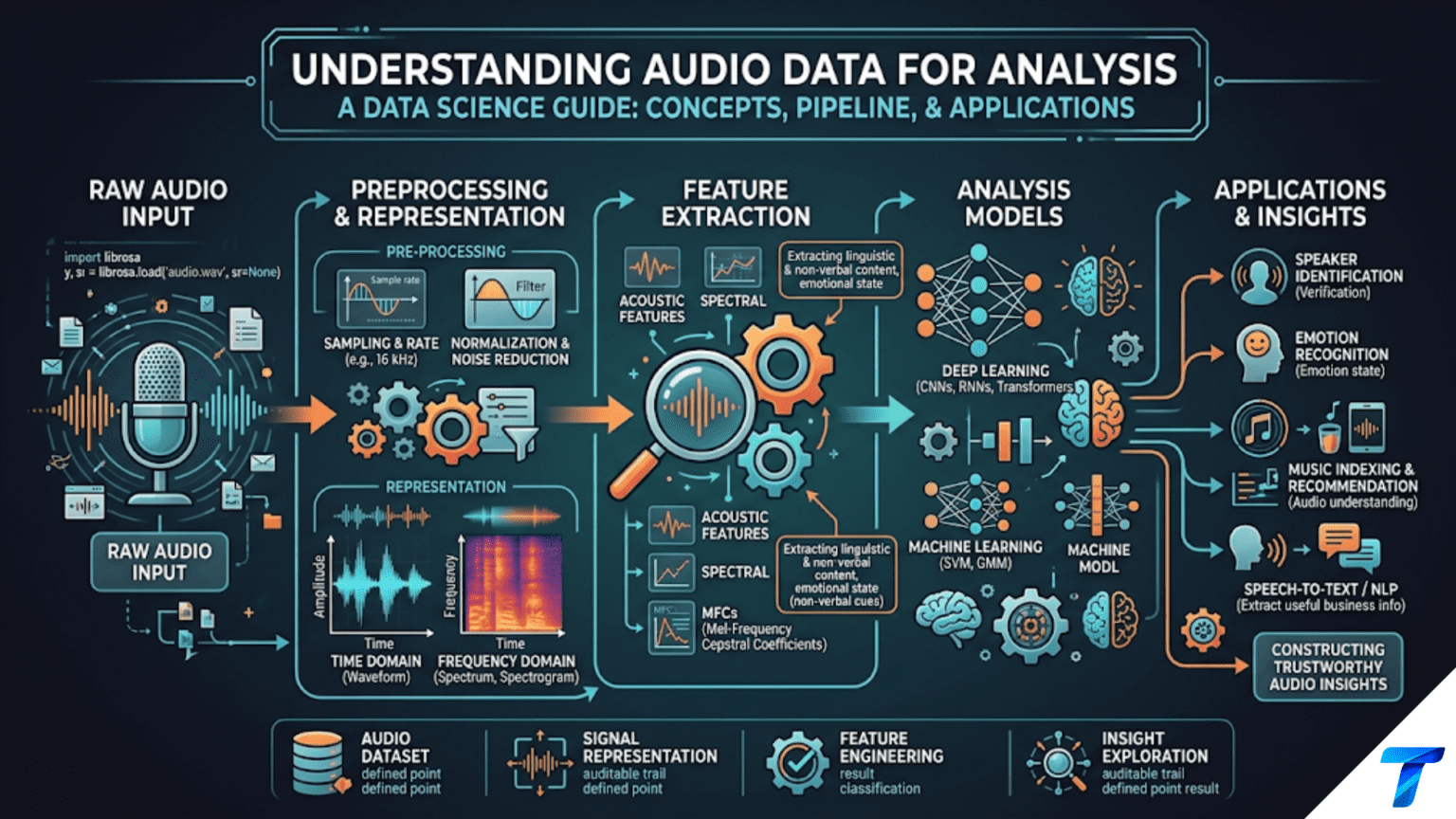
Audio data is a time-series signal representing pressure variations in air over time, stored digitally as a sequence of amplitude samples at a fixed sample rate (typically 16,000–44,100 samples per second). Raw waveforms are rarely used directly for analysis — instead, audio is transformed into spectrograms (visual frequency-over-time representations) or MFCCs (Mel-Frequency Cepstral Coefficients), which capture the perceptually relevant features of sound. In Python, librosa is the primary library for audio loading, feature extraction, and visualization; soundfile and scipy.io.wavfile handle file I/O; and for speech-to-text, the Whisper model from OpenAI provides state-of-the-art transcription in a few lines of code.
Introduction
Audio data is everywhere — recorded speech, music, environmental sounds, industrial machinery noise, medical acoustic signals like heart sounds and breathing patterns. For data scientists, audio opens analytical possibilities that structured data cannot: analyzing call center conversations for sentiment and compliance, detecting equipment anomalies from vibration recordings, classifying environmental sounds from IoT sensors, transcribing meetings automatically, and building voice-activated interfaces.
Audio is fundamentally a time-series — a continuously varying signal sampled at high frequency — but it differs from typical time-series data in important ways. A 5-second audio clip sampled at 44,100 Hz contains 220,500 data points. The perceptually relevant information is not in the raw amplitudes but in the frequency content and how it changes over time. The human ear processes sound logarithmically, not linearly — small differences in low frequencies are more perceptible than the same differences in high frequencies. These characteristics drive the specialized feature extraction techniques (spectrograms, MFCCs, chroma features) that make audio analysis tractable.
This article introduces audio data for data scientists: the fundamental digital audio concepts, loading and visualizing audio in Python with Librosa, the key feature extraction techniques that transform raw waveforms into analyzable representations, audio classification using extracted features, and practical applications including speech transcription and anomaly detection.
Digital Audio Fundamentals
Before writing any code, a clear understanding of digital audio concepts prevents the common mistakes that arise from treating audio as just another time-series.
Sampling and Sample Rate
When a microphone captures sound, it measures air pressure variations continuously. To store this digitally, the analog signal is sampled at regular intervals. The sample rate (or sampling frequency) is how many samples are captured per second, measured in Hz.
| Sample Rate | Common Use |
|---|---|
| 8,000 Hz | Telephone audio (narrow band) |
| 16,000 Hz | Speech recognition, voice calls |
| 22,050 Hz | Mid-quality audio |
| 44,100 Hz | CD audio, professional music |
| 48,000 Hz | Video production standard |
| 192,000 Hz | High-resolution audio |
The Nyquist theorem states that to accurately represent a frequency, you must sample at least twice that frequency. At 44,100 Hz, the highest frequency representable is 22,050 Hz — slightly above the upper limit of human hearing (~20,000 Hz). This is why 44,100 Hz became the standard for CD audio.
For speech recognition and voice analytics, 16,000 Hz is the sweet spot — it captures all speech-relevant frequencies (80 Hz – 8,000 Hz) with minimal file size.
Bit Depth and Dynamic Range
The bit depth determines how many distinct amplitude values each sample can represent:
- 16-bit: 65,536 possible values (±32,768). CD standard. Sufficient for most data science work.
- 24-bit: 16,777,216 values. Professional recording.
- 32-bit float: Used internally by audio software; values in range [-1.0, 1.0].
Higher bit depth = greater dynamic range (ability to represent both very quiet and very loud sounds without distortion).
Audio File Formats
| Format | Type | Quality | Common Use |
|---|---|---|---|
| WAV | Uncompressed | Lossless | Professional, ML training data |
| FLAC | Lossless compressed | Lossless | Archival, audiophile |
| MP3 | Lossy compressed | Lossy | Music distribution |
| OGG/Vorbis | Lossy compressed | Lossy | Web audio |
| M4A/AAC | Lossy compressed | Lossy | Apple ecosystem |
| OPUS | Lossy compressed | Lossy | Telephony, streaming |
For data science work: WAV is preferred for training data (no compression artifacts). MP3 is acceptable for downstream analytics where exact waveform fidelity is less critical.
Setting Up the Environment
pip install librosa soundfile scipy matplotlib numpy
pip install openai-whisper # For speech transcription
pip install torch torchaudio # For deep learning audio tasksimport librosa
import librosa.display
import soundfile as sf
import numpy as np
import matplotlib.pyplot as plt
import scipy.io.wavfile as wavfile
print(f"librosa: {librosa.__version__}")
print(f"soundfile: {sf.__version__}")Loading and Inspecting Audio Files
import librosa
import numpy as np
import soundfile as sf
# ── Load with librosa ─────────────────────────────────────────────
# Returns: waveform array (float32, range approx [-1, 1])
# and sample rate
y, sr = librosa.load("data/audio/speech_sample.wav")
print(f"Sample rate: {sr} Hz") # Default: resampled to 22050
print(f"Duration: {librosa.get_duration(y=y, sr=sr):.2f} seconds")
print(f"Number of samples: {len(y):,}") # duration × sr
print(f"Array shape: {y.shape}") # (n_samples,) for mono
print(f"Data type: {y.dtype}") # float32
print(f"Amplitude range: [{y.min():.4f}, {y.max():.4f}]") # ~[-1, 1]
# Load at original sample rate (don't resample)
y_orig, sr_orig = librosa.load("data/audio/speech_sample.wav", sr=None)
print(f"\nOriginal sample rate: {sr_orig} Hz")
# Load at a specific sample rate (resample)
y_16k, sr_16k = librosa.load("data/audio/speech_sample.wav", sr=16000)
# Load only part of a file (efficient for long recordings)
y_first_10s, sr = librosa.load("data/audio/long_recording.wav",
offset=0.0, # Start at 0 seconds
duration=10.0) # Load 10 seconds only
# ── Load stereo audio ─────────────────────────────────────────────
# mono=True (default): convert stereo to mono by averaging channels
# mono=False: preserve stereo as (2, n_samples) array
y_stereo, sr = librosa.load("data/audio/stereo.wav", mono=False)
print(f"\nStereo shape: {y_stereo.shape}") # (2, n_samples)
print(f"Left channel: {y_stereo[0].shape}")
print(f"Right channel: {y_stereo[1].shape}")
# Convert stereo to mono manually
y_mono = y_stereo.mean(axis=0)
# ── Load with soundfile (faster, more formats) ────────────────────
data_sf, samplerate = sf.read("data/audio/speech_sample.wav")
print(f"\nsoundfile shape: {data_sf.shape}") # (n_samples,) or (n_samples, channels)
print(f"soundfile dtype: {data_sf.dtype}") # float64 by default
# ── Load with scipy (raw, no resampling) ─────────────────────────
sr_scipy, data_scipy = wavfile.read("data/audio/speech_sample.wav")
print(f"\nscipy rate: {sr_scipy}, shape: {data_scipy.shape}, dtype: {data_scipy.dtype}")
# scipy returns int16 by default (raw PCM values, not normalized to [-1,1])
# Normalize:
data_normalized = data_scipy.astype(np.float32) / 32768.0Visualizing Audio
import librosa
import librosa.display
import matplotlib.pyplot as plt
import numpy as np
# Create a synthetic audio signal for illustration
sr = 22050
duration = 3.0 # seconds
t = np.linspace(0, duration, int(sr * duration))
# Combine a 440 Hz tone (A4) with a 880 Hz tone (A5) and noise
y_clean = 0.5 * np.sin(2 * np.pi * 440 * t)
y_clean += 0.3 * np.sin(2 * np.pi * 880 * t)
y_noise = 0.05 * np.random.randn(len(t))
y = (y_clean + y_noise).astype(np.float32)
fig, axes = plt.subplots(4, 1, figsize=(14, 12))
fig.suptitle("Audio Visualization Suite", fontsize=14, fontweight="bold")
# ── 1. Waveform ────────────────────────────────────────────────────
ax1 = axes[0]
librosa.display.waveshow(y, sr=sr, ax=ax1, color="steelblue", alpha=0.7)
ax1.set_title("Waveform (Amplitude vs. Time)")
ax1.set_xlabel("Time (seconds)")
ax1.set_ylabel("Amplitude")
ax1.axhline(y=0, color="black", linewidth=0.5)
# ── 2. Short-Time Fourier Transform Spectrogram ────────────────────
D = librosa.stft(y)
D_db = librosa.amplitude_to_db(np.abs(D), ref=np.max)
ax2 = axes[1]
img = librosa.display.specshow(D_db, sr=sr, x_axis="time",
y_axis="hz", ax=ax2, cmap="magma")
plt.colorbar(img, ax=ax2, format="%+2.0f dB")
ax2.set_title("STFT Spectrogram (Frequency vs. Time)")
ax2.set_ylabel("Frequency (Hz)")
# ── 3. Mel Spectrogram ─────────────────────────────────────────────
mel_spec = librosa.feature.melspectrogram(y=y, sr=sr,
n_mels=128, fmax=8000)
mel_spec_db = librosa.power_to_db(mel_spec, ref=np.max)
ax3 = axes[2]
img = librosa.display.specshow(mel_spec_db, sr=sr, x_axis="time",
y_axis="mel", ax=ax3, cmap="magma",
fmax=8000)
plt.colorbar(img, ax=ax3, format="%+2.0f dB")
ax3.set_title("Mel Spectrogram (Perceptual Frequency Scale)")
ax3.set_ylabel("Mel Frequency")
# ── 4. Power Spectral Density (average frequency content) ─────────
ax4 = axes[3]
from scipy.signal import welch
freqs, psd = welch(y, fs=sr, nperseg=1024)
ax4.semilogy(freqs, psd, color="darkorange")
ax4.set_title("Power Spectral Density (Average Frequency Distribution)")
ax4.set_xlabel("Frequency (Hz)")
ax4.set_ylabel("Power (log scale)")
ax4.set_xlim([0, 4000])
ax4.axvline(x=440, color="blue", linestyle="--", alpha=0.7, label="440 Hz (A4)")
ax4.axvline(x=880, color="red", linestyle="--", alpha=0.7, label="880 Hz (A5)")
ax4.legend()
plt.tight_layout()
plt.savefig("output/audio_visualization.png", dpi=150, bbox_inches="tight")
plt.show()
print("Audio visualization saved.")Understanding the Spectrogram
The spectrogram is the most important visual and computational representation of audio. Instead of showing amplitude over time (waveform), it shows frequency content over time.
How a Spectrogram Is Computed
The process uses the Short-Time Fourier Transform (STFT):
- Window the signal: Divide the audio into short overlapping frames (typically 25ms window, 10ms hop)
- Apply FFT to each frame: Convert each time frame from time domain to frequency domain
- Stack the results: Each frame becomes one column in the spectrogram — time on x-axis, frequency on y-axis, intensity (color) shows magnitude
import librosa
import numpy as np
# STFT parameters
n_fft = 2048 # FFT window size (samples) — frequency resolution
hop_length = 512 # Hop between frames (samples) — time resolution
win_length = None # Window length (None = same as n_fft)
# Compute STFT
D = librosa.stft(y, n_fft=n_fft, hop_length=hop_length)
print(f"STFT shape: {D.shape}")
# (1 + n_fft//2, n_frames)
# = (1025, ~129) for a 3-second clip at 22050 Hz
# Rows = frequency bins; Columns = time frames
print(f"Number of frequency bins: {D.shape[0]}")
print(f"Number of time frames: {D.shape[1]}")
# Frequency resolution: how many Hz per frequency bin
freq_resolution = sr / n_fft
print(f"Frequency resolution: {freq_resolution:.2f} Hz per bin")
# Time resolution: how many ms per hop
time_resolution = hop_length / sr * 1000
print(f"Time resolution: {time_resolution:.1f} ms per frame")
# The fundamental tradeoff: larger n_fft → better frequency resolution
# but worse time resolution. For speech: n_fft=512 (fast events);
# for music analysis: n_fft=2048+ (harmonic structure)The Mel Scale: Matching Human Perception
The standard STFT uses linear frequency spacing, but human hearing is logarithmic — we’re much more sensitive to frequency differences at low frequencies than high frequencies. The Mel scale warps the frequency axis to match human perception:
import librosa
import numpy as np
# Mel spectrogram: STFT projected onto perceptual Mel frequency scale
mel_spec = librosa.feature.melspectrogram(
y=y,
sr=sr,
n_mels=128, # Number of Mel frequency bins (typical: 64-128)
n_fft=2048, # FFT window size
hop_length=512, # Hop between frames
fmin=20, # Minimum frequency (Hz) — below human hearing
fmax=8000 # Maximum frequency — 8kHz captures most speech
)
print(f"Mel spectrogram shape: {mel_spec.shape}")
# (128, n_frames) — 128 Mel bands × time frames
# Convert to decibels (log scale for better visual contrast)
mel_db = librosa.power_to_db(mel_spec, ref=np.max)
# The Mel spectrogram is typically used as input to CNNs for audio classification
# It's the "image" of the audio — CNNs treat it like any other 2D imageMFCCs: The Standard Audio Feature
Mel-Frequency Cepstral Coefficients (MFCCs) are the most widely used feature representation for audio data science, particularly for speech. They compress the key information from the Mel spectrogram into a compact vector.
Computing MFCCs
import librosa
import numpy as np
import pandas as pd
# Compute MFCCs
mfccs = librosa.feature.mfcc(
y=y,
sr=sr,
n_mfcc=13, # Number of MFCC coefficients (typically 13-40)
n_fft=2048,
hop_length=512
)
print(f"MFCC matrix shape: {mfccs.shape}")
# (n_mfcc, n_frames) = (13, ~129)
# Delta MFCCs: how MFCCs change over time (velocity)
delta_mfccs = librosa.feature.delta(mfccs)
# Delta-delta MFCCs: acceleration
delta2_mfccs = librosa.feature.delta(mfccs, order=2)
print(f"Delta MFCC shape: {delta_mfccs.shape}")
print(f"Delta² MFCC shape: {delta2_mfccs.shape}")
# Standard feature vector: concatenate MFCCs + deltas + delta-deltas
# This gives 39 features (13 × 3) per time frame
all_features = np.vstack([mfccs, delta_mfccs, delta2_mfccs])
print(f"Full feature matrix: {all_features.shape}") # (39, n_frames)
def extract_audio_features_summary(
y: np.ndarray,
sr: int,
n_mfcc: int = 13
) -> np.ndarray:
"""
Extract a fixed-length summary feature vector from an audio clip.
Aggregates MFCC and other spectral features over time
by computing statistics (mean, std, min, max) per coefficient.
This converts variable-length audio into a fixed-length vector
suitable for standard ML classifiers.
Parameters
----------
y : np.ndarray
Audio waveform (mono, float32).
sr : int
Sample rate.
n_mfcc : int
Number of MFCC coefficients.
Returns
-------
np.ndarray
Fixed-length feature vector (4 × (n_mfcc × 3) + spectral features).
"""
features = {}
# MFCCs + deltas + delta-deltas
mfcc = librosa.feature.mfcc(y=y, sr=sr, n_mfcc=n_mfcc)
delta_mfcc = librosa.feature.delta(mfcc)
delta2_mfcc = librosa.feature.delta(mfcc, order=2)
for name, coefs in [("mfcc", mfcc), ("dmfcc", delta_mfcc), ("d2mfcc", delta2_mfcc)]:
features[f"{name}_mean"] = coefs.mean(axis=1) # Mean over time
features[f"{name}_std"] = coefs.std(axis=1) # Std over time
features[f"{name}_max"] = coefs.max(axis=1)
features[f"{name}_min"] = coefs.min(axis=1)
# Spectral features
spectral_centroid = librosa.feature.spectral_centroid(y=y, sr=sr)[0]
spectral_bandwidth= librosa.feature.spectral_bandwidth(y=y, sr=sr)[0]
spectral_rolloff = librosa.feature.spectral_rolloff(y=y, sr=sr)[0]
zero_crossing_rate= librosa.feature.zero_crossing_rate(y)[0]
rms_energy = librosa.feature.rms(y=y)[0]
for name, feat in [
("spec_centroid", spectral_centroid),
("spec_bandwidth", spectral_bandwidth),
("spec_rolloff", spectral_rolloff),
("zcr", zero_crossing_rate),
("rms", rms_energy),
]:
features[f"{name}_mean"] = np.array([feat.mean()])
features[f"{name}_std"] = np.array([feat.std()])
# Chroma features (pitch class profiles)
chroma = librosa.feature.chroma_stft(y=y, sr=sr, n_chroma=12)
features["chroma_mean"] = chroma.mean(axis=1)
features["chroma_std"] = chroma.std(axis=1)
# Mel spectrogram statistics
mel = librosa.feature.melspectrogram(y=y, sr=sr, n_mels=40)
mel_db = librosa.power_to_db(mel, ref=np.max)
features["mel_mean"] = mel_db.mean(axis=1)
features["mel_std"] = mel_db.std(axis=1)
# Concatenate all into one vector
return np.concatenate([v.flatten() for v in features.values()])
# Extract features from a single clip
feature_vector = extract_audio_features_summary(y, sr)
print(f"\nFeature vector length: {len(feature_vector)}")Audio Feature Reference
# Complete reference of librosa features useful for data science
import librosa
import numpy as np
def extract_all_librosa_features(y: np.ndarray, sr: int) -> dict:
"""
Extract all major librosa features with brief descriptions.
Returns dict of {feature_name: array_or_value}.
"""
features = {}
# ── Temporal features ──────────────────────────────────────────
# Zero Crossing Rate: how often the signal crosses zero
# High ZCR → noisy, percussive sounds; Low ZCR → tonal sounds
features["zero_crossing_rate"] = librosa.feature.zero_crossing_rate(y)[0]
# RMS Energy: root mean square energy per frame
# Loudness proxy — useful for detecting silence and loud events
features["rms"] = librosa.feature.rms(y=y)[0]
# ── Spectral features ──────────────────────────────────────────
# Spectral Centroid: "center of mass" of the spectrum
# Bright sounds (high freq) → high centroid; dark sounds → low centroid
features["spectral_centroid"] = librosa.feature.spectral_centroid(y=y, sr=sr)[0]
# Spectral Bandwidth: spread of frequencies around the centroid
# Narrow bandwidth → pure tone; Wide bandwidth → noise or complex sound
features["spectral_bandwidth"] = librosa.feature.spectral_bandwidth(y=y, sr=sr)[0]
# Spectral Rolloff: frequency below which 85% of energy is concentrated
# Distinguishes harmonic vs. percussive sounds
features["spectral_rolloff"] = librosa.feature.spectral_rolloff(y=y, sr=sr)[0]
# Spectral Contrast: energy difference between peaks and valleys
# Useful for music/speech discrimination
features["spectral_contrast"] = librosa.feature.spectral_contrast(y=y, sr=sr)
# ── Cepstral features ──────────────────────────────────────────
# MFCCs: compact perceptual representation of the spectrum
# Most important feature for speech and audio classification
features["mfcc"] = librosa.feature.mfcc(y=y, sr=sr, n_mfcc=13)
# ── Rhythmic features ──────────────────────────────────────────
# Tempo: estimated beats per minute
tempo, _ = librosa.beat.beat_track(y=y, sr=sr)
features["tempo"] = np.array([tempo])
# ── Pitch/Harmonic features ────────────────────────────────────
# Chroma Features: energy in each of 12 pitch classes
# Represents harmonic and melodic content
features["chroma_stft"] = librosa.feature.chroma_stft(y=y, sr=sr)
# Chroma CENS: normalized, more robust to tempo/dynamics changes
features["chroma_cens"] = librosa.feature.chroma_cens(y=y, sr=sr)
# Harmonic/Percussive separation
y_harmonic, y_percussive = librosa.effects.hpss(y)
features["harmonic_ratio"] = np.array([
np.mean(np.abs(y_harmonic)) / (np.mean(np.abs(y)) + 1e-10)
])
# Tonnetz: tonal centroid features
y_harm_for_tonnetz = librosa.effects.harmonic(y)
features["tonnetz"] = librosa.feature.tonnetz(
y=y_harm_for_tonnetz, sr=sr
)
return features
# Demonstrate on our synthetic tone
feature_dict = extract_all_librosa_features(y, sr)
print("Feature shapes:")
for name, feat in feature_dict.items():
shape = feat.shape if hasattr(feat, "shape") else "scalar"
summary = f"mean={feat.mean():.3f}" if hasattr(feat, "mean") else str(feat)
print(f" {name:25s}: {str(shape):15s} | {summary}")Audio Classification Pipeline
Combining feature extraction with a standard sklearn classifier:
import os
import numpy as np
import pandas as pd
import librosa
from pathlib import Path
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler, LabelEncoder
from sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import cross_val_score, StratifiedKFold
from sklearn.metrics import classification_report
import warnings
warnings.filterwarnings("ignore")
def load_audio_dataset(
audio_dir: str,
sr: int = 22050,
duration: float = None,
max_files_per_class: int = None
) -> tuple:
"""
Load an audio dataset from a class-folder directory structure.
audio_dir/
class_a/ (e.g., 'dog_bark', 'car_horn', 'speech')
sound001.wav
sound002.wav
class_b/
sound003.wav
Parameters
----------
audio_dir : str
Root directory with class subdirectories.
sr : int
Sample rate to load all audio at (resamples if needed).
duration : float, optional
Clip duration in seconds. Truncate/pad to this length.
max_files_per_class : int, optional
Maximum files to load per class (for balanced datasets).
Returns
-------
tuple
(features_matrix, labels_array, class_names)
"""
audio_dir_path = Path(audio_dir)
class_dirs = sorted([d for d in audio_dir_path.iterdir() if d.is_dir()])
class_names = [d.name for d in class_dirs]
le = LabelEncoder()
le.fit(class_names)
all_features, all_labels = [], []
audio_extensions = {".wav", ".mp3", ".flac", ".ogg", ".m4a"}
for class_dir in class_dirs:
class_files = [
f for f in class_dir.iterdir()
if f.suffix.lower() in audio_extensions
]
if max_files_per_class:
class_files = class_files[:max_files_per_class]
print(f" {class_dir.name}: {len(class_files)} files")
for filepath in class_files:
try:
# Load audio
y_clip, _ = librosa.load(str(filepath), sr=sr, duration=duration)
# Pad if shorter than target duration
if duration:
target_samples = int(duration * sr)
if len(y_clip) < target_samples:
y_clip = np.pad(y_clip, (0, target_samples - len(y_clip)))
else:
y_clip = y_clip[:target_samples]
# Extract features
feat_vector = extract_audio_features_summary(y_clip, sr)
all_features.append(feat_vector)
all_labels.append(class_dir.name)
except Exception as e:
print(f" Skipped {filepath.name}: {e}")
features_matrix = np.array(all_features)
labels_encoded = le.transform(all_labels)
print(f"\nDataset shape: {features_matrix.shape}")
print(f"Classes: {class_names}")
print(f"Samples per class: {pd.Series(all_labels).value_counts().to_dict()}")
return features_matrix, labels_encoded, class_names
def train_audio_classifier(
features: np.ndarray,
labels: np.ndarray,
class_names: list,
classifier: str = "random_forest"
) -> dict:
"""Train and cross-validate an audio classifier."""
classifiers = {
"logistic": LogisticRegression(C=1.0, max_iter=500, random_state=42),
"random_forest":RandomForestClassifier(n_estimators=100, random_state=42, n_jobs=-1),
"gradient_boost":GradientBoostingClassifier(n_estimators=100, random_state=42),
}
pipeline = Pipeline([
("scaler", StandardScaler()),
("clf", classifiers[classifier])
])
# Stratified cross-validation
cv = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)
cv_scores = cross_val_score(pipeline, features, labels, cv=cv,
scoring="accuracy", n_jobs=-1)
pipeline.fit(features, labels) # Fit final model on all data
print(f"\nAudio classifier: {classifier}")
print(f"CV accuracy: {cv_scores.mean():.3f} ± {cv_scores.std():.3f}")
print(f"CV scores: {np.round(cv_scores, 3)}")
return {
"model": pipeline,
"cv_mean": cv_scores.mean(),
"cv_std": cv_scores.std(),
"class_names": class_names
}
def predict_audio_file(model_info: dict, filepath: str, sr: int = 22050) -> dict:
"""Predict the class of a single audio file."""
model = model_info["model"]
y, _ = librosa.load(filepath, sr=sr)
features = extract_audio_features_summary(y, sr).reshape(1, -1)
class_idx = model.predict(features)[0]
class_probs = model.predict_proba(features)[0]
class_name = model_info["class_names"][class_idx]
result = {
"predicted_class": class_name,
"confidence": float(class_probs.max()),
"all_probs": dict(zip(model_info["class_names"], class_probs.tolist()))
}
print(f"Prediction: {class_name} (confidence: {class_probs.max():.3f})")
return resultAudio Preprocessing Techniques
import librosa
import numpy as np
def normalize_audio(y: np.ndarray, method: str = "peak") -> np.ndarray:
"""
Normalize audio amplitude.
Parameters
----------
method : str
'peak': normalize so the max absolute value is 1.0
'rms': normalize to a target RMS level
"""
if method == "peak":
peak = np.max(np.abs(y))
return y / (peak + 1e-10)
elif method == "rms":
target_rms = 0.1
current_rms = np.sqrt(np.mean(y**2))
return y * (target_rms / (current_rms + 1e-10))
return y
def remove_silence(
y: np.ndarray,
sr: int,
top_db: float = 20.0,
pad_ms: int = 50
) -> np.ndarray:
"""
Remove silent regions from audio.
Parameters
----------
y : np.ndarray
Input audio waveform.
sr : int
Sample rate.
top_db : float
Silence threshold in dB below the loudest part.
Lower values = more aggressive silence removal.
pad_ms : int
Milliseconds of audio to keep before/after voiced segments.
"""
# Get intervals of non-silent audio
intervals = librosa.effects.split(y, top_db=top_db)
pad_samples = int(pad_ms * sr / 1000)
segments = []
for start, end in intervals:
# Add padding around each voiced segment
padded_start = max(0, start - pad_samples)
padded_end = min(len(y), end + pad_samples)
segments.append(y[padded_start:padded_end])
if not segments:
return y # All silence — return original
return np.concatenate(segments)
def apply_noise_reduction(y: np.ndarray, noise_factor: float = 0.1) -> np.ndarray:
"""
Simple noise reduction using spectral subtraction.
Estimates noise from the quietest parts of the recording
and subtracts it from the full spectrum.
"""
D = librosa.stft(y)
magnitude = np.abs(D)
phase = np.angle(D)
# Estimate noise floor from lowest-energy frames
frame_energy = magnitude.mean(axis=0)
quiet_frames = frame_energy < np.percentile(frame_energy, 15)
noise_estimate = magnitude[:, quiet_frames].mean(axis=1, keepdims=True)
# Spectral subtraction
denoised_magnitude = np.maximum(
magnitude - noise_factor * noise_estimate,
0.01 * magnitude # Keep small residual to avoid musical noise
)
D_denoised = denoised_magnitude * np.exp(1j * phase)
return librosa.istft(D_denoised, length=len(y))
def pad_or_trim(y: np.ndarray, sr: int, target_duration: float) -> np.ndarray:
"""
Ensure audio is exactly target_duration seconds long.
Pads with zeros if too short, trims if too long.
"""
target_samples = int(target_duration * sr)
if len(y) > target_samples:
return y[:target_samples]
elif len(y) < target_samples:
return np.pad(y, (0, target_samples - len(y)))
return ySpeech-to-Text with Whisper
OpenAI’s Whisper model provides state-of-the-art speech transcription across 100+ languages:
import whisper
import json
def transcribe_audio(
filepath: str,
model_size: str = "base", # 'tiny', 'base', 'small', 'medium', 'large'
language: str = None, # None = auto-detect
task: str = "transcribe" # 'transcribe' or 'translate' (to English)
) -> dict:
"""
Transcribe an audio file using OpenAI Whisper.
Parameters
----------
filepath : str
Path to audio file (supports WAV, MP3, M4A, FLAC, etc.)
model_size : str
Whisper model size: tiny (39M params, fastest) to large (1.5B, most accurate).
language : str, optional
Language code (e.g., 'en', 'es', 'fr'). None = auto-detect.
task : str
'transcribe' for same-language, 'translate' to translate to English.
Returns
-------
dict
Transcription result with text, segments, and language.
"""
print(f"Loading Whisper {model_size} model...")
model = whisper.load_model(model_size)
print(f"Transcribing: {filepath}")
result = model.transcribe(
filepath,
language=language,
task=task,
verbose=False
)
print(f"\nDetected language: {result['language']}")
print(f"Full transcription:")
print(result["text"])
if result.get("segments"):
print(f"\nWord-level timestamps ({len(result['segments'])} segments):")
for segment in result["segments"][:5]: # Show first 5
print(f" [{segment['start']:5.1f}s - {segment['end']:5.1f}s] "
f"{segment['text'].strip()}")
return result
def batch_transcribe_directory(
audio_dir: str,
output_jsonl: str,
model_size: str = "base",
extensions: tuple = (".wav", ".mp3", ".m4a", ".flac")
) -> list:
"""
Batch transcribe all audio files in a directory.
Saves results as JSONL for downstream processing.
"""
from pathlib import Path
import json
audio_dir_path = Path(audio_dir)
audio_files = [
f for f in audio_dir_path.rglob("*")
if f.suffix.lower() in extensions
]
print(f"Found {len(audio_files)} audio files to transcribe")
model = whisper.load_model(model_size)
results = []
with open(output_jsonl, "w") as out_f:
for i, filepath in enumerate(audio_files):
print(f"[{i+1}/{len(audio_files)}] {filepath.name}")
try:
result = model.transcribe(str(filepath), verbose=False)
record = {
"filepath": str(filepath),
"filename": filepath.name,
"language": result["language"],
"text": result["text"].strip(),
"n_segments": len(result.get("segments", [])),
"duration_s": result["segments"][-1]["end"]
if result.get("segments") else None
}
out_f.write(json.dumps(record) + "\n")
results.append(record)
except Exception as e:
print(f" Error: {e}")
print(f"\nTranscriptions saved to: {output_jsonl}")
return resultsAudio Anomaly Detection
Detecting unusual sounds in industrial or environmental monitoring:
import numpy as np
import pandas as pd
from sklearn.preprocessing import StandardScaler
from sklearn.ensemble import IsolationForest
from sklearn.decomposition import PCA
import librosa
def build_audio_anomaly_detector(
normal_audio_files: list,
sr: int = 22050,
contamination: float = 0.05
) -> dict:
"""
Build an anomaly detector from a set of 'normal' audio recordings.
Trains on features from known-normal audio (e.g., healthy machinery)
and flags deviations as anomalies (e.g., bearing failures, unusual sounds).
Parameters
----------
normal_audio_files : list
Paths to audio files representing normal (non-anomalous) conditions.
sr : int
Sample rate.
contamination : float
Expected proportion of anomalies (used to set decision threshold).
Returns
-------
dict
Trained detector and preprocessing components.
"""
print(f"Building anomaly detector from {len(normal_audio_files)} normal recordings...")
features_list = []
for filepath in normal_audio_files:
try:
y, _ = librosa.load(filepath, sr=sr)
feat = extract_audio_features_summary(y, sr)
features_list.append(feat)
except Exception as e:
print(f" Skipped {filepath}: {e}")
features = np.array(features_list)
# Preprocess
scaler = StandardScaler()
X_scaled = scaler.fit_transform(features)
# Dimensionality reduction (optional, helps with high-dimensional features)
n_components = min(50, X_scaled.shape[0] - 1, X_scaled.shape[1])
pca = PCA(n_components=n_components, random_state=42)
X_pca = pca.fit_transform(X_scaled)
# Train anomaly detector
detector = IsolationForest(
n_estimators=100,
contamination=contamination,
random_state=42,
n_jobs=-1
)
detector.fit(X_pca)
print(f"Feature dim: {features.shape[1]} → PCA: {n_components}")
print(f"Detector trained on {len(features)} normal recordings")
return {
"detector": detector,
"scaler": scaler,
"pca": pca,
"sr": sr
}
def score_audio_anomaly(detector_info: dict, filepath: str) -> dict:
"""
Score a single audio file for anomaly likelihood.
Returns a score where lower = more anomalous.
Score < 0 typically indicates an anomaly.
"""
y, _ = librosa.load(filepath, sr=detector_info["sr"])
feat = extract_audio_features_summary(y, detector_info["sr"])
X = detector_info["scaler"].transform(feat.reshape(1, -1))
X_pca = detector_info["pca"].transform(X)
score = detector_info["detector"].score_samples(X_pca)[0]
is_anomaly = detector_info["detector"].predict(X_pca)[0] == -1
return {
"filepath": filepath,
"score": float(score),
"is_anomaly": bool(is_anomaly),
"label": "ANOMALY" if is_anomaly else "Normal"
}Audio Processing Best Practices
Common Pitfalls
# ── 1. Always check sample rate consistency ───────────────────────
y1, sr1 = librosa.load("file1.wav")
y2, sr2 = librosa.load("file2.wav")
if sr1 != sr2:
# Resample to a common rate before processing
y2 = librosa.resample(y2, orig_sr=sr2, target_sr=sr1)
print(f"Resampled file2 from {sr2}Hz to {sr1}Hz")
# ── 2. Handle stereo vs. mono consistently ───────────────────────
y, sr = librosa.load("audio.wav", mono=True) # Always mono for features
# Or if loaded as stereo:
if y.ndim > 1:
y = y.mean(axis=0) # Convert stereo to mono by averaging
# ── 3. Be aware of very short files ──────────────────────────────
min_duration_s = 0.5 # Features need at least 0.5s of audio
if librosa.get_duration(y=y, sr=sr) < min_duration_s:
print(f"Warning: audio too short ({librosa.get_duration(y=y, sr=sr):.2f}s)")
y = np.pad(y, (0, int(min_duration_s * sr) - len(y)))
# ── 4. Normalize before feature extraction ───────────────────────
y_normalized = librosa.util.normalize(y) # Peak normalization to [-1, 1]
# ── 5. Check for clipping (distortion) ───────────────────────────
clipped_fraction = (np.abs(y) >= 0.99).mean()
if clipped_fraction > 0.01:
print(f"Warning: {clipped_fraction:.1%} of samples are clipped")Summary
Audio data opens a rich analytical dimension for data scientists — from call center analytics and industrial monitoring to music analysis and accessibility tools. The key conceptual shift from tabular or image data is that audio information lives in the frequency domain over time, not the amplitude domain. Raw waveforms are rarely analyzed directly; instead, the STFT and Mel spectrogram transform them into 2D time-frequency representations, from which MFCCs provide the most compact and perceptually meaningful features.
The practical workflow: load with Librosa at a consistent sample rate, preprocess (normalize, remove silence, ensure consistent length), extract features (MFCCs + deltas + spectral features aggregated to statistics), and train a standard sklearn classifier. For speech, Whisper provides state-of-the-art transcription that opens the door to text analytics on spoken content. For industrial monitoring, the same CNN feature extraction approach used for images — treating spectrograms as images — provides powerful anomaly detection.
Audio data science is an area where relatively modest expertise yields valuable capabilities — few data scientists work with audio, which makes the skill genuinely differentiating.
Key Takeaways
- Audio is a time-series of amplitude samples at a fixed sample rate (Hz): 16,000 Hz for speech recognition, 44,100 Hz for music — always resample to a consistent rate before analysis
- The spectrogram (STFT) transforms the waveform into a time-frequency representation that reveals which frequencies are active when — it’s the fundamental “visualization” and “image” of audio data
- The Mel spectrogram warps the frequency axis to match human perceptual sensitivity (logarithmic, more sensitive at low frequencies) — it is the standard input format for audio deep learning models
- MFCCs (Mel-Frequency Cepstral Coefficients, typically 13-40) are the most widely used compact feature for audio classification, especially speech — always compute them alongside their delta (velocity) and delta-delta (acceleration) coefficients
- The standard ML pipeline is: load with
librosa.load()→ preprocess (normalize, remove silence, pad/trim) → extract features withextract_audio_features_summary()→ trainStandardScaler + RandomForestorLogisticRegression→ evaluate with stratified cross-validation - OpenAI Whisper provides state-of-the-art speech transcription in three lines:
model = whisper.load_model("base"); result = model.transcribe("audio.wav"); print(result["text"])— supports 100+ languages with automatic language detection - For industrial anomaly detection, train an Isolation Forest on MFCCs from known-normal recordings; any recording whose features deviate significantly from the normal distribution is flagged as anomalous
- Critical pitfalls: always convert stereo to mono before feature extraction, always verify sample rates match when comparing recordings, and always check for audio clipping (saturated recordings) which corrupt MFCC features