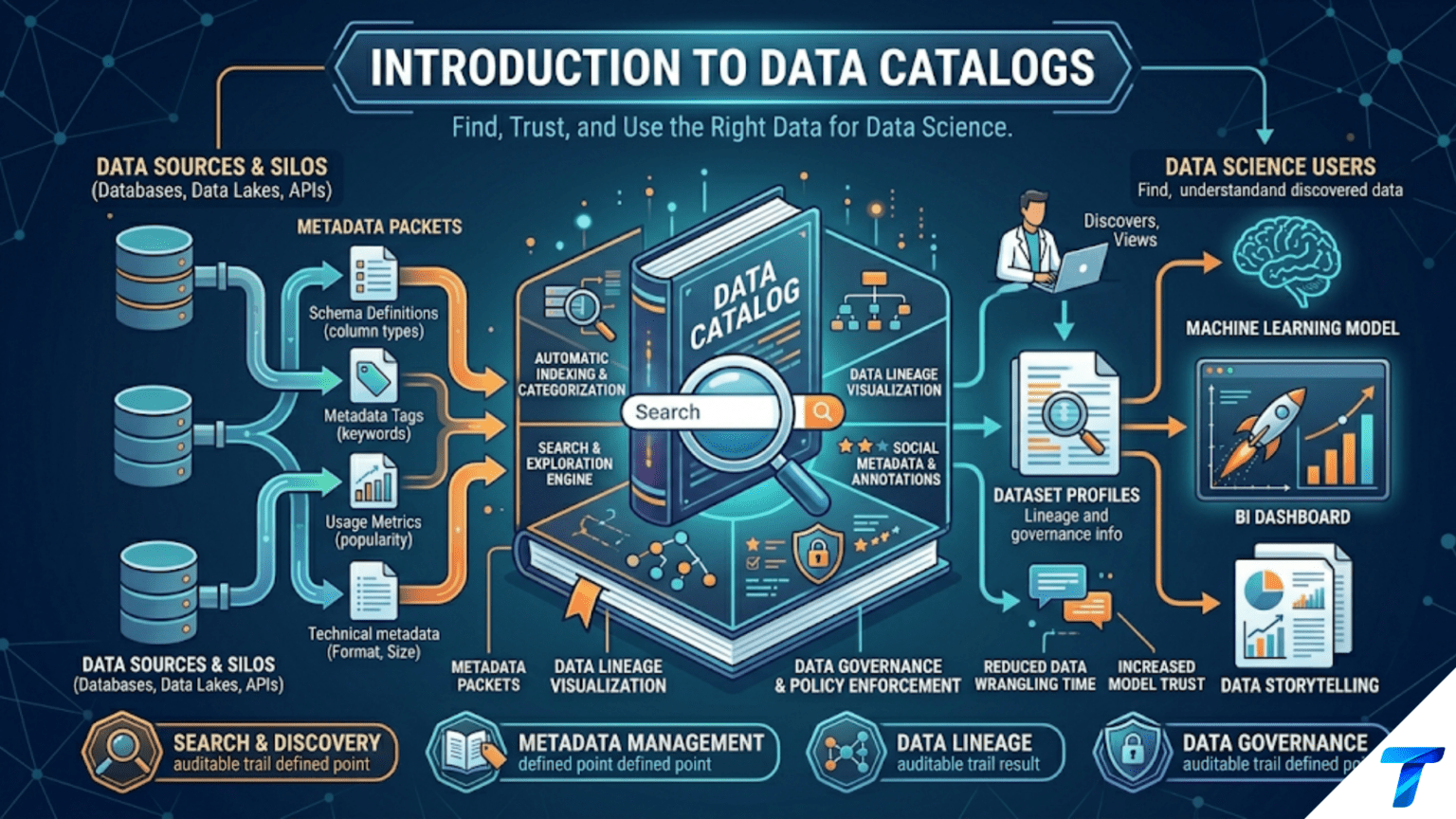
A data catalog is an organized inventory of all the data assets in an organization — tables, files, dashboards, reports, machine learning models, and data streams — enriched with metadata that describes what each asset contains, where it came from, who owns it, how it relates to other assets, how trustworthy it is, and who uses it. Data catalogs solve the “dark data” problem: in large organizations, most data assets are unknown, undiscovered, or unusable because no one can find them or knows enough about them to use them confidently. A good data catalog transforms data discovery from a weeks-long exercise of asking colleagues and digging through code into a minutes-long search.
Introduction
Picture a library without a card catalog, call numbers, or subject headings. Books are organized by when they arrived, not what they contain. There’s no index of authors, no cross-referencing by topic, no way to find all books on a given subject. To find a specific book, you either already know exactly where it is or you search every shelf hoping to stumble across it. The librarians can tell you about some of the books, but they’ve never seen most of them and have no reliable way to find out what’s in the collection.
This is what most large organizations’ data environments look like without a data catalog. There are hundreds or thousands of tables in the warehouse, files in the data lake, dashboards in BI tools, and models in production — and the only way to find the right one is to ask a colleague who might know, dig through pipeline code to reverse-engineer what a table contains, or discover by accident while browsing the warehouse.
The cost is enormous. Studies consistently find that data professionals spend 20-40% of their time searching for data rather than analyzing it. Analysts inadvertently use the wrong table because they couldn’t find the right one. Models are trained on deprecated features because the current version was undocumented. Duplicate datasets proliferate because each team creates its own copy of data they couldn’t find elsewhere.
A data catalog solves this. It is the organized, searchable inventory of an organization’s data assets — the card catalog that makes the library usable. This article explains what data catalogs are, what metadata they contain, why they matter for data scientists specifically, the tools available, and how to implement lightweight catalog practices in your own work even without a formal catalog product.
What Is a Data Catalog?
A data catalog is a metadata management system that helps users find, understand, and trust the data assets available in their organization.
The key word is metadata — data about data. A data catalog doesn’t store the data itself; it stores information about the data:
- What is this table? What does each column mean?
- Where did this data come from? (Provenance)
- Who owns and maintains this table?
- When was it last updated? How often is it refreshed?
- How many rows does it have? What is the schema?
- Is this data certified and trustworthy, or deprecated?
- Who else uses this table? What downstream reports depend on it?
- What are the business definitions of the metrics it contains?
The Five Core Functions of a Data Catalog
Discovery: Users can search for data by keyword, business term, owner, or data type and find all relevant assets. “I need customer churn data” → the catalog surfaces all tables, files, and dashboards related to churn.
Understanding: Once found, users can understand what an asset contains without opening it. Column descriptions, data types, sample values, statistics, and business definitions are all immediately visible.
Trust: Users can assess whether data is reliable before using it. Certification status, freshness indicators, quality scores, lineage, and usage statistics all contribute to trust signals.
Governance: Data stewards can enforce data classification (PII, confidential, public), manage access permissions, document retention policies, and track compliance requirements.
Collaboration: Users can leave notes, ask questions, flag issues, and share tribal knowledge — transforming siloed expertise into shared institutional knowledge.
Types of Metