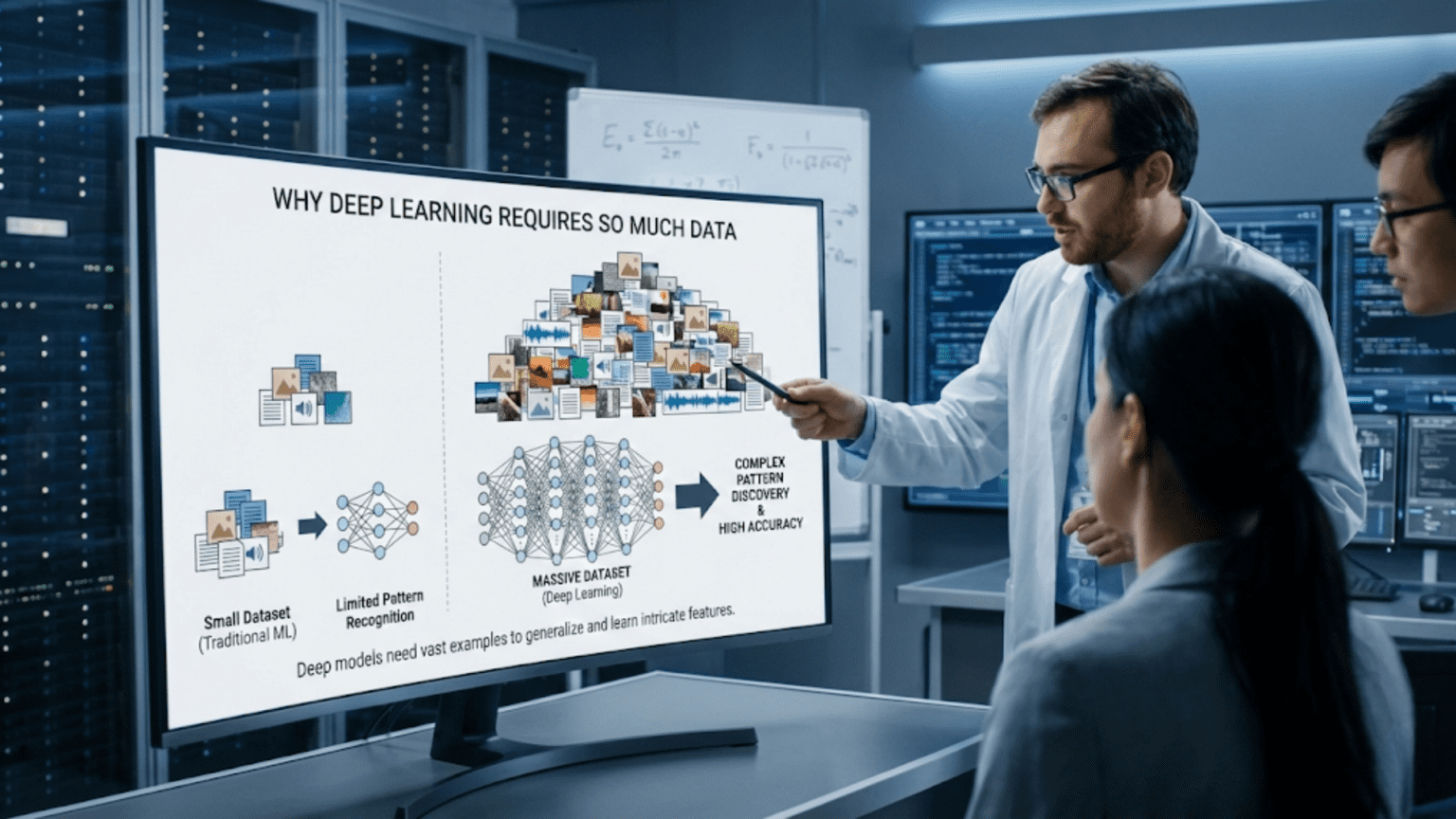
Deep learning requires large amounts of data because neural networks have millions of parameters that need sufficient examples to learn meaningful patterns rather than memorizing noise. With too little data, models overfit—performing well on training examples but failing on new data. Typical requirements range from thousands of examples for transfer learning to millions for training from scratch. The high parameter count, complex decision boundaries, and need to learn hierarchical features all contribute to deep learning’s data hunger, though techniques like data augmentation, transfer learning, and self-supervised learning can reduce requirements.
Introduction: The Data Paradox
Deep learning has achieved remarkable breakthroughs: surpassing human performance at image recognition, translating languages fluently, generating creative content, and mastering complex games. Yet this success comes with a demanding requirement: massive amounts of data. ImageNet, the dataset that sparked the deep learning revolution, contains 1.2 million labeled images. GPT-3 was trained on hundreds of billions of words. Modern computer vision models train on billions of images.
Why such enormous data requirements? Traditional machine learning often works well with thousands of examples. Statistical methods can make predictions from hundreds. Yet deep learning seemingly needs orders of magnitude more data to achieve comparable or better performance. This isn’t just an inconvenience—it’s a fundamental characteristic that shapes what problems deep learning can solve and who can apply it.
The data hunger of deep learning creates real challenges. Labeling millions of examples is expensive and time-consuming. Many valuable problems simply don’t have enough data available. Privacy concerns limit data collection. Small organizations can’t compete with tech giants who control vast datasets. Understanding why deep learning needs so much data—and how to reduce these requirements—is crucial for anyone working with AI.
This comprehensive guide explores deep learning’s data requirements from every angle. You’ll learn the fundamental reasons for data hunger, how much data different tasks require, what happens with insufficient data, techniques to train with less data, the relationship between model size and data needs, and the future of data-efficient deep learning.
The Fundamental Reasons: Why So Much Data?
Several interconnected factors create deep learning’s data requirements.
Reason 1: Millions of Parameters to Learn
The Core Issue: Modern neural networks have millions to billions of parameters (weights and biases) that must be learned from data.
Parameter Counts:
Small CNN (MNIST): ~100,000 parameters
ResNet-50 (ImageNet): ~25 million parameters
GPT-3: 175 billion parametersThe Problem:
- Each parameter needs data to learn appropriate value
- Insufficient data → parameters learn noise instead of patterns
- General rule: Need many examples per parameter
Example:
Model with 1 million parameters
Training data: 1,000 examples
Ratio: 1,000 parameters per example!
Result: Model has far more freedom (parameters) than constraints (examples)
Can memorize training data perfectly
But won't generalize to new dataThe Math:
Parameters >> Training Examples → Overfitting risk
Want: Training Examples >> Parameters
Or at least: Training Examples ~ 10 × ParametersReason 2: Learning Hierarchical Features
Deep Learning’s Power: Automatically learns features at multiple levels of abstraction
Image Recognition Example:
Layer 1: Edges, textures (thousands of edge detectors to learn)
Layer 2: Parts like corners, simple shapes (combinations of edges)
Layer 3: Object parts like wheels, eyes (combinations of shapes)
Layer 4: Complete objects (combinations of parts)Data Requirement:
- Each layer needs examples to learn its features
- Low-level features (edges) relatively simple → less data
- High-level features (object categories) complex → more data
- Learning full hierarchy → substantial data needed
Why This Needs Data:
To learn "edge detector": Need examples of edges in various orientations
To learn "wheel detector": Need examples of many types of wheels
To learn "car detector": Need examples of many cars in various contexts
Multiply across all features in all layers → large data requirementReason 3: Avoiding Overfitting
Overfitting: Learning noise in training data instead of true patterns
With Limited Data:
100 cat photos for training
Model learns:
- "Cats always on grass" (true in training set, not generally)
- "Cats are orange" (true for these examples, not all cats)
- Specific backgrounds, lighting, angles
Result: Fails on new cats in different settingsWith Abundant Data:
100,000 cat photos for training
Model sees:
- Cats on grass, concrete, carpet, furniture
- Orange, black, white, spotted, striped cats
- Various backgrounds, lighting, angles
Result: Learns general "cat-ness" not specific detailsThe Principle: More diverse examples → better generalization
Reason 4: High-Dimensional Input Spaces
Curse of Dimensionality: High-dimensional spaces require exponentially more data to cover adequately
Example: Image Data:
224×224 RGB image = 150,528 input dimensions
Possible images: 256^150,528 (astronomically large)
Even millions of images are sparse in this vast space
Need substantial data to represent space adequatelyIntuition:
1D space (line): 10 points covers reasonably
2D space (plane): 10×10 = 100 points needed
3D space (cube): 10×10×10 = 1,000 points needed
High dimensions: Need exponentially more pointsReason 5: Complex Decision Boundaries
Traditional ML: Often learns simple boundaries (linear, low-degree polynomial)
Deep Learning: Learns arbitrarily complex boundaries
Complexity Requires Data:
Simple boundary (line): Few examples suffice
• | •
• | •
Complex boundary (curved, intricate): Many examples needed
• ╱‾╲ •
•╱ ╲•Example:
Distinguishing cats vs dogs:
- Simple model: "Pointy ears → cat" (works sometimes, limited data OK)
- Deep model: Complex combination of features (needs many examples)
Deep model more accurate but needs more data to learn complexityReason 6: Learning Robust Representations
Goal: Representations that work across variations
Variations to Handle:
Images:
- Lighting (bright, dim, shadows)
- Angle (front, side, top-down)
- Scale (close-up, far away)
- Occlusion (partially hidden)
- Background (many different contexts)Data Requirement:
To handle all variations:
Need examples covering combinations
5 lighting × 5 angles × 5 scales × 3 occlusions = 375 variations
Per object category!
More variations to handle → more data neededHow Much Data Do You Actually Need?
Data requirements vary widely by task, model, and approach.
Rule of Thumb Guidelines
Traditional Machine Learning:
Linear models: 100-1,000 examples
Decision trees: 1,000-10,000 examples
Random forests: 10,000-100,000 examplesDeep Learning from Scratch:
Simple tasks (MNIST digits): 50,000-60,000 examples
Image classification (few classes): 100,000-1,000,000 examples
Complex vision (ImageNet): 1,000,000+ examples
Natural language (GPT): billions of wordsTransfer Learning (using pre-trained models):
Fine-tuning: 1,000-10,000 examples
Feature extraction: 100-1,000 examplesExamples by Domain
Computer Vision:
MNIST (handwritten digits): 60,000 training images
CIFAR-10 (objects): 50,000 images
ImageNet (1,000 categories): 1.2 million images
Instagram (image hashtag prediction): 3.5 billion imagesNatural Language Processing:
Sentiment analysis: 10,000-100,000 sentences
Machine translation: millions of sentence pairs
Language modeling (GPT-3): 300 billion tokensSpeech Recognition:
Basic recognition: 100 hours of audio
Commercial systems: 10,000+ hours
State-of-the-art: 100,000+ hoursSimple games (CartPole): thousands of episodes
Atari games: millions of frames
Go (AlphaGo): millions of self-play gamesFactors Affecting Requirements
1. Problem Complexity:
Binary classification (cat vs dog): Less data
1,000-class classification: Much more data2. Model Size:
Small network (1M parameters): Less data
Large network (100M parameters): More data3. Input Complexity:
Tabular data (10 features): Less data
High-res images (1000×1000): More data4. Data Quality:
Clean, labeled data: Fewer examples needed
Noisy, mislabeled data: More examples needed5. Starting Point:
From scratch: Maximum data
Fine-tuning: Moderate data
Transfer learning: Minimum dataWhat Happens with Insufficient Data?
Too little data creates predictable problems.
Overfitting
Symptom: Excellent training performance, poor test performance
Example:
Dataset: 100 images (50 cats, 50 dogs)
Model: ResNet-50 (25M parameters)
Training accuracy: 100%
Test accuracy: 60%
Model memorized training examples
Didn't learn generalizable patternsVisualization:
Training loss: Decreases to near zero
Validation loss: Decreases initially, then increases
Classic overfitting patternMemorization Instead of Learning
With Insufficient Data:
Model learns:
"Image #1 is a cat"
"Image #2 is a dog"
...
Not learning:
"Pointy ears and whiskers indicate cat"
"Floppy ears and snout indicate dog"Poor Generalization
Test Set Performance:
Training data distribution: 95% accuracy
Slightly different distribution: 60% accuracy
Significantly different: 40% accuracy
Model hasn't learned robust featuresHigh Variance
Symptom: Model performance very sensitive to training data
Example:
Train on 100 examples (split A): 85% test accuracy
Train on different 100 (split B): 72% test accuracy
Train on different 100 (split C): 91% test accuracy
High variance indicates insufficient dataMissing Edge Cases
Problem: Rare but important cases not in small dataset
Example:
Self-driving car trained on limited data:
- Sees many cars, pedestrians, roads
- Never sees motorcycle
- Doesn't recognize motorcycles → dangerousTechniques to Train with Less Data
Several strategies reduce data requirements.
1. Transfer Learning
Concept: Use knowledge from one task to help another
Process:
1. Pre-train on large dataset (ImageNet)
2. Fine-tune on small target dataset
Result: Need 10-100x less data for target taskExample:
Without transfer: Need 100,000 medical images
With transfer: Need 1,000-10,000 medical images
10-100x reduction!Why It Works:
- Pre-trained model already learned low-level features (edges, textures)
- Only needs to adapt high-level features to new task
- Less learning required → less data needed
2. Data Augmentation
Concept: Create variations of existing data
Image Augmentation:
Original image → Generate variations:
- Rotation (±15 degrees)
- Horizontal flip
- Zoom (±10%)
- Brightness adjustment
- Contrast adjustment
- Cropping
1 image → 10-20 augmented versions
Effectively 10-20x more dataExample:
Original dataset: 1,000 images
After augmentation: 20,000 effective images
Model sees more variations
Learns more robust featuresCode Example:
from tensorflow.keras.preprocessing.image import ImageDataGenerator
datagen = ImageDataGenerator(
rotation_range=20,
width_shift_range=0.2,
height_shift_range=0.2,
horizontal_flip=True,
zoom_range=0.2
)
# Generates augmented batches during training
datagen.fit(X_train)3. Self-Supervised Learning
Concept: Learn from unlabeled data using automatic labels
Example Tasks:
Predict rotation: Rotate image 0°, 90°, 180°, 270°, predict rotation
Predict color: Convert to grayscale, predict original colors
Predict context: Mask part of image, predict masked regionProcess:
1. Pre-train on millions of unlabeled images (free!)
2. Fine-tune on small labeled dataset
Result: Leverages unlimited unlabeled dataRecent Success: SimCLR, MoCo, BERT use self-supervised learning
4. Few-Shot Learning
Concept: Learn to learn from few examples
Approach:
Meta-learning: Train on many tasks with few examples each
Learn how to adapt quickly to new tasks
Result: New task requires only 1-10 examplesExample:
Traditional: Need 1,000 cat images to learn "cat"
Few-shot: After meta-training, need only 5 cat images5. Synthetic Data
Concept: Generate artificial training data
Methods:
Simulation (3D rendering for objects)
GANs (generate realistic images)
Rule-based generation (for text)Example:
Self-driving cars:
Simulate rare scenarios (accidents, bad weather)
Supplement real data with synthetic
Cheaper than collecting real data6. Active Learning
Concept: Intelligently select which examples to label
Process:
1. Train on small labeled set
2. Predict on large unlabeled set
3. Select most informative examples (model uncertain about)
4. Label those
5. Retrain
6. Repeat
Result: Achieve target performance with fewer labeled examplesExample:
Random labeling: Need 10,000 labels for 90% accuracy
Active learning: Need 3,000 labels for 90% accuracy
70% reduction in labeling effort7. Curriculum Learning
Concept: Train on easy examples first, gradually increase difficulty
Process:
1. Start with simple, clear examples
2. Model learns basic patterns
3. Introduce harder examples
4. Model refines understanding
Learns more efficiently from less dataThe Model Size vs. Data Size Relationship
Bigger models need more data (generally).
The Scaling Relationship
Empirical Finding: Model performance scales with both model size and data size
Pattern:
Small model + small data: Underfits
Small model + large data: Performance plateaus (model too simple)
Large model + small data: Overfits
Large model + large data: Best performanceOptimal Pairing:
1,000 examples → Small model (100K parameters)
100,000 examples → Medium model (10M parameters)
10,000,000 examples → Large model (100M+ parameters)
Match model capacity to data availabilityNeural Scaling Laws
Recent Research (OpenAI, DeepMind):
Finding: Performance predictably improves with:
- More data (D)
- Larger models (N parameters)
- More compute (C)
Relationship:
Performance ∝ (D^α × N^β × C^γ)
All three matter, but with diminishing returnsImplication:
- 10x more data → ~2-3x better performance
- 10x larger model → ~2-3x better performance
- Need to scale both together for optimal results
Practical Implications
Scenario 1: Limited Data:
Dataset: 1,000 examples
Don't use: GPT-sized model (billions of parameters)
Do use: Small custom model or transfer learning
Large model will just overfitScenario 2: Abundant Data:
Dataset: 10 million examples
Don't use: Tiny network (1M parameters)
Do use: Substantial model (10M-100M parameters)
Small model won't leverage data fullyThe Future: Towards Data Efficiency
Research aims to reduce data requirements.
Emerging Approaches
1. Foundation Models:
Idea: Pre-train one massive model on diverse data
Fine-tune for specific tasks with minimal data
Example: GPT-3, CLIP, DALL-E
Can adapt to new tasks with few examples2. Meta-Learning (Learning to Learn):
Train on many related tasks
Learn efficient learning algorithms
New tasks require minimal data3. Contrastive Learning:
Learn by comparing examples
No labels needed for pre-training
Learns robust representations
Example: SimCLR matches ImageNet accuracy with 1% of labels4. Multimodal Learning:
Learn from multiple data types (image + text)
Leverage connections between modalities
More efficient than single modality
Example: CLIP learns from image-text pairs5. Neuromorphic Computing:
Brain-inspired computing
Potentially more data-efficient learning
Still in research phaseProgress and Trends
Data Requirements Over Time:
2012 (AlexNet): Needed full ImageNet (1.2M images)
2020 (SimCLR): Matches performance with far less labeled data
2023: Few-shot learning, foundation models reduce requirements further
Trend: Improving data efficiencyRemaining Challenges:
- Small data domains (rare diseases, niche applications)
- Privacy-sensitive data (can’t collect massive datasets)
- Real-time learning (need to adapt quickly)
Practical Recommendations
For Your Projects
1. Assess Data Availability First:
< 1,000 examples: Use traditional ML or transfer learning
1,000-10,000: Transfer learning or small custom model
10,000-100,000: Custom model or fine-tuning
100,000+: Train from scratch possible2. Start with Transfer Learning:
Almost always reduces data needs
Use pre-trained models when possible3. Maximize Data Utility:
Clean data carefully (quality over quantity)
Use data augmentation
Split data properly (don't waste on validation)4. Right-Size Your Model:
Match model complexity to data size
Don't use huge models on small data5. Consider Data Collection Strategy:
Active learning: Label most informative examples
Synthetic data: Supplement real data
Crowdsourcing: Scale labeling economicallyComparison: Data Requirements Across Approaches
| Approach | Typical Data Needed | Advantages | Limitations |
|---|---|---|---|
| Traditional ML | 100s-10,000s | Works with small data | Limited complexity |
| Deep Learning (scratch) | 100,000s-millions | High performance | Massive data needs |
| Transfer Learning | 1,000s-10,000s | Leverages pre-training | Requires similar domain |
| Few-Shot Learning | 1-100 per class | Extreme efficiency | Requires meta-training |
| Self-Supervised | Millions (unlabeled) | Uses free unlabeled data | Still needs some labels |
| Data Augmentation | Effective 10x increase | Easy to implement | Limited to certain domains |
| Synthetic Data | Unlimited | No labeling cost | Quality/realism concerns |
Conclusion: Understanding the Data Imperative
Deep learning’s data requirements aren’t arbitrary—they stem from fundamental characteristics: millions of parameters to learn, hierarchical feature learning, high-dimensional input spaces, and complex decision boundaries. More parameters need more examples. Complex patterns require diverse training data. Robust generalization demands seeing variations.
The numbers are sobering: millions of images for vision, billions of words for language, thousands of hours for speech. Yet understanding why these requirements exist empowers you to work with them effectively.
Key insights:
Data and parameters must balance: Too many parameters for available data leads to overfitting. Match model size to data size.
Data quality matters: 1,000 carefully curated examples often beat 10,000 noisy ones. Clean, representative data is precious.
Techniques reduce requirements: Transfer learning, data augmentation, self-supervised learning, and few-shot learning dramatically cut data needs.
The future is brighter: Foundation models, meta-learning, and contrastive learning are making deep learning increasingly data-efficient.
Context matters: Requirements vary wildly by task. Medical imaging differs from ImageNet. Choose approaches based on your specific situation.
For practitioners, the message is clear: assess data availability early, use transfer learning when possible, augment data creatively, and match model complexity to data size. Don’t let data requirements prevent you from applying deep learning—numerous techniques exist to work with limited data.
The data imperative remains real, but understanding it transforms it from an insurmountable barrier into a manageable constraint. Deep learning’s power comes from learning from data. Respect that requirement, work within it smartly, and leverage the techniques that make learning from less data possible. The field continues progressing toward data efficiency, but even today, with proper techniques, deep learning is accessible for many more problems than raw data requirements might suggest.