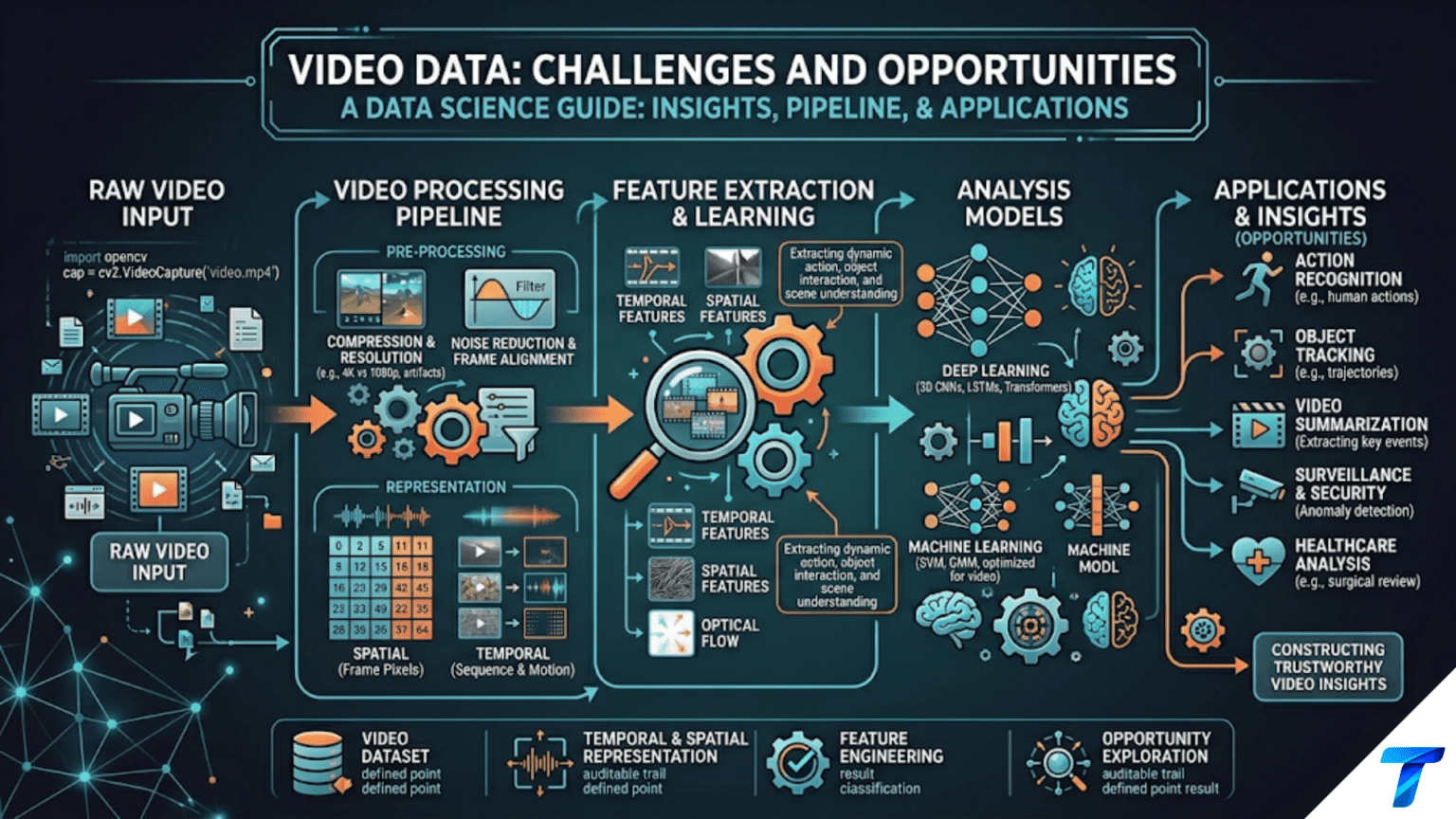
Video data is a sequence of images (frames) combined with audio, captured at a fixed frame rate (typically 24–60 frames per second). As data, a single minute of 1080p video at 30 fps contains 1,800 individual image frames — roughly 10–15 GB of raw uncompressed data — making video the most storage-intensive common data type. The core data science challenge with video is reducing this overwhelming volume to the events and patterns that matter: detecting when something interesting happens, classifying what action or object is present, tracking how it changes over time, and extracting text or speech from the audiovisual stream. In Python, OpenCV handles frame-by-frame extraction and manipulation, while pre-trained models from torchvision and Hugging Face handle high-level understanding like action recognition and object detection.
Introduction
Video is one of the fastest-growing data sources in the modern world. Security cameras generate continuous streams. Manufacturing plants record production lines. Hospitals capture surgical procedures. Social media platforms process billions of uploaded videos daily. Autonomous vehicles generate terabytes of camera footage per hour. Broadcast networks archive decades of content.
For data scientists, video presents a unique combination of extraordinary information density and extraordinary analytical challenge. The information density is real — a security camera clip shows not just what happened but how, when, in what sequence, with what timing, and with what spatial relationships between objects. The analytical challenge is equally real: video is simultaneously the most complex, most voluminous, and most computationally demanding data type you’ll encounter.
This article addresses video data practically: what video is as data, the fundamental challenge of scale, how to extract frames and audio in Python, key analytical approaches (frame sampling, scene detection, optical flow, object detection, action recognition), and how to build practical video analysis pipelines without requiring specialized hardware. The focus is on the conceptual framework and the patterns that make video analytics tractable rather than on exhaustive deep learning theory.
What Is Video as Data?
The Basic Structure
Video is fundamentally a sequence of still images (frames) played back at a rate fast enough that the human visual system perceives continuous motion.
Key properties:
| Property | Typical Range | Effect on Data |
|---|---|---|
| Frame rate (fps) | 24–120 fps | Determines temporal resolution |
| Resolution | 360p – 8K | Determines spatial resolution per frame |
| Bit depth | 8–12 bits | Color precision per channel |
| Duration | Seconds to hours | Total number of frames |
| Codec | H.264, H.265, VP9 | Compression method |
| Audio channels | 0–8 | Accompanying audio tracks |
The Scale Problem
This is the defining challenge of video data. Consider:
A 1-minute, 1080p, 30fps video:
Frames: 30 fps × 60 s = 1,800 frames
Pixels per frame: 1920 × 1080 = 2,073,600 pixels
Channels per pixel: 3 (RGB)
Uncompressed size: 1,800 × 2,073,600 × 3 bytes = ~11.2 GB
Compressed (H.264): ~300 MB – 1 GB depending on contentFor reference: a 1-hour security camera feed at 1080p/30fps contains 108,000 frames. Even after extracting features from each frame, storing and processing this volume requires deliberate engineering choices.
The practical implication: you almost never process every frame of video. Instead, you sample frames at a lower rate, detect interesting intervals, or extract summary statistics — reducing the effective data volume by 10–1000× before doing intensive analysis.
Temporal Relationships: What Makes Video Unique
The defining characteristic that distinguishes video from a random collection of images is temporal continuity — frames are causally related. An object at position (x, y) at frame t is usually near position (x+Δx, y+Δy) at frame t+1. Actions unfold over time (a person stands up, walks to a door, opens it) in ways that no single frame can capture.
This temporal structure is both the opportunity and the complexity of video analysis:
- Opportunity: Detect motion, track objects, recognize actions, understand scene dynamics
- Complexity: Models must process sequences, not individual images; storage must be sequential; temporal context is required for correct interpretation
Setting Up the Video Analysis Environment
pip install opencv-python-headless # OpenCV without GUI (for servers)
# or:
pip install opencv-python # OpenCV with GUI (for laptops)
pip install imageio imageio-ffmpeg
pip install scenedetect
pip install torch torchvision # For deep learning modelsReading Video Files in Python
OpenCV is the primary Python tool for video I/O:
import cv2
import numpy as np
from pathlib import Path
def get_video_info(filepath: str) -> dict:
"""
Extract technical metadata from a video file.
Parameters
----------
filepath : str
Path to the video file.
Returns
-------
dict
Video properties: fps, frame count, resolution, duration, codec.
"""
cap = cv2.VideoCapture(filepath)
if not cap.isOpened():
raise IOError(f"Cannot open video file: {filepath}")
fps = cap.get(cv2.CAP_PROP_FPS)
n_frames = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))
width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
fourcc_int = int(cap.get(cv2.CAP_PROP_FOURCC))
codec = "".join([chr((fourcc_int >> 8 * i) & 0xFF) for i in range(4)])
duration_s = n_frames / fps if fps > 0 else 0
file_size_mb = Path(filepath).stat().st_size / 1e6 if Path(filepath).exists() else None
cap.release()
info = {
"filepath": filepath,
"fps": round(fps, 2),
"n_frames": n_frames,
"width": width,
"height": height,
"resolution": f"{width}×{height}",
"aspect_ratio": f"{width//np.gcd(width, height)}:{height//np.gcd(width, height)}",
"duration_s": round(duration_s, 2),
"duration_fmt": f"{int(duration_s//3600):02d}:{int((duration_s%3600)//60):02d}:{duration_s%60:05.2f}",
"codec": codec.strip(),
"file_size_mb": round(file_size_mb, 1) if file_size_mb else None,
"estimated_raw_gb": round(n_frames * width * height * 3 / 1e9, 2)
}
for key, val in info.items():
print(f" {key:20s}: {val}")
return info
info = get_video_info("data/videos/sample.mp4")Frame Extraction: Getting Images from Video
The most fundamental video operation is reading frames:
import cv2
import numpy as np
import os
from pathlib import Path
def extract_frames(
filepath: str,
output_dir: str = None,
sample_rate: float = 1.0, # Frames per second to extract (None = all)
max_frames: int = None,
start_time: float = 0.0, # Start offset in seconds
end_time: float = None, # End offset in seconds (None = until end)
resize: tuple = None, # (width, height) to resize extracted frames
save_format: str = "jpg",
return_arrays: bool = False # Return numpy arrays instead of saving
) -> list:
"""
Extract frames from a video file at a specified rate.
This is the fundamental operation for video analysis —
converting a video into analyzable individual images.
Parameters
----------
filepath : str
Input video file path.
output_dir : str, optional
Directory to save extracted frames. Required if return_arrays=False.
sample_rate : float
Frames per second to extract. None = extract every frame.
Use 1.0 for one frame per second; 0.1 for one per 10 seconds.
max_frames : int, optional
Maximum total frames to extract.
start_time, end_time : float
Time window to extract from (seconds).
resize : tuple, optional
(width, height) to resize each frame. None = original size.
save_format : str
'jpg' (compressed, smaller) or 'png' (lossless, larger).
return_arrays : bool
If True, return list of numpy arrays instead of saving files.
Returns
-------
list
File paths of saved frames, or numpy arrays if return_arrays=True.
"""
cap = cv2.VideoCapture(filepath)
if not cap.isOpened():
raise IOError(f"Cannot open: {filepath}")
video_fps = cap.get(cv2.CAP_PROP_FPS)
n_frames = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))
duration_s = n_frames / video_fps
if end_time is None:
end_time = duration_s
# Determine which frame indices to extract
if sample_rate is None:
# Extract every frame in the time window
start_frame = int(start_time * video_fps)
end_frame = int(end_time * video_fps)
frame_indices = list(range(start_frame, end_frame))
else:
# Extract at the specified rate
interval = video_fps / sample_rate
start_frame = int(start_time * video_fps)
end_frame = int(end_time * video_fps)
frame_indices = [
int(start_frame + i * interval)
for i in range(int((end_frame - start_frame) / interval))
]
if max_frames:
frame_indices = frame_indices[:max_frames]
# Create output directory
if output_dir and not return_arrays:
Path(output_dir).mkdir(parents=True, exist_ok=True)
results = []
frames_done = 0
for frame_idx in frame_indices:
cap.set(cv2.CAP_PROP_POS_FRAMES, frame_idx)
ret, frame = cap.read()
if not ret:
break
# Resize if requested
if resize:
frame = cv2.resize(frame, resize, interpolation=cv2.INTER_LANCZOS4)
if return_arrays:
# Convert BGR → RGB before returning
results.append(cv2.cvtColor(frame, cv2.COLOR_BGR2RGB))
else:
timestamp_s = frame_idx / video_fps
filename = f"frame_{frame_idx:06d}_{timestamp_s:.2f}s.{save_format}"
filepath_out = os.path.join(output_dir, filename)
cv2.imwrite(filepath_out, frame,
[cv2.IMWRITE_JPEG_QUALITY, 90] if save_format == "jpg" else [])
results.append(filepath_out)
frames_done += 1
if frames_done % 100 == 0:
print(f" Extracted {frames_done}/{len(frame_indices)} frames...")
cap.release()
print(f"Extracted {len(results)} frames from {filepath}")
return results
# Extract 1 frame per second from a video
frames = extract_frames(
"data/videos/surveillance.mp4",
output_dir="output/frames/",
sample_rate=1.0,
max_frames=60
)
# Extract frames as arrays for immediate processing
frame_arrays = extract_frames(
"data/videos/sample.mp4",
sample_rate=2.0,
resize=(640, 360),
return_arrays=True
)
print(f"Extracted {len(frame_arrays)} frames, shape: {frame_arrays[0].shape}")Scene Detection: Finding Where Things Change
Scene detection automatically identifies transitions between scenes — different camera shots, locations, or situations. This is critical for reducing video to analyzable segments without processing every frame.
import cv2
import numpy as np
import pandas as pd
def detect_scene_changes(
filepath: str,
threshold: float = 30.0,
min_scene_length_s: float = 1.0,
method: str = "histogram"
) -> pd.DataFrame:
"""
Detect scene changes in a video using frame-to-frame difference metrics.
Parameters
----------
filepath : str
Video file path.
threshold : float
Sensitivity for detecting a cut. Lower = more sensitive.
Typical values: 20-40 for hard cuts, 10-20 for gradual transitions.
min_scene_length_s : float
Minimum scene duration in seconds (suppresses rapid flickering).
method : str
'histogram': histogram difference (fast, works in all conditions)
'pixel': mean absolute pixel difference (simpler)
Returns
-------
pd.DataFrame
Detected scenes with start/end times, duration, and frame indices.
"""
cap = cv2.VideoCapture(filepath)
fps = cap.get(cv2.CAP_PROP_FPS)
min_frames = int(min_scene_length_s * fps)
scene_boundaries = [0] # First scene starts at frame 0
prev_hist = None
frame_idx = 0
while True:
ret, frame = cap.read()
if not ret:
break
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
if method == "histogram":
hist = cv2.calcHist([gray], [0], None, [64], [0, 256])
hist = cv2.normalize(hist, hist).flatten()
if prev_hist is not None:
# Chi-squared distance between histograms
diff = cv2.compareHist(prev_hist, hist, cv2.HISTCMP_CHISQR)
if diff > threshold and (frame_idx - scene_boundaries[-1]) >= min_frames:
scene_boundaries.append(frame_idx)
prev_hist = hist
elif method == "pixel":
if prev_hist is not None:
diff = np.mean(np.abs(gray.astype(float) - prev_hist.astype(float)))
if diff > threshold and (frame_idx - scene_boundaries[-1]) >= min_frames:
scene_boundaries.append(frame_idx)
prev_hist = gray.copy()
frame_idx += 1
cap.release()
# Get total frame count for the last scene
scene_boundaries.append(frame_idx)
# Build scenes DataFrame
scenes = []
for i in range(len(scene_boundaries) - 1):
start_frame = scene_boundaries[i]
end_frame = scene_boundaries[i + 1]
scenes.append({
"scene_id": i + 1,
"start_frame": start_frame,
"end_frame": end_frame,
"start_time_s": round(start_frame / fps, 2),
"end_time_s": round(end_frame / fps, 2),
"duration_s": round((end_frame - start_frame) / fps, 2),
"n_frames": end_frame - start_frame,
})
df = pd.DataFrame(scenes)
print(f"\nDetected {len(df)} scenes in {filepath}")
print(f"Avg scene duration: {df['duration_s'].mean():.1f}s")
print(df.head(10).to_string(index=False))
return df
scenes = detect_scene_changes(
"data/videos/movie_clip.mp4",
threshold=25.0,
min_scene_length_s=2.0
)Motion Analysis: Optical Flow
Optical flow tracks how pixels move between consecutive frames — the apparent motion of objects in the scene. It’s the mathematical foundation of motion detection and a useful feature for action recognition.
import cv2
import numpy as np
def compute_optical_flow_magnitude(
filepath: str,
sample_every_n_frames: int = 1,
resize: tuple = (320, 180)
) -> np.ndarray:
"""
Compute mean optical flow magnitude (motion intensity) over time.
High flow magnitude → lots of movement in the frame.
Low flow magnitude → mostly static scene.
Parameters
----------
filepath : str
Video file path.
sample_every_n_frames : int
Compute flow only every N frames for speed.
resize : tuple
Resolution for flow computation (smaller = faster).
Returns
-------
np.ndarray
Array of mean flow magnitude per frame pair.
"""
cap = cv2.VideoCapture(filepath)
flow_magnitudes = []
prev_gray = None
frame_idx = 0
while True:
ret, frame = cap.read()
if not ret:
break
if frame_idx % sample_every_n_frames == 0:
# Resize for speed
frame_small = cv2.resize(frame, resize)
gray = cv2.cvtColor(frame_small, cv2.COLOR_BGR2GRAY)
if prev_gray is not None:
# Farneback dense optical flow
flow = cv2.calcOpticalFlowFarneback(
prev_gray, gray,
None,
pyr_scale=0.5, # Pyramid scale
levels=3, # Number of pyramid levels
winsize=15, # Averaging window size
iterations=3, # Iterations per level
poly_n=5, # Polynomial expansion neighborhood
poly_sigma=1.2, # Gaussian std for polynomial expansion
flags=0
)
# Compute magnitude (how much motion) from x,y flow components
magnitude, _ = cv2.cartToPolar(flow[..., 0], flow[..., 1])
flow_magnitudes.append(magnitude.mean())
else:
flow_magnitudes.append(0.0)
prev_gray = gray
frame_idx += 1
cap.release()
return np.array(flow_magnitudes)
def extract_motion_features(
filepath: str,
window_size: int = 30
) -> dict:
"""
Extract temporal motion features from a video for classification or search.
Parameters
----------
filepath : str
Video file path.
window_size : int
Number of frames per analysis window.
Returns
-------
dict
Motion statistics: mean, std, peaks, proportion of high-motion frames.
"""
magnitudes = compute_optical_flow_magnitude(filepath)
if len(magnitudes) == 0:
return {}
# Normalize to [0, 1]
mag_norm = (magnitudes - magnitudes.min()) / (magnitudes.max() - magnitudes.min() + 1e-10)
# Compute statistics
high_motion_threshold = 0.3
features = {
"mean_motion": float(magnitudes.mean()),
"std_motion": float(magnitudes.std()),
"max_motion": float(magnitudes.max()),
"pct_high_motion": float((mag_norm > high_motion_threshold).mean()),
"motion_variability": float(np.diff(magnitudes).std()),
"n_motion_peaks": int(sum(1 for i in range(1, len(mag_norm)-1)
if mag_norm[i] > mag_norm[i-1] and
mag_norm[i] > mag_norm[i+1] and
mag_norm[i] > high_motion_threshold))
}
print("Motion features:")
for k, v in features.items():
print(f" {k:25s}: {v:.4f}")
return featuresObject Detection in Video
Running object detection on video frames is one of the most common video analytics tasks: counting people, detecting vehicles, tracking products on a conveyor belt.
import cv2
import torch
import numpy as np
import pandas as pd
from pathlib import Path
class VideoObjectDetector:
"""
Run object detection on video using a pre-trained YOLOv5/YOLOv8 model.
Processes frames at a configurable rate, accumulates detections
over time, and provides summary statistics.
"""
def __init__(self, model_name: str = "yolov5s", confidence: float = 0.5):
"""
Initialize the object detector.
Parameters
----------
model_name : str
YOLOv5 model size: 'yolov5n' (tiny), 'yolov5s', 'yolov5m',
'yolov5l', 'yolov5x' (largest). Smaller = faster.
confidence : float
Minimum confidence threshold for detections.
"""
print(f"Loading {model_name} object detection model...")
# torch.hub.load downloads the model on first use
self.model = torch.hub.load("ultralytics/yolov5", model_name,
pretrained=True, verbose=False)
self.model.conf = confidence
self.model.eval()
if torch.cuda.is_available():
self.model.cuda()
self.class_names = self.model.names
print(f"Model loaded. Classes: {len(self.class_names)}")
def detect_in_frame(
self,
frame_rgb: np.ndarray
) -> pd.DataFrame:
"""
Run detection on a single frame.
Returns DataFrame with detected objects: class, confidence, bbox.
"""
results = self.model(frame_rgb)
detections = results.pandas().xyxy[0] # x1, y1, x2, y2, confidence, class, name
return detections
def analyze_video(
self,
filepath: str,
sample_fps: float = 2.0,
max_frames: int = None,
track_classes: list = None # e.g., ["person", "car", "truck"]
) -> dict:
"""
Run object detection across a video and produce summary statistics.
Parameters
----------
filepath : str
Video file path.
sample_fps : float
Frames per second to analyze (lower = faster, less accurate).
max_frames : int, optional
Maximum frames to process.
track_classes : list, optional
If provided, only report these object classes.
Returns
-------
dict
Detection summary: counts, time series, class distribution.
"""
cap = cv2.VideoCapture(filepath)
fps = cap.get(cv2.CAP_PROP_FPS)
interval = int(fps / sample_fps)
all_detections = []
frame_idx = 0
frames_processed = 0
print(f"Analyzing {filepath} at {sample_fps} fps...")
while True:
ret, frame = cap.read()
if not ret:
break
if frame_idx % interval == 0:
frame_rgb = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
dets = self.detect_in_frame(frame_rgb)
if track_classes:
dets = dets[dets["name"].isin(track_classes)]
for _, det in dets.iterrows():
all_detections.append({
"frame_idx": frame_idx,
"timestamp_s": round(frame_idx / fps, 2),
"class": det["name"],
"confidence": round(det["confidence"], 3),
"x1": int(det["xmin"]),
"y1": int(det["ymin"]),
"x2": int(det["xmax"]),
"y2": int(det["ymax"]),
})
frames_processed += 1
if frames_processed % 50 == 0:
print(f" Processed {frames_processed} frames...")
if max_frames and frames_processed >= max_frames:
break
frame_idx += 1
cap.release()
# Build summary
df = pd.DataFrame(all_detections)
if df.empty:
print("No objects detected.")
return {"detections_df": df, "summary": {}}
print(f"\nDetection Summary:")
print(f" Frames analyzed: {frames_processed:,}")
print(f" Total detections: {len(df):,}")
class_counts = df["class"].value_counts()
print(f"\n Detections by class:")
print(class_counts.to_string())
# Time series: object counts per second
df["second"] = df["timestamp_s"].round(0).astype(int)
objects_per_second = df.groupby(["second", "class"]).size().unstack(fill_value=0)
return {
"detections_df": df,
"class_counts": class_counts.to_dict(),
"objects_per_second": objects_per_second,
"frames_analyzed": frames_processed
}Extracting Audio from Video
Video files contain both video and audio tracks. Extracting the audio enables speech transcription and audio analysis:
import subprocess
import os
from pathlib import Path
def extract_audio_from_video(
video_filepath: str,
output_filepath: str = None,
sample_rate: int = 16000, # 16kHz optimal for speech recognition
channels: int = 1, # Mono for speech
start_time: float = None,
duration: float = None
) -> str:
"""
Extract audio track from a video file using ffmpeg.
Requires ffmpeg to be installed on the system:
macOS: brew install ffmpeg
Ubuntu: sudo apt install ffmpeg
Windows: download from ffmpeg.org
Parameters
----------
video_filepath : str
Input video file.
output_filepath : str, optional
Output audio file path. Defaults to same name with .wav extension.
sample_rate : int
Output audio sample rate in Hz. 16000 recommended for speech.
channels : int
1 = mono, 2 = stereo.
start_time : float, optional
Start extraction at this offset (seconds).
duration : float, optional
Extract this many seconds of audio.
Returns
-------
str
Path to the extracted audio file.
"""
if output_filepath is None:
output_filepath = str(Path(video_filepath).with_suffix(".wav"))
# Build ffmpeg command
cmd = ["ffmpeg", "-y"] # -y = overwrite without asking
if start_time is not None:
cmd.extend(["-ss", str(start_time)])
cmd.extend(["-i", video_filepath])
if duration is not None:
cmd.extend(["-t", str(duration)])
cmd.extend([
"-ar", str(sample_rate), # Sample rate
"-ac", str(channels), # Channels
"-vn", # No video
output_filepath
])
result = subprocess.run(cmd, capture_output=True, text=True)
if result.returncode != 0:
raise RuntimeError(f"ffmpeg failed: {result.stderr}")
file_size_mb = Path(output_filepath).stat().st_size / 1e6
print(f"Audio extracted: {output_filepath} ({file_size_mb:.1f} MB)")
return output_filepath
def extract_frames_and_audio(
video_filepath: str,
output_base: str,
frame_rate: float = 1.0
) -> dict:
"""
Extract both frames and audio from a video file.
Returns paths to all extracted assets.
"""
base_path = Path(output_base)
frames_dir = base_path / "frames"
audio_path = base_path / "audio.wav"
frames_dir.mkdir(parents=True, exist_ok=True)
# Extract frames
frames = extract_frames(
video_filepath,
output_dir=str(frames_dir),
sample_rate=frame_rate
)
# Extract audio
audio = extract_audio_from_video(
video_filepath,
output_filepath=str(audio_path),
sample_rate=16000
)
return {
"frames": frames,
"audio": str(audio_path),
"n_frames": len(frames)
}Building a Practical Video Analysis Pipeline
Combining all components into a complete analytical workflow:
import cv2
import numpy as np
import pandas as pd
import json
from pathlib import Path
from datetime import datetime, timezone
def analyze_video_file(
filepath: str,
output_dir: str = "output/video_analysis/",
frame_sample_rate: float = 1.0,
detect_scenes: bool = True,
compute_motion: bool = True,
transcribe_speech: bool = False,
max_analysis_seconds: float = None
) -> dict:
"""
Complete video analysis pipeline.
Extracts metadata, samples frames, detects scenes,
computes motion statistics, and optionally transcribes speech.
Parameters
----------
filepath : str
Path to the video file.
output_dir : str
Directory for all analysis outputs.
frame_sample_rate : float
Frames per second to sample for analysis.
detect_scenes : bool
Run scene change detection.
compute_motion : bool
Compute optical flow motion statistics.
transcribe_speech : bool
Extract audio and transcribe with Whisper.
max_analysis_seconds : float, optional
Limit analysis to first N seconds (for long videos).
Returns
-------
dict
Complete analysis results.
"""
output_path = Path(output_dir)
output_path.mkdir(parents=True, exist_ok=True)
results = {
"filepath": filepath,
"analyzed_at": datetime.now(timezone.utc).isoformat(),
"pipeline_version": "1.0"
}
print(f"{'='*60}")
print(f"Video Analysis Pipeline")
print(f"Input: {filepath}")
print(f"{'='*60}")
# ── 1. Video Metadata ──────────────────────────────────────────
print("\n[1/5] Extracting video metadata...")
info = get_video_info(filepath)
results["metadata"] = info
effective_end = max_analysis_seconds or info["duration_s"]
print(f"Analyzing first {effective_end:.0f}s of {info['duration_s']:.0f}s video")
# ── 2. Frame Sampling ──────────────────────────────────────────
print(f"\n[2/5] Sampling frames at {frame_sample_rate} fps...")
frames_dir = output_path / "frames"
frames_dir.mkdir(exist_ok=True)
sampled_frames = extract_frames(
filepath,
output_dir=str(frames_dir),
sample_rate=frame_sample_rate,
end_time=effective_end,
resize=(640, 360)
)
results["n_frames_sampled"] = len(sampled_frames)
results["frame_paths"] = sampled_frames[:10] # Store first 10 paths
# ── 3. Scene Detection ─────────────────────────────────────────
if detect_scenes:
print(f"\n[3/5] Detecting scene changes...")
scenes_df = detect_scene_changes(
filepath,
threshold=25.0,
min_scene_length_s=2.0
)
if max_analysis_seconds:
scenes_df = scenes_df[scenes_df["start_time_s"] <= max_analysis_seconds]
results["scenes"] = {
"n_scenes": len(scenes_df),
"avg_duration_s": round(scenes_df["duration_s"].mean(), 2),
"scene_table": scenes_df.to_dict("records")
}
scenes_df.to_csv(output_path / "scenes.csv", index=False)
else:
print("\n[3/5] Scene detection: skipped")
# ── 4. Motion Analysis ─────────────────────────────────────────
if compute_motion:
print(f"\n[4/5] Computing motion statistics...")
motion_features = extract_motion_features(filepath)
results["motion"] = motion_features
else:
print("\n[4/5] Motion analysis: skipped")
# ── 5. Speech Transcription ────────────────────────────────────
if transcribe_speech:
print(f"\n[5/5] Transcribing speech...")
try:
import whisper
audio_path = str(output_path / "audio.wav")
extract_audio_from_video(filepath, audio_path,
sample_rate=16000)
model = whisper.load_model("base")
transcript = model.transcribe(audio_path, verbose=False)
results["transcript"] = {
"text": transcript["text"].strip(),
"language": transcript["language"],
"n_segments": len(transcript.get("segments", []))
}
print(f"Transcription: {transcript['text'][:200]}...")
except ImportError:
print("Whisper not installed. Skipping transcription.")
else:
print("\n[5/5] Speech transcription: skipped")
# ── Save results ───────────────────────────────────────────────
results_path = output_path / "analysis_results.json"
with open(results_path, "w") as f:
json.dump(results, f, indent=2, default=str)
print(f"\n{'='*60}")
print(f"Analysis complete!")
print(f"Results saved to: {output_path}")
print(f" Frames sampled: {results['n_frames_sampled']}")
if detect_scenes:
print(f" Scenes found: {results['scenes']['n_scenes']}")
print(f"{'='*60}")
return resultsVideo Analytics Use Cases and Patterns
Retail Analytics: Foot Traffic Counting
def count_people_in_video(
filepath: str,
sample_fps: float = 1.0
) -> pd.DataFrame:
"""
Count people visible in each frame of a video.
Uses a pre-trained person detector.
Returns a time series of people counts per frame.
"""
detector = VideoObjectDetector(model_name="yolov5n", confidence=0.5)
results = detector.analyze_video(
filepath,
sample_fps=sample_fps,
track_classes=["person"]
)
df = results["detections_df"]
if df.empty:
return pd.DataFrame(columns=["timestamp_s", "people_count"])
# Count unique people per frame (by frame_idx)
people_counts = (
df[df["class"] == "person"]
.groupby("frame_idx")
.agg(
people_count=("class", "count"),
timestamp_s=("timestamp_s", "first")
)
.reset_index()
)
# Fill in frames with 0 people
all_timestamps = df.groupby("frame_idx")["timestamp_s"].first().reset_index()
people_counts = all_timestamps.merge(
people_counts[["frame_idx", "people_count"]],
on="frame_idx", how="left"
).fillna({"people_count": 0})
print(f"\nFoot traffic summary:")
print(f" Average people visible: {people_counts['people_count'].mean():.1f}")
print(f" Peak count: {int(people_counts['people_count'].max())}")
print(f" Frames with any person: "
f"{(people_counts['people_count'] > 0).mean():.1%}")
return people_countsManufacturing: Defect Detection on Video Feed
import cv2
import torch
import numpy as np
def create_defect_detection_pipeline(
normal_video_path: str,
test_video_path: str,
frame_sample_rate: float = 5.0
) -> dict:
"""
Build and run a defect detection pipeline for manufacturing video.
Approach:
1. Extract frames from normal (good) production video
2. Train an anomaly detector on normal frames
3. Score frames from test video
4. Flag frames with high anomaly scores
This is the same transfer learning + anomaly detection approach
from the image data article, applied to video.
"""
# Step 1: Extract frames from normal production video
print("Extracting frames from normal video...")
normal_frames = extract_frames(
normal_video_path,
sample_rate=frame_sample_rate,
resize=(224, 224),
return_arrays=True
)
# Step 2: Extract CNN features from normal frames
from PIL import Image
from torchvision import models, transforms
transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
model = models.resnet18(weights=models.ResNet18_Weights.IMAGENET1K_V1)
model = torch.nn.Sequential(*list(model.children())[:-1])
model.eval()
def frames_to_features(frames):
features = []
for frame in frames:
img = Image.fromarray(frame)
tensor = transform(img).unsqueeze(0)
with torch.no_grad():
feat = model(tensor).squeeze().numpy()
features.append(feat)
return np.array(features)
print("Extracting features from normal frames...")
normal_features = frames_to_features(normal_frames)
# Step 3: Train anomaly detector
from sklearn.preprocessing import StandardScaler
from sklearn.ensemble import IsolationForest
scaler = StandardScaler()
X_normal = scaler.fit_transform(normal_features)
detector = IsolationForest(contamination=0.05, random_state=42, n_jobs=-1)
detector.fit(X_normal)
# Step 4: Score test video
print("Scoring test video for defects...")
test_frames = extract_frames(
test_video_path,
sample_rate=frame_sample_rate,
resize=(224, 224),
return_arrays=True
)
test_features = frames_to_features(test_frames)
X_test = scaler.transform(test_features)
scores = detector.score_samples(X_test)
is_anomaly = detector.predict(X_test) == -1
print(f"\nDefect detection results:")
print(f" Frames analyzed: {len(test_frames):,}")
print(f" Anomalous frames: {is_anomaly.sum():,} ({is_anomaly.mean():.1%})")
return {
"anomaly_scores": scores,
"is_anomaly": is_anomaly,
"n_anomalies": int(is_anomaly.sum()),
"anomaly_rate": float(is_anomaly.mean())
}The Bandwidth and Storage Challenge
Video analytics at scale requires explicit attention to storage and compute:
def estimate_video_processing_cost(
video_hours: float,
fps: float = 30.0,
resolution: tuple = (1920, 1080),
sample_rate: float = 1.0, # Analysis fps
feature_dim: int = 512, # CNN feature dimension
bytes_per_feature: int = 4 # float32
) -> dict:
"""
Estimate storage and compute requirements for a video analytics project.
Parameters
----------
video_hours : float
Total hours of video to process.
fps : float
Video frame rate.
resolution : tuple
Video frame resolution (width, height).
sample_rate : float
Frames per second to analyze.
feature_dim : int
CNN feature vector dimension.
bytes_per_feature : int
Bytes per feature value.
