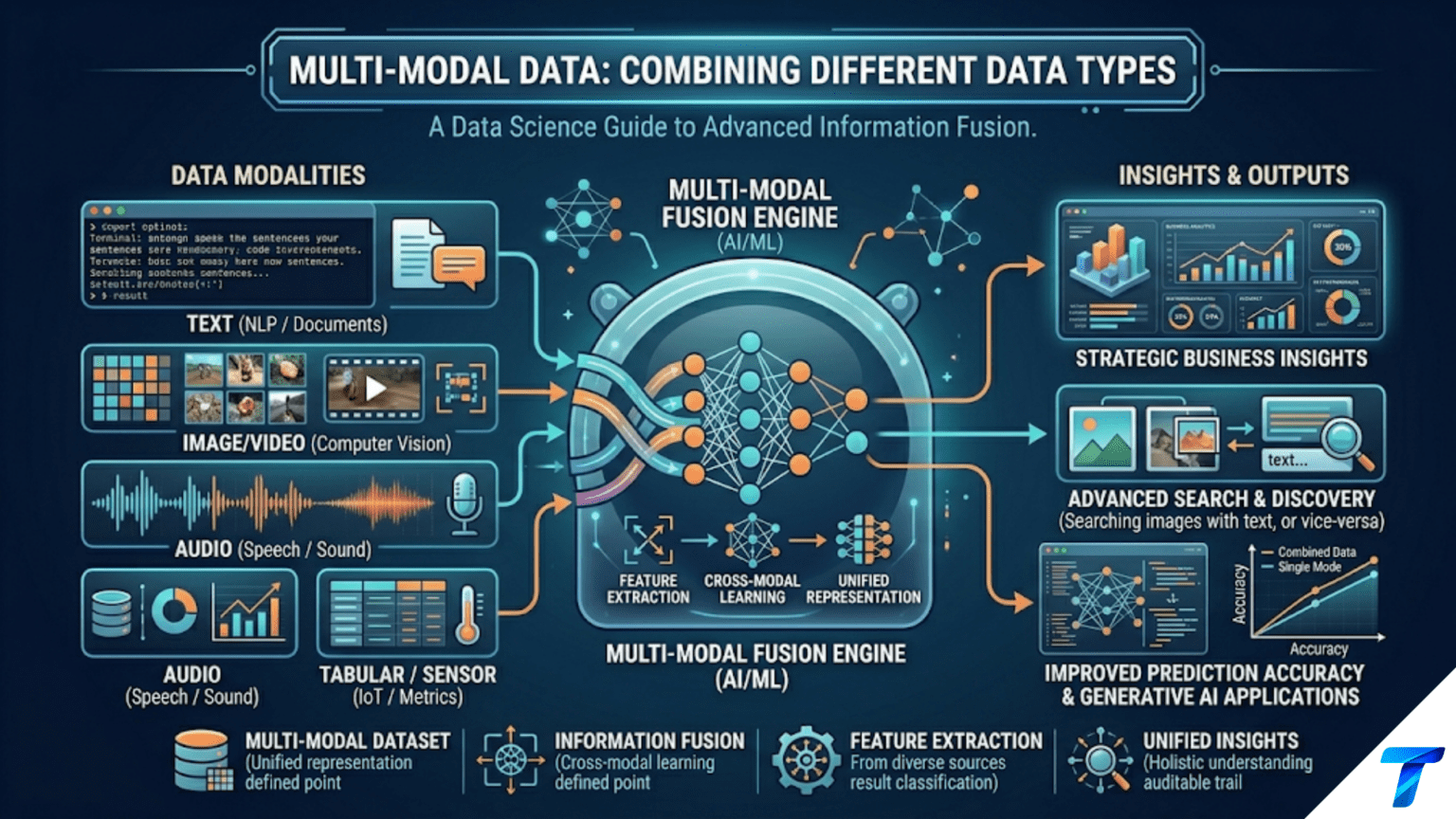
Multi-modal data combines two or more fundamentally different data types (tabular features alongside images, text with structured metadata, or video with audio) to produce richer analytical representations than any single modality provides alone. The core pattern in multi-modal machine learning is feature fusion: extract a fixed-length feature vector from each modality independently (CNN features from images, TF-IDF or embeddings from text, engineered features from tabular data), then concatenate those vectors and train a single model on the combined representation. This approach is practical, interpretable, and works well even without specialized multi-modal architectures.
Introduction
Real-world data rarely arrives in a single format. An e-commerce product listing has a title (text), description (text), category (categorical), price (numeric), and product photos (images). A customer support ticket has the complaint text, customer demographic data, previous interaction history, and sometimes a screenshot. A medical patient record combines structured clinical measurements, free-text physician notes, diagnostic images (X-rays, MRIs), and lab results as time-series.
Each modality carries information that the others don’t. For a product quality classifier, the product image reveals visible defects that the product description might not mention. For a loan default predictor, the applicant’s free-text responses reveal risk signals that structured financial metrics miss. For a disease diagnosis model, the MRI image reveals pathology while the clinical notes provide symptom context and the lab values provide objective biomarkers. Combining modalities consistently improves predictive performance — often substantially.
Yet most data science practice treats modalities separately. The tabular analyst builds a model on structured features. The NLP engineer builds a model on text. The computer vision engineer builds a model on images. Multi-modal data science integrates these into a unified pipeline where the full richness of available information is exploited.
This article provides a practical framework for multi-modal data science: the three fusion strategies (early, late, and joint), how to implement each in Python with scikit-learn and PyTorch, the practical challenges of aligning and normalizing different modalities, and worked examples across common multi-modal combinations. This is the final article in the Working with Data section — a synthesis that draws on everything covered in articles 71–94.
What Is Multi-Modal Data?
A modality is a fundamentally different type of data requiring different processing techniques to extract useful features. The five modalities covered in this section of the book:
| Modality | Article | Representation | Key Feature Extraction |
|---|---|---|---|
| Tabular / Structured | 71–89 | Rows and columns | Raw features, engineering |
| Text | 91 | Sequence of tokens | TF-IDF, embeddings, BERT |
| Image | 92 | Pixel array (H×W×C) | CNN features, histograms |
| Audio | 93 | Waveform + spectrogram | MFCCs, spectral features |
| Video | 94 | Frame sequences | Per-frame CNN + motion |
Multi-modal learning is not about changing the fundamental representation — it’s about extracting features from each modality in isolation, then combining those features for the downstream task.
Why Multi-Modal Often Beats Single-Modal
import numpy as np
# A simple intuition: two imperfect predictors combined can outperform either alone
np.random.seed(42)
n = 1000
# True labels
true_labels = np.random.randint(0, 2, n)
# Modality A: 75% accurate
pred_a = true_labels.copy()
errors_a = np.random.choice(n, int(n * 0.25), replace=False)
pred_a[errors_a] = 1 - pred_a[errors_a]
# Modality B: 72% accurate, with DIFFERENT errors (complementary information)
pred_b = true_labels.copy()
# Different error indices — the two modalities fail on different examples
errors_b = np.random.choice(n, int(n * 0.28), replace=False)
pred_b[errors_b] = 1 - pred_b[errors_b]
acc_a = (pred_a == true_labels).mean()
acc_b = (pred_b == true_labels).mean()
# Simple majority vote (multi-modal combination)
combined = ((pred_a + pred_b) >= 1).astype(int)
acc_combined = (combined == true_labels).mean()
print(f"Modality A accuracy: {acc_a:.3f}")
print(f"Modality B accuracy: {acc_b:.3f}")
print(f"Combined accuracy: {acc_combined:.3f}") # Often notably higher
print(f"\nGain from combination: {(acc_combined - max(acc_a, acc_b)):.3f}")The combination gains more when the two modalities make errors on different examples — that is, when they carry complementary rather than redundant information. The first question to ask about any multi-modal combination is: are these modalities actually complementary, or are they mostly measuring the same underlying signal?
The Three Fusion Strategies
Strategy 1: Early Fusion (Feature Concatenation)
The simplest and most common approach: extract features from each modality independently, concatenate them into one vector, and train a single model on the combined representation.
Text → [TF-IDF features] → 500-dim vector ───┐
Image → [CNN features] → 2048-dim vector ────┼──► concat → 2598-dim → LogisticRegression
Tabular → [engineered] → 50-dim vector ──────┘Advantages: Simple, interpretable, compatible with any sklearn estimator, fast to train. Disadvantages: The concatenated feature space can be very high-dimensional; modalities with more features may dominate; no mechanism for the modalities to interact.
Strategy 2: Late Fusion (Ensemble of Predictions)
Train a separate model for each modality, then combine their predictions.
Text → TextModel → P(class | text) ───────────┐
Image → ImageModel → P(class | image) ────────┼──► combine → final prediction
Tabular → TabularModel → P(class | tabular) ──┘Advantages: Each modality model can be optimized independently; robust to one modality being unavailable; naturally handles the case where modalities have different amounts of data. Disadvantages: Doesn’t allow cross-modal interactions at the feature level.
Strategy 3: Joint/Intermediate Fusion (Neural Network)
A neural network learns to combine modality-specific learned representations in a shared latent space.
Text → BERT encoder → 768-dim embedding ─────────┐
Image → ViT/CNN encoder → 768-dim embedding ─────┼──► cross-attention / concat → final prediction
Tabular → MLP → 256-dim embedding ───────────────┘
Advantages: Can learn rich cross-modal interactions; state of the art for many tasks. Disadvantages: Requires more data, more compute, more engineering, harder to debug.
For most practical data science work, start with early fusion. It handles 80% of use cases with 20% of the complexity. The rest of this article covers early and late fusion in detail.
Building a Multi-Modal Feature Matrix
The core task is extracting feature vectors from each modality and assembling them into a unified matrix:
import numpy as np
import pandas as pd
from sklearn.preprocessing import StandardScaler
from typing import Optional
class MultiModalFeatureExtractor:
"""
Orchestrates feature extraction from multiple data modalities
and assembles them into a single unified feature matrix.
Supports tabular, text, image, and audio modalities.
Each modality's features are extracted independently,
then concatenated for downstream ML.
"""
def __init__(self, modalities: list, scale_each: bool = True):
"""
Parameters
----------
modalities : list
List of modality names to include: any subset of
['tabular', 'text', 'image', 'audio'].
scale_each : bool
If True, StandardScaler is fit-transformed per modality
before concatenation. Prevents high-dimensional modalities
from numerically dominating lower-dimensional ones.
"""
self.modalities = modalities
self.scale_each = scale_each
self.scalers = {}
self.feature_dims = {}
def _extract_tabular(self, df: pd.DataFrame,
numeric_cols: list,
categorical_cols: list = None) -> np.ndarray:
"""Extract and encode tabular features."""
from sklearn.preprocessing import OrdinalEncoder
features = []
# Numeric features
if numeric_cols:
numeric = df[numeric_cols].fillna(0).values.astype(np.float32)
features.append(numeric)
# Categorical features (ordinal encoding for simplicity)
if categorical_cols:
enc = OrdinalEncoder(handle_unknown="use_encoded_value", unknown_value=-1)
cats = enc.fit_transform(df[categorical_cols].fillna("unknown"))
features.append(cats)
return np.hstack(features) if features else np.zeros((len(df), 0))
def _extract_text(self, texts: pd.Series,
method: str = "tfidf",
max_features: int = 500) -> np.ndarray:
"""Extract text features using TF-IDF or sentence embeddings."""
if method == "tfidf":
from sklearn.feature_extraction.text import TfidfVectorizer
vec = TfidfVectorizer(
max_features=max_features,
sublinear_tf=True,
ngram_range=(1, 2),
stop_words="english"
)
return vec.fit_transform(texts.fillna("")).toarray().astype(np.float32)
elif method == "sentence_transformer":
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("all-MiniLM-L6-v2")
return model.encode(
texts.fillna("").tolist(),
show_progress_bar=True,
batch_size=32
)
else:
raise ValueError(f"Unknown text method: {method}")
def _extract_image(self, image_paths: pd.Series,
model_name: str = "resnet18") -> np.ndarray:
"""Extract CNN features from image files."""
import torch
import torchvision.models as models
import torchvision.transforms as transforms
from PIL import Image
model = models.resnet18(weights=models.ResNet18_Weights.IMAGENET1K_V1)
model = torch.nn.Sequential(*list(model.children())[:-1])
model.eval()
transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
features = []
for path in image_paths:
try:
img = Image.open(str(path)).convert("RGB")
tensor = transform(img).unsqueeze(0)
with torch.no_grad():
feat = model(tensor).squeeze().numpy()
features.append(feat)
except Exception:
# Missing image → zero vector
features.append(np.zeros(512, dtype=np.float32))
return np.array(features, dtype=np.float32)
def _extract_audio(self, audio_paths: pd.Series, sr: int = 22050) -> np.ndarray:
"""Extract MFCC-based features from audio files."""
import librosa
def extract_single(filepath):
try:
y, _ = librosa.load(str(filepath), sr=sr, duration=10.0)
mfcc = librosa.feature.mfcc(y=y, sr=sr, n_mfcc=13)
d1 = librosa.feature.delta(mfcc)
d2 = librosa.feature.delta(mfcc, order=2)
feats = np.vstack([mfcc, d1, d2])
return np.hstack([feats.mean(axis=1), feats.std(axis=1)])
except Exception:
return np.zeros(78, dtype=np.float32) # 13×3×2 = 78
return np.array([extract_single(p) for p in audio_paths], dtype=np.float32)
def fit_transform(
self,
df: pd.DataFrame,
text_col: str = None,
text_method: str = "tfidf",
image_col: str = None,
audio_col: str = None,
numeric_cols: list = None,
categorical_cols: list = None
) -> np.ndarray:
"""
Extract features from all modalities and concatenate.
Parameters
----------
df : pd.DataFrame
DataFrame containing all data. Each row is one sample.
text_col : str, optional
Column name with text content.
text_method : str
'tfidf' or 'sentence_transformer'.
image_col : str, optional
Column name with image file paths.
audio_col : str, optional
Column name with audio file paths.
numeric_cols : list, optional
Numeric columns for tabular features.
categorical_cols : list, optional
Categorical columns for tabular features.
Returns
-------
np.ndarray
Concatenated feature matrix (n_samples, total_features).
"""
all_features = []
n = len(df)
if "tabular" in self.modalities and (numeric_cols or categorical_cols):
print("Extracting tabular features...")
tab_feats = self._extract_tabular(
df, numeric_cols or [], categorical_cols
)
if self.scale_each:
scaler = StandardScaler()
tab_feats = scaler.fit_transform(tab_feats)
self.scalers["tabular"] = scaler
self.feature_dims["tabular"] = tab_feats.shape[1]
all_features.append(tab_feats)
print(f" Tabular features: {tab_feats.shape}")
if "text" in self.modalities and text_col:
print("Extracting text features...")
text_feats = self._extract_text(df[text_col], method=text_method)
if self.scale_each and text_method != "sentence_transformer":
scaler = StandardScaler()
text_feats = scaler.fit_transform(text_feats)
self.scalers["text"] = scaler
self.feature_dims["text"] = text_feats.shape[1]
all_features.append(text_feats)
print(f" Text features: {text_feats.shape}")
if "image" in self.modalities and image_col:
print("Extracting image features...")
image_feats = self._extract_image(df[image_col])
if self.scale_each:
scaler = StandardScaler()
image_feats = scaler.fit_transform(image_feats)
self.scalers["image"] = scaler
self.feature_dims["image"] = image_feats.shape[1]
all_features.append(image_feats)
print(f" Image features: {image_feats.shape}")
if "audio" in self.modalities and audio_col:
print("Extracting audio features...")
audio_feats = self._extract_audio(df[audio_col])
if self.scale_each:
scaler = StandardScaler()
audio_feats = scaler.fit_transform(audio_feats)
self.scalers["audio"] = scaler
self.feature_dims["audio"] = audio_feats.shape[1]
all_features.append(audio_feats)
print(f" Audio features: {audio_feats.shape}")
combined = np.hstack(all_features)
print(f"\nFinal combined feature matrix: {combined.shape}")
print("Feature dimensions by modality:")
for modality, dim in self.feature_dims.items():
pct = dim / combined.shape[1] * 100
print(f" {modality:15s}: {dim:5d} features ({pct:.1f}% of total)")
return combinedCase Study 1: Product Classification (Text + Image + Tabular)
An e-commerce product classifier that uses product title and description (text), product photo (image), and structured attributes like price and category hints (tabular):
import numpy as np
import pandas as pd
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import cross_val_score, StratifiedKFold
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler, LabelEncoder
# Synthetic dataset: 200 products across 4 categories
np.random.seed(42)
n_products = 200
categories = ["electronics", "clothing", "books", "kitchen"]
product_data = pd.DataFrame({
"product_id": [f"P{i:04d}" for i in range(n_products)],
"title": [
# Generate synthetic titles by category
np.random.choice([
"wireless bluetooth headphones premium quality",
"laptop stand adjustable aluminum computer desk",
"usb c hub multiport adapter 7-in-1",
"fitted t-shirt cotton blend comfortable wear",
"running shoes lightweight breathable athletic",
"winter jacket waterproof insulated warm",
"data science handbook practical machine learning",
"python programming beginner guide complete",
"fiction novel bestselling thriller mystery",
"coffee maker programmable 12-cup stainless",
"chef knife 8-inch high carbon stainless steel",
"silicone spatula heat-resistant kitchen tool"
])
for _ in range(n_products)
],
"price": np.random.lognormal(3.5, 1.0, n_products),
"weight_kg": np.random.lognormal(0.0, 0.8, n_products),
"has_warranty": np.random.randint(0, 2, n_products),
"rating": np.random.uniform(3.0, 5.0, n_products),
"n_reviews": np.random.lognormal(4.0, 1.5, n_products).astype(int),
"category": np.random.choice(categories, n_products)
})
le = LabelEncoder()
y = le.fit_transform(product_data["category"])
print(f"Dataset: {n_products} products, {len(categories)} categories")
print(f"Class distribution: {pd.Series(le.inverse_transform(y)).value_counts().to_dict()}")
def build_and_evaluate_classifiers(
X_combined: np.ndarray,
X_text: np.ndarray,
X_tabular: np.ndarray,
y: np.ndarray,
n_folds: int = 5
) -> pd.DataFrame:
"""
Compare single-modality vs. multi-modal classifiers.
Evaluates:
1. Text-only
2. Tabular-only
3. Early fusion (concat)
4. Late fusion (ensemble of predictions)
"""
cv = StratifiedKFold(n_splits=n_folds, shuffle=True, random_state=42)
results = []
def evaluate(X, name):
scores = cross_val_score(
Pipeline([("scaler", StandardScaler()),
("clf", LogisticRegression(C=1.0, max_iter=500,
random_state=42))]),
X, y, cv=cv, scoring="accuracy", n_jobs=-1
)
return {"model": name, "cv_accuracy": scores.mean(),
"cv_std": scores.std()}
# Single modality
results.append(evaluate(X_text, "Text only"))
results.append(evaluate(X_tabular, "Tabular only"))
# Early fusion: concatenate all features
results.append(evaluate(X_combined, "Early fusion (concat)"))
# Late fusion: train individual models, average probabilities
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import cross_val_predict
text_probs = cross_val_predict(
Pipeline([("sc", StandardScaler()),
("lr", LogisticRegression(C=1.0, max_iter=500, random_state=42))]),
X_text, y, cv=cv, method="predict_proba"
)
tab_probs = cross_val_predict(
Pipeline([("sc", StandardScaler()),
("lr", LogisticRegression(C=1.0, max_iter=500, random_state=42))]),
X_tabular, y, cv=cv, method="predict_proba"
)
# Average probabilities and take argmax
combined_probs = (text_probs + tab_probs) / 2
late_fusion_acc = (combined_probs.argmax(axis=1) == y).mean()
results.append({
"model": "Late fusion (avg probs)",
"cv_accuracy": late_fusion_acc,
"cv_std": 0.0
})
df_results = pd.DataFrame(results).sort_values("cv_accuracy", ascending=False)
print("\nClassifier Comparison:")
print(df_results.to_string(index=False))
return df_resultsCase Study 2: Customer Support Ticket Triage (Text + Tabular)
Classifying support ticket priority using ticket text and structured customer/account metadata:
import numpy as np
import pandas as pd
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from scipy.sparse import hstack, csr_matrix
# Synthetic support ticket data
np.random.seed(42)
n_tickets = 500
ticket_texts = [
"cannot login getting error 403 access denied tried multiple browsers",
"payment failed charged twice on my credit card please refund",
"how do i change my password reset link not working",
"app crashes immediately on startup after latest update",
"billing question about invoice discrepancy for last month",
"feature request can you add dark mode to the dashboard",
"urgent server down affecting all users production environment",
"general question about pricing plans for enterprise",
"data not syncing between devices for past three days",
"account locked out need immediate assistance for demo tomorrow"
]
ticket_data = pd.DataFrame({
"ticket_id": [f"T{i:04d}" for i in range(n_tickets)],
"text": [np.random.choice(ticket_texts) for _ in range(n_tickets)],
"customer_tier": np.random.choice(["enterprise", "business", "starter", "free"],
n_tickets, p=[0.1, 0.2, 0.3, 0.4]),
"account_age_days":np.random.exponential(365, n_tickets).astype(int),
"open_tickets": np.random.randint(0, 10, n_tickets),
"arr_usd": np.random.lognormal(8.0, 2.0, n_tickets),
"prev_escalations":np.random.poisson(0.5, n_tickets),
"priority": np.random.choice(["low", "medium", "high", "critical"],
n_tickets, p=[0.35, 0.35, 0.20, 0.10])
})
# Encode target
priority_map = {"low": 0, "medium": 1, "high": 2, "critical": 3}
y = ticket_data["priority"].map(priority_map).values
# ── Feature extraction ────────────────────────────────────────────
# Text features (sparse TF-IDF)
tfidf = TfidfVectorizer(max_features=1000, ngram_range=(1, 2), sublinear_tf=True)
X_text = tfidf.fit_transform(ticket_data["text"])
# Tabular features
from sklearn.preprocessing import OrdinalEncoder
tier_encoder = OrdinalEncoder(categories=[["free", "starter", "business", "enterprise"]])
tier_encoded = tier_encoder.fit_transform(ticket_data[["customer_tier"]])
tabular_features = np.hstack([
tier_encoded,
ticket_data[["account_age_days", "open_tickets",
"arr_usd", "prev_escalations"]].values
])
scaler = StandardScaler()
X_tabular_scaled = scaler.fit_transform(tabular_features)
# Combine: sparse TF-IDF + dense tabular
# scipy.sparse.hstack handles mixed sparse/dense if we convert dense to sparse
X_tabular_sparse = csr_matrix(X_tabular_scaled)
X_combined = hstack([X_text, X_tabular_sparse])
# ── Train and evaluate ────────────────────────────────────────────
X_train, X_test, y_train, y_test = train_test_split(
X_combined, y, test_size=0.2, stratify=y, random_state=42
)
clf = LogisticRegression(C=1.0, max_iter=500, random_state=42,
multi_class="auto")
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
priority_names = ["low", "medium", "high", "critical"]
print("Support Ticket Triage — Multi-Modal Results:")
print(classification_report(y_test, y_pred, target_names=priority_names))
# Compare with text-only
clf_text = LogisticRegression(C=1.0, max_iter=500, random_state=42)
X_train_text, X_test_text = X_text[:400], X_text[400:]
clf_text.fit(X_train_text, y_train)
acc_text = (clf_text.predict(X_test_text) == y_test).mean()
acc_combined = (y_pred == y_test).mean()
print(f"\nText-only accuracy: {acc_text:.3f}")
print(f"Multi-modal accuracy: {acc_combined:.3f}")
print(f"Gain from adding tabular metadata: {acc_combined - acc_text:+.3f}")Late Fusion: When to Use It and How
Late fusion is the right choice when:
- Modalities have very different amounts of available data
- One modality might be missing at inference time
- Existing single-modal models already exist and shouldn’t be retrained
- Explainability is important (each modality’s contribution is visible)
import numpy as np
from sklearn.base import BaseEstimator, ClassifierMixin
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import Pipeline
class LateFusionClassifier(BaseEstimator, ClassifierMixin):
"""
Late fusion classifier: trains a model per modality,
combines predictions using learnable weights or averaging.
Handles missing modalities at inference time by using
only available modalities' predictions.
"""
def __init__(self, combination: str = "average", weights: list = None):
"""
Parameters
----------
combination : str
'average': equal-weight average of probabilities.
'weighted': weighted average using weights parameter.
'learned': trains a meta-classifier on out-of-fold predictions.
weights : list, optional
Per-modality weights (for 'weighted' combination).
"""
self.combination = combination
self.weights = weights
self.models_ = {}
self.classes_ = None
def fit(self, X_dict: dict, y: np.ndarray) -> "LateFusionClassifier":
"""
Train a separate model for each modality.
Parameters
----------
X_dict : dict
{modality_name: feature_matrix} for each modality.
y : np.ndarray
Target labels.
"""
import numpy as np
from sklearn.model_selection import cross_val_predict
self.classes_ = np.unique(y)
for modality_name, X in X_dict.items():
model = Pipeline([
("scaler", StandardScaler()),
("lr", LogisticRegression(C=1.0, max_iter=500, random_state=42))
])
model.fit(X, y)
self.models_[modality_name] = model
train_acc = model.score(X, y)
print(f" Trained {modality_name}: train accuracy = {train_acc:.3f}")
if self.combination == "learned":
# Train a meta-classifier on out-of-fold probability predictions
from sklearn.model_selection import cross_val_predict, StratifiedKFold
cv = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)
meta_features = []
for modality_name, X in X_dict.items():
oof_probs = cross_val_predict(
Pipeline([("scaler", StandardScaler()),
("lr", LogisticRegression(C=1.0, max_iter=500))]),
X, y, cv=cv, method="predict_proba"
)
meta_features.append(oof_probs)
X_meta = np.hstack(meta_features)
self.meta_clf_ = LogisticRegression(C=1.0, max_iter=200, random_state=42)
self.meta_clf_.fit(X_meta, y)
return self
def predict_proba(self, X_dict: dict) -> np.ndarray:
"""
Combine modality predictions. Handles missing modalities.
"""
modality_probs = {}
for modality_name, model in self.models_.items():
if modality_name in X_dict and X_dict[modality_name] is not None:
modality_probs[modality_name] = model.predict_proba(X_dict[modality_name])
if not modality_probs:
raise ValueError("No modality data provided for prediction")
prob_arrays = list(modality_probs.values())
if self.combination == "average":
return np.mean(prob_arrays, axis=0)
elif self.combination == "weighted":
if not self.weights:
raise ValueError("weights must be provided for 'weighted' combination")
modality_names = list(modality_probs.keys())
weight_array = np.array([self.weights[list(self.models_.keys()).index(n)]
for n in modality_names])
weight_array = weight_array / weight_array.sum()
return sum(w * p for w, p in zip(weight_array, prob_arrays))
elif self.combination == "learned":
X_meta = np.hstack(prob_arrays)
return self.meta_clf_.predict_proba(X_meta)
def predict(self, X_dict: dict) -> np.ndarray:
proba = self.predict_proba(X_dict)
return self.classes_[proba.argmax(axis=1)]Handling Missing Modalities
Real-world multi-modal datasets frequently have missing data for one or more modalities. Strategies:
import numpy as np
import pandas as pd
from sklearn.impute import SimpleImputer
def handle_missing_modality(
features: np.ndarray,
missing_mask: np.ndarray,
strategy: str = "zero",
imputer = None
) -> np.ndarray:
"""
Handle rows where a modality is missing.
Parameters
----------
features : np.ndarray
Feature matrix (N, D) with placeholder values for missing rows.
missing_mask : np.ndarray
Boolean array where True = this row has no data for this modality.
strategy : str
'zero': Fill with zero vector (treats absence as neutral).
'mean': Fill with mean of available samples.
'remove': Return only rows with complete data (careful about set sizes).
'flag': Add a binary feature indicating modality was missing.
imputer :
Pre-fitted imputer (for test time consistency).
Returns
-------
np.ndarray
Features with missing values handled.
"""
features = features.copy()
if strategy == "zero":
features[missing_mask] = 0.0
elif strategy == "mean":
if imputer is None:
imputer = SimpleImputer(strategy="mean")
# Only fit on available rows
features[missing_mask] = np.nan
features = imputer.fit_transform(features)
else:
features[missing_mask] = np.nan
features = imputer.transform(features)
elif strategy == "flag":
# Add a binary flag column indicating modality was missing
flag_col = missing_mask.astype(float).reshape(-1, 1)
features[missing_mask] = 0.0
features = np.hstack([features, flag_col])
return features
# Simulate a dataset where some records have no image
n_samples = 1000
text_features = np.random.randn(n_samples, 500) # Always available
image_features = np.random.randn(n_samples, 512) # 20% missing
tabular_features = np.random.randn(n_samples, 50) # Always available
# 20% of samples have no image
has_image = np.random.rand(n_samples) > 0.20
missing_image = ~has_image
print(f"Samples with image: {has_image.sum():,} ({has_image.mean():.1%})")
print(f"Samples without image: {missing_image.sum():,} ({missing_image.mean():.1%})")
# Strategy 1: Zero-fill missing images (simplest)
image_zero_filled = handle_missing_modality(
image_features, missing_image, strategy="zero"
)
# Strategy 2: Add a "has_image" flag feature
image_with_flag = handle_missing_modality(
image_features, missing_image, strategy="flag"
)
print(f"\nWith flag strategy: {image_with_flag.shape[1]} image features "
f"(512 + 1 flag)")
# Combine with flag indicating modality availability
X_combined = np.hstack([
text_features,
image_zero_filled,
image_with_flag[:, -1:], # Just the flag column
tabular_features
])
print(f"Combined features: {X_combined.shape}")Practical Considerations
Feature Dimension Imbalance
When one modality has far more features than another, it can dominate the model:
import numpy as np
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
def balance_modality_dimensions(
feature_dict: dict,
target_dim: int = 100
) -> dict:
"""
Reduce each modality's features to a common dimensionality.
Prevents high-dimensional modalities from dominating.
"""
balanced = {}
for modality_name, features in feature_dict.items():
current_dim = features.shape[1]
if current_dim > target_dim:
# Reduce with PCA
pca = PCA(n_components=target_dim, random_state=42)
scaler = StandardScaler()
balanced[modality_name] = pca.fit_transform(
scaler.fit_transform(features)
)
print(f" {modality_name}: {current_dim} → {target_dim} dims (PCA)")
else:
balanced[modality_name] = features
print(f" {modality_name}: {current_dim} dims (unchanged)")
return balanced
# Example: text has 1000 features, image has 2048, tabular has 15
feature_dict = {
"text": np.random.randn(500, 1000),
"image": np.random.randn(500, 2048),
"tabular": np.random.randn(500, 15)
}
balanced = balance_modality_dimensions(feature_dict, target_dim=100)
# All modalities now have 100 dimensions (or fewer if original was smaller)
combined = np.hstack(list(balanced.values()))
print(f"\nBalanced combined: {combined.shape}") # (500, 300)Cross-Modal Correlation Analysis
Before building a multi-modal model, it’s worth understanding how much information the modalities share:
import numpy as np
from sklearn.cross_decomposition import CCA
from scipy.stats import pearsonr
def analyze_cross_modal_correlation(
features_a: np.ndarray,
features_b: np.ndarray,
labels: np.ndarray,
modality_a_name: str = "Modality A",
modality_b_name: str = "Modality B"
) -> dict:
"""
Analyze information overlap between two modalities.
High overlap → modalities are redundant.
Low overlap → modalities are complementary (good for fusion).
"""
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import cross_val_score
# 1. Predictive power comparison
cv_a = cross_val_score(
LogisticRegression(C=1.0, max_iter=500, random_state=42),
StandardScaler().fit_transform(features_a),
labels, cv=5, scoring="accuracy"
)
cv_b = cross_val_score(
LogisticRegression(C=1.0, max_iter=500, random_state=42),
StandardScaler().fit_transform(features_b),
labels, cv=5, scoring="accuracy"
)
cv_combined = cross_val_score(
LogisticRegression(C=1.0, max_iter=500, random_state=42),
np.hstack([StandardScaler().fit_transform(features_a),
StandardScaler().fit_transform(features_b)]),
labels, cv=5, scoring="accuracy"
)
# 2. Complementarity score:
# If combined >> max(A, B), modalities are complementary
max_single = max(cv_a.mean(), cv_b.mean())
gain = cv_combined.mean() - max_single
print(f"\nCross-Modal Correlation Analysis:")
print(f" {modality_a_name} accuracy: {cv_a.mean():.3f} ± {cv_a.std():.3f}")
print(f" {modality_b_name} accuracy: {cv_b.mean():.3f} ± {cv_b.std():.3f}")
print(f" Combined accuracy: {cv_combined.mean():.3f} ± {cv_combined.std():.3f}")
print(f" Fusion gain: {gain:+.3f}")
if gain > 0.05:
print(" → HIGH complementarity: fusion strongly recommended")
elif gain > 0.01:
print(" → MODERATE complementarity: fusion likely beneficial")
else:
print(" → LOW complementarity: modalities may carry redundant information")
return {
"acc_a": cv_a.mean(), "acc_b": cv_b.mean(),
"acc_combined": cv_combined.mean(),
"fusion_gain": gain
}Multi-Modal Embeddings: The Joint Space Approach
Modern approaches like CLIP (Contrastive Language-Image Pre-training) embed different modalities into a shared vector space where semantically similar cross-modal content has similar vectors:
# CLIP: embedding images and text in the same space
# pip install git+https://github.com/openai/CLIP.git
# or: from transformers import CLIPProcessor, CLIPModel
from transformers import CLIPProcessor, CLIPModel
import torch
from PIL import Image
import numpy as np
def compute_clip_similarity(image_path: str, texts: list) -> np.ndarray:
"""
Compute similarity between an image and a list of text descriptions
using CLIP's shared embedding space.
Returns similarity scores for each text.
"""
model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")
processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
image = Image.open(image_path).convert("RGB")
# Process both image and texts
inputs = processor(
text=texts,
images=image,
return_tensors="pt",
padding=True
)
with torch.no_grad():
outputs = model(**inputs)
# Image-text similarity scores (logits)
logits_per_image = outputs.logits_per_image # (1, n_texts)
probs = logits_per_image.softmax(dim=1).numpy()[0]
for text, prob in zip(texts, probs):
print(f" {prob:.3f}: {text}")
return probs
# Example: classify a product image using text labels
# probs = compute_clip_similarity(
# "product_photo.jpg",
# texts=[
# "an electronic device or gadget",
# "clothing or fashion item",
# "a book or printed material",
# "kitchen appliance or cookware"
# ]
# )
# predicted_class = texts[probs.argmax()]Summary
Multi-modal data science is not a separate discipline — it is the natural evolution of applying data science skills to the full richness of real-world data. The core pattern — extract features from each modality independently, concatenate, train — is simple enough to implement in an afternoon and powerful enough to unlock significant performance gains on most multi-modal problems.
The practical hierarchy: start with early fusion (feature concatenation) as the baseline, because it’s simple, debuggable, and often achieves 80–90% of the performance of more sophisticated approaches. If early fusion isn’t adequate, consider late fusion (separate models with combined predictions) when modalities have very different reliability or sample availability, or joint fusion (shared neural network) when you have large labeled datasets and compute to spare.
The most important practical considerations are: ensure modalities are aligned (same sample corresponds to the same row in all modality matrices), handle missing modalities explicitly (zero-fill or flag), balance feature dimensions so no single modality overwhelms the others, and always compare against single-modality baselines to verify the fusion actually helps.
Multi-modal data science closes the loop on the entire “Working with Data” section: having learned to work with each data type individually — structured data, text, images, audio, and video — you’re now equipped to combine them for the analyses and models that most closely reflect the complexity of the real world.
Key Takeaways
- Multi-modal learning combines features from different data types (text, image, audio, tabular) to capture information that no single modality provides alone — the gain is largest when modalities are complementary (make different errors) rather than redundant (measure the same underlying signal)
- Early fusion (extract features from each modality independently → concatenate → train one model) is the recommended starting point: simple, interpretable, works with any sklearn estimator, and achieves most of the performance gain with minimal complexity
- Late fusion (train one model per modality → combine predictions) is better when modalities have different data availability, when one modality may be missing at inference time, or when per-modality interpretability is required
- Always scale each modality independently before concatenation (fit a
StandardScalerper modality) — this prevents high-dimensional modalities like TF-IDF (1000 features) from numerically dominating lower-dimensional ones like tabular (20 features) - Handle missing modalities explicitly: zero-fill missing data with a binary “modality_available” flag column is a simple and effective strategy that lets the model learn when data is absent
- Always measure fusion gain by comparing multi-modal accuracy against each single-modality baseline — if the gain is minimal (< 1-2%), the modalities may carry redundant information and fusion adds complexity without benefit
- Modern models like CLIP embed images and text in a shared vector space where semantically similar cross-modal content has similar vectors — this enables zero-shot cross-modal retrieval and classification without labeled training data
- The full pipeline is: load each modality → preprocess (clean, resize, normalize) → extract features (TF-IDF/embeddings for text; CNN features for image/video; MFCCs for audio; raw/engineered for tabular) → scale per modality → concatenate → train LogisticRegression or RandomForest → evaluate and compare against single-modal baselines