"]].head())Granularity in Database Design: The Fact Table Grain
In data warehousing (covered in a later article), granularity is formalized as the grain of the fact table — the central design decision that determines everything else about a dimensional model.
Common fact table grains:
Transaction grain: One row per individual transaction (finest detail)
Daily snapshot: One row per account per day (e.g., bank balances)
Periodic snapshot: One row per entity per period (monthly summaries)
Accumulating snapshot: One row per process instance (e.g., order fulfillment pipeline)The principle: declare the grain first, then determine which dimensions and metrics are consistent with that grain. Every dimension must be at one value per grain instance. Every metric must be meaningful at that grain.
import pandas as pd
# A well-designed fact table at order-item grain
# Grain: one row per line item per order
# Every dimension (customer, product, date, store) has ONE value per row
# Every metric (quantity, unit_price, discount) is meaningful at this level
order_item_fact = pd.DataFrame({
# Grain key
"order_item_id": ["OI_001", "OI_002", "OI_003", "OI_004"],
# Foreign keys to dimension tables (one value per row — correctly grain-compatible)
"order_id": ["ORD_001", "ORD_001", "ORD_002", "ORD_002"],
"product_id": ["P_001", "P_002", "P_001", "P_003"],
"customer_id": ["C_001", "C_001", "C_002", "C_002"],
"order_date": pd.to_datetime(["2024-09-01", "2024-09-01",
"2024-09-03", "2024-09-03"]),
# Metrics (meaningful at item grain)
"quantity": [2, 1, 3, 1],
"unit_price": [149.99, 49.99, 149.99, 89.99],
"discount_pct": [0.10, 0.0, 0.0, 0.05],
"line_total": [269.98, 49.99, 449.97, 85.49]
})
print("Order-item grain fact table:")
print(order_item_fact)
# Verify grain
result = verify_grain(order_item_fact, ["order_item_id"])Practical Checklist: Grain Awareness in Data Science
Use this checklist when receiving a new dataset or designing an analysis:
def grain_analysis_checklist(df: pd.DataFrame, dataset_name: str):
"""
Print a grain analysis checklist for a new dataset.
"""
print(f"\n{'='*60}")
print(f"GRAIN ANALYSIS CHECKLIST: {dataset_name}")
print(f"{'='*60}")
print(f"\n1. SHAPE")
print(f" Rows: {len(df):,} | Columns: {len(df.columns)}")
print(f" Columns: {df.columns.tolist()}")
print(f"\n2. POTENTIAL KEY COLUMNS")
for col in df.columns:
n_unique = df[col].nunique()
pct_unique = n_unique / len(df) * 100
if pct_unique >= 90: # Near-unique columns are likely key candidates
print(f" {col}: {n_unique:,} unique / {len(df):,} rows ({pct_unique:.1f}%)")
print(f"\n3. QUESTIONS TO ANSWER")
questions = [
"What does ONE ROW represent?",
"What combination of columns is unique per row?",
"Are there any duplicate rows?",
"What is the time range / temporal coverage?",
"What level is this data (raw events, daily summary, monthly rollup)?",
"What other tables will this join to, and at what grain?"
]
for i, q in enumerate(questions, 1):
print(f" [{i}] {q}")
print(f"\n4. DUPLICATE CHECK")
n_dupes = df.duplicated().sum()
print(f" Exact duplicate rows: {n_dupes:,} ({'NONE' if n_dupes == 0 else 'FOUND — investigate!'})")
print(f"\n5. NULL RATES")
null_cols = df.isnull().mean()
null_cols = null_cols[null_cols > 0].sort_values(ascending=False)
if len(null_cols) > 0:
print(" Columns with nulls:")
for col, rate in null_cols.items():
print(f" {col}: {rate:.1%} null")
else:
print(" No null values found")
print(f"\n{'='*60}")
# Apply to our dataset
grain_analysis_checklist(orders, "Orders")Summary
Granularity is not a peripheral concept in data science — it is central to every analysis, every join, every aggregation, and every model you build. The grain of a dataset — the precise definition of what one row represents — determines what analyses are valid, what joins are safe, and what aggregation functions preserve meaning.
The most important practical habits to build: always state the grain explicitly when you receive or create a dataset, verify the grain programmatically before performing joins, never join tables at different grains without first aggregating to a common level, and choose aggregation functions that match each metric’s additivity properties — summing revenue is always correct; averaging rates, percentages, and pre-aggregated averages requires careful handling.
When in doubt, work from the finest available grain and aggregate up. You can always discard detail; you can never recover it.
Key Takeaways
- Grain is the precise answer to “what does one row represent?” — it is defined by the combination of columns (the primary or composite key) that makes every row unique, and it determines what analyses, joins, and aggregations are valid
- The fan-out bug — joining a lower-grain table (more rows) to a higher-grain table (fewer rows) without aggregating first — inflates metrics by repeating attribute values once per detail row; always aggregate to a common grain before joining
- Verify grain programmatically:
df[key_cols].duplicated().sum() == 0must be True; if it isn’t, find and resolve the duplicates before proceeding - Fully additive metrics (revenue, count, quantity) can be summed across any dimension; semi-additive metrics (balance, inventory level) can only be summed across some dimensions; non-additive metrics (rates, percentages, distinct counts) cannot be summed and must be recomputed from their components
- Averaging of averages is almost always wrong when group sizes differ — use weighted averages (
np.average(rates, weights=sizes)) or recompute from numerator and denominator separately - The correct direction is always aggregate up from fine to coarse grain — you can discard detail by grouping, but you can never recover detail that wasn’t collected
- In data warehouse design, declaring the grain of the fact table is the first and most important decision — every dimension must have exactly one value per grain instance, and every metric must be meaningful at that level
- When receiving an unknown dataset, always run a grain discovery analysis: check which column combinations produce unique rows, look for unexpected duplicates, and document the grain before writing any analysis code