"""
total_seconds = video_hours * 3600
total_frames = total_seconds * fps
analyzed_frames= total_seconds * sample_rate
# Raw video (uncompressed)
bytes_per_frame = resolution[0] * resolution[1] * 3 # RGB
raw_storage_gb = total_frames * bytes_per_frame / 1e9
# Compressed video (H.264 ~100:1 ratio)
compressed_gb = raw_storage_gb / 100
# Extracted features
features_storage_gb = analyzed_frames * feature_dim * bytes_per_feature / 1e9
# Processing time estimate (rough: 10ms per frame on GPU)
processing_hours = analyzed_frames * 0.01 / 3600 # 10ms per frame
results = {
"video_hours": video_hours,
"total_frames": f"{total_frames:,.0f}",
"analyzed_frames": f"{analyzed_frames:,.0f}",
"sample_rate_ratio": f"1 in {fps/sample_rate:.0f} frames",
"raw_storage_gb": round(raw_storage_gb, 1),
"compressed_gb": round(compressed_gb, 1),
"features_storage_gb": round(features_storage_gb, 3),
"est_gpu_hours": round(processing_hours, 1)
}
print(f"\nVideo Processing Cost Estimate: {video_hours}h of video")
print(f" Total frames: {results['total_frames']}")
print(f" Frames analyzed: {results['analyzed_frames']} ({results['sample_rate_ratio']})")
print(f" Raw storage: {results['raw_storage_gb']:.0f} GB")
print(f" Compressed storage: {results['compressed_gb']:.1f} GB")
print(f" Feature storage: {results['features_storage_gb']:.1f} GB")
print(f" Est. GPU processing: {results['est_gpu_hours']:.1f} GPU-hours")
return results
# Example: 1 week of security camera footage (24/7)
estimate_video_processing_cost(
video_hours=24 * 7, # 168 hours
fps=15.0,
resolution=(1280, 720),
sample_rate=0.5 # Analyze 1 frame every 2 seconds
)Best Practices for Video Data Science
The Sampling Strategy
Sampling frequency should match the event timescale you’re looking for:
| Analysis Goal | Recommended Sample Rate |
|---|---|
| Scene/cut detection | Every frame (or dense, ~5fps) |
| Counting people/objects | 1–2 fps |
| Activity recognition | 2–5 fps |
| Occasional event detection (falls, alarms) | 0.5–1 fps |
| Time-lapse analysis (construction, growth) | 1/minute to 1/hour |
Processing Order for Efficiency
Step 1: Scene detection (fast, CPU, on full video)
↓ Identify intervals of interest
Step 2: Motion filtering (fast, CPU, on scenes only)
↓ Skip static scenes
Step 3: Object detection (slower, GPU, on high-motion frames)
↓ Find frames with relevant objects
Step 4: Deep feature extraction (slow, GPU, on selected frames)
↓ Rich representations of key moments
Step 5: Classification/analysis (fast, CPU, on extracted features)Never run your most computationally expensive steps on all frames. Filter early to reduce the volume fed to expensive models.
Summary
Video data is the ultimate combination of opportunities and challenges in data science. The opportunities are genuine — video captures spatiotemporal information that no other data type can provide, from human behavior and physical processes to environmental change and mechanical operation. The challenges are equally genuine — the volume is massive, the computational requirements are heavy, and the tools require careful orchestration.
The practical framework for video data science: sample aggressively (1 fps instead of 30fps reduces work by 97%), filter progressively (use cheap scene detection to skip static content before running expensive object detection), extract once (compute CNN features once and store them, don’t reprocess raw frames), and leverage pre-trained models (YOLOv5 for detection, ResNet for features, Whisper for audio — these eliminate the need for labeled training data in many applications).
The most valuable skill in video analytics is not knowing every algorithm — it is understanding the scale math (how many frames, how many GB, how many GPU-hours) and using that to design a pipeline that extracts the needed information without drowning in data volume.
Key Takeaways
- Video is frames × fps × duration — a one-minute 1080p/30fps video contains 1,800 frames and ~10 GB uncompressed; always sample aggressively (1–2 fps instead of 30) before running expensive analysis
- OpenCV’s
VideoCaptureis the primary interface:cap.read()returns(ret, frame)whereframeis a BGR numpy array — always convert withcv2.cvtColor(frame, cv2.COLOR_BGR2RGB)before displaying or passing to other libraries - Scene detection identifies when the content changes (cuts, transitions) and is the most efficient first step — it segments the video into meaningful intervals so you only analyze the parts that matter
- Optical flow measures pixel motion between frames and is the right tool for motion-based analytics: detecting activity, measuring crowd density changes, and identifying unusual events in surveillance footage
- The transfer learning pattern from image analysis applies directly to video: extract CNN features from sampled frames using a pre-trained ResNet or EfficientNet, then train a lightweight classifier on those features — this avoids training from scratch
- YOLOv5/YOLOv8 provides pre-trained real-time object detection via
torch.hub.load("ultralytics/yolov5", "yolov5s")— the smallest models (yolov5n) run in real-time on CPU; larger models require GPU - Extract audio with
ffmpegvia Python subprocess, then apply Whisper for transcription or Librosa for audio feature extraction — video and audio analysis pipelines can be combined for richer understanding - The efficient pipeline order is: scene detection → motion filtering → object detection → deep feature extraction → classification — apply each step only to the output of the previous filter to avoid expensive processing on uninformative content