Measures of central tendency are essential statistical tools used to summarize and describe the central position of a dataset. These measures provide valuable insights into the data’s distribution and are widely applied in various fields, including business, healthcare, education, and social sciences. The three primary measures of central tendency are mean, median, and mode. Each of these offers unique perspectives on the data, making them indispensable for effective data analysis.
In this article, we will explore the definitions, calculations, and practical applications of these measures, helping you understand their importance and when to use them.
What Are Measures of Central Tendency?
Measures of central tendency aim to identify the “center” or “average” value of a dataset. This central value represents a typical or representative observation that summarizes the dataset. These measures help simplify complex datasets, making them easier to interpret and analyze.
The three main measures of central tendency are:
- Mean (Average): The arithmetic average of a dataset.
- Median: The middle value when the data is ordered.
- Mode: The most frequently occurring value(s) in the dataset.
Understanding how and when to use each measure is crucial, as they can provide different insights depending on the data’s characteristics.
1. Mean: The Arithmetic Average
The mean is the most commonly used measure of central tendency. It is calculated by dividing the sum of all values in the dataset by the total number of values.
Formula for Mean:
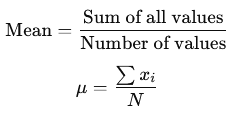
Where:
- μ: Mean
- xi: Individual data values
- N: Total number of values
Example:
Consider the dataset: [4, 8, 6, 5, 9].
- Sum of values: 4 + 8 + 6 + 5 + 9 = 32
- Number of values: 5
- Mean: μ = 32 / 5 = 6.4
Strengths of the Mean:
- It considers all data points, providing a comprehensive summary.
- Useful for datasets with values that are evenly distributed.
Limitations of the Mean:
- Sensitive to outliers (extremely high or low values) that can skew the result.
- May not represent the data well if the distribution is highly skewed.
2. Median: The Middle Value
The median represents the middle value of a dataset when the values are arranged in ascending or descending order. If the dataset has an odd number of values, the median is the central value. For an even number of values, it is the average of the two middle values.
Steps to Calculate the Median:
- Arrange the data in ascending order.
- Identify the middle value:
- If N is odd, the median is the middle value.
- If N is even, the median is the mean of the two middle values.
Example 1: Odd Number of Values
Dataset: [7, 3, 9, 1, 5]
- Arrange in ascending order: [1, 3, 5, 7, 9]
- Median: 5 (middle value)
Example 2: Even Number of Values
Dataset: [10, 2, 6, 8]
- Arrange in ascending order: [2, 6, 8, 10]
- Median: (6+8) / 2 = 7
Strengths of the Median:
- Not affected by outliers, making it robust for skewed data.
- Ideal for ordinal data or datasets with extreme values.
Limitations of the Median:
- Ignores the magnitude of other values in the dataset.
- Less informative for datasets with symmetrical distributions.
3. Mode: The Most Frequent Value
The mode is the value that occurs most frequently in a dataset. A dataset can have:
- One mode (Unimodal): Only one value appears most frequently.
- Two modes (Bimodal): Two values appear with the same highest frequency.
- No mode: No value repeats.
Example 1: Unimodal Dataset
Dataset: [3, 5, 7, 5, 9, 5]
- Mode: 5 (appears 3 times)
Example 2: Bimodal Dataset
Dataset: [4, 6, 6, 8, 8, 10]
- Modes: 6 and 8 (both appear 2 times)
Strengths of the Mode:
- The only measure suitable for categorical data (e.g., colors, preferences).
- Simple to calculate and interpret.
Limitations of the Mode:
- May not provide meaningful insight for datasets with no or multiple modes.
- Less commonly used for numerical data.
Comparison of Mean, Median, and Mode
| Measure | Key Feature | Best Used When… |
|---|---|---|
| Mean | Considers all data points | Data is symmetrically distributed without outliers. |
| Median | Middle value of an ordered dataset | Data has outliers or is skewed. |
| Mode | Most frequently occurring value | Data is categorical or has repeated values. |
Choosing the Right Measure of Central Tendency
Different datasets require different measures of central tendency to accurately represent their central value. Here are guidelines to help you choose the most appropriate measure based on the characteristics of the data:
1. Symmetrical Distributions
When the data is evenly distributed, and there are no significant outliers, the mean is usually the best choice.
Example: Consider the dataset [10, 12, 14, 16, 18], which is symmetrically distributed. The mean, median, and mode all yield the same result (14), making the mean a reliable measure.
2. Skewed Distributions
For datasets with skewness or extreme outliers, the median is often more representative of the central value.
Example: Dataset: [15, 18, 22, 28, 150]
- Mean: (15 + 18 + 22 + 28 + 150) / 5 = 46.6
- Median: 22
The mean is significantly influenced by the outlier 150, while the median remains unaffected, providing a more accurate representation of the dataset.
3. Categorical Data
When working with categorical data, the mode is the only suitable measure, as mean and median are not meaningful.
Example: Dataset: [“Red”, “Blue”, “Blue”, “Green”, “Red”, “Blue”]
- Mode: “Blue” (appears 3 times)
4. Multi-modal Data
For datasets with multiple peaks, the mode is helpful for identifying all frequently occurring values.
Example: Dataset: [2, 4, 4, 6, 8, 8, 10]
- Modes: 4 and 8
The mode highlights the bimodal nature of the data.
Summary of When to Use Each Measure
| Measure | Best Used When… |
|---|---|
| Mean | Data is continuous, symmetrical, and free of outliers. |
| Median | Data is skewed or contains outliers. |
| Mode | Data is categorical or contains repeated values (e.g., multi-modal). |
Practical Applications of Measures of Central Tendency
Measures of central tendency are applied across various fields to summarize data, identify trends, and support decision-making. Let’s explore real-world scenarios for each measure.
1. Applications of Mean
- Finance: Calculating the average return on investment (ROI) across multiple portfolios.
- Example: A mutual fund uses the mean ROI to assess performance over five years.
- Education: Determining the average test score of a class to evaluate overall performance.
- Example: The mean score of a math test helps teachers assess the class’s understanding.
- Healthcare: Analyzing average patient wait times in hospitals to optimize resources.
2. Applications of Median
- Real Estate: Estimating the central tendency of property prices in a neighborhood.
- Example: The median house price avoids distortion from extremely high-value properties.
- Income Analysis: Reporting the median income of households to avoid skewing by high earners.
- Example: A government agency uses the median income to assess economic inequality.
- Weather Forecasting: Summarizing daily temperatures in regions with significant fluctuations.
3. Applications of Mode
- Retail: Identifying the most frequently purchased product in a store.
- Example: A supermarket uses the mode to determine the most popular brand of coffee.
- Healthcare: Analyzing the most common diagnosis among patients.
- Example: The mode helps prioritize resources for the most frequently occurring conditions.
- Marketing: Identifying the most popular customer preferences in a survey.
Impact of Data Distribution on Central Tendency
The choice of measure is closely tied to the data distribution. Understanding how distributions affect central tendency is critical for meaningful analysis.
1. Symmetrical Distribution
In a perfectly symmetrical distribution (e.g., normal distribution), the mean, median, and mode are equal and located at the center of the distribution.
Example: Dataset: [5, 10, 15, 20, 25]
- Mean: 15
- Median: 15
- Mode: 15
2. Skewed Distribution
In a skewed distribution, the mean, median, and mode are not equal:
- Positively Skewed: The mean is greater than the median, which is greater than the mode.
- Example: High-income earners in a population dataset create positive skew.
- Negatively Skewed: The mean is less than the median, which is less than the mode.
- Example: Exam scores where a majority of students perform well, but a few score very low.
3. Uniform Distribution
In a uniform distribution, all values occur with equal frequency. The mean and median are the same, but there may be no mode.
Example: Dataset: [2, 4, 6, 8, 10]
- Mean: 6
- Median: 6
- Mode: None
4. Multi-modal Distribution
For datasets with multiple peaks, the mode identifies the most frequent values, while the mean and median may not capture the data’s multi-modal nature.
Example: Dataset: [1, 1, 3, 3, 5, 5, 7]
- Modes: 1, 3, 5
- Median: 3
- Mean: 3.57
Interpreting Central Tendency in Context
Measures of central tendency provide a snapshot of the data, but their true value lies in how they are applied and interpreted within specific contexts. Let’s discuss how to use these measures effectively in real-world scenarios:
1. Context-Specific Relevance
The relevance of mean, median, or mode depends on the type of data and the question being addressed:
- Business Insights: The mean is often used to calculate averages, such as revenue per customer, but the median might be more insightful in identifying typical customer spending when the data contains outliers.
- Public Policy: Governments use median income rather than mean income to understand economic disparities, as the median is less affected by extreme wealth at the top of the income distribution.
- Healthcare: While the mode might be used to identify the most common diagnosis, the mean and median can provide insights into the average or typical patient outcomes.
2. Using Central Tendency with Other Metrics
Central tendency should rarely be used in isolation. Pairing these measures with additional metrics can yield deeper insights:
- Range and Variance: Understanding the spread of data complements the central tendency. For example, two datasets with the same mean can have vastly different variances.
- Quartiles and Percentiles: The median is part of a broader analysis involving quartiles (e.g., 25th and 75th percentiles) to understand the spread and concentration of data.
Example: For student test scores:
- Mean: 75
- Median: 80
- Variance: 150
The high variance suggests that while the average score is 75, individual scores vary significantly, making the median (80) a better representation of typical performance.
Common Pitfalls When Using Measures of Central Tendency
While measures of central tendency are powerful tools, they can mislead if applied incorrectly. Here are some common pitfalls to avoid:
1. Ignoring Outliers
Outliers can disproportionately affect the mean, leading to an inaccurate representation of the data.
Example: Dataset: [10, 12, 14, 16, 100]
- Mean: 30.4
- Median: 14
The mean suggests a central value of 30.4, which is not representative of most data points. The median is more robust in this case.
2. Misinterpreting Mode
The mode may not always provide meaningful insights, especially in datasets with no or multiple modes.
Example: Dataset: [1, 2, 3, 4, 5, 6, 7]
- Mode: None
- Mean: 4
- Median: 4
In this dataset, the mode is uninformative, while the mean and median provide meaningful central values.
3. Over-Reliance on a Single Measure
Using only one measure can lead to oversimplified conclusions. A dataset with the same mean and median might have different modes, indicating hidden patterns.
Example: Dataset A: [5, 5, 5, 5, 5] (mean = median = mode = 5) Dataset B: [4, 5, 5, 5, 6] (mean = 5, median = 5, mode = 5)
Although the measures are the same, Dataset B has more variability, which could impact interpretation.
4. Applying the Wrong Measure
Choosing the wrong measure for the data type can misrepresent the findings. For instance:
- Using the mean for ordinal data (e.g., survey ratings) is inappropriate, as the data lacks a true numerical scale.
Combining Measures of Central Tendency
To gain a complete understanding of a dataset, consider using multiple measures together. Each measure highlights a different aspect of the data, and their combined interpretation provides a richer analysis.
1. Complementary Use of Mean and Median
The relationship between the mean and median can reveal skewness:
- Mean > Median: Positive skew (right tail is longer).
- Mean < Median: Negative skew (left tail is longer).
- Mean ≈ Median: Symmetrical distribution.
2. Adding Mode for Categorical Data
When analyzing categorical data, use the mode alongside the mean and median to understand both numerical trends and frequently occurring categories.
3. Example: Housing Prices
Dataset: Housing prices in a neighborhood: [200K, 220K, 250K, 300K, 2M]
- Mean: 594K
- Median: 250K
- Mode: None
Interpretation:
- The mean is inflated by a luxury property worth $2M.
- The median provides a better sense of a “typical” house price.
- The lack of a mode indicates no common price point in the dataset.
Using Technology to Analyze Central Tendency
Modern tools make it easy to calculate and visualize measures of central tendency. Here’s how Python and R can help:
1. Python Example
import numpy as np
data = [10, 20, 20, 30, 40, 100]
mean = np.mean(data)
median = np.median(data)
mode = max(set(data), key=data.count)
print(f"Mean: {mean}, Median: {median}, Mode: {mode}")2. R Example
data <- c(10, 20, 20, 30, 40, 100)
mean <- mean(data)
median <- median(data)
mode <- names(which.max(table(data)))
cat("Mean:", mean, "Median:", median, "Mode:", mode)These tools simplify the analysis and ensure accurate calculations, even for large datasets.
Conclusion
Measures of central tendency—mean, median, and mode—are essential tools for summarizing data. Each measure offers unique insights, and understanding their strengths and limitations is key to effective analysis. By choosing the right measure for your data and interpreting them in context, you can uncover meaningful patterns and trends.
However, relying solely on central tendency can lead to incomplete or misleading conclusions. Pair these measures with variability metrics, visualizations, and domain knowledge for a holistic analysis. Whether you’re analyzing financial trends, customer behavior, or medical outcomes, mastering these statistical tools is a crucial step in turning raw data into actionable insights.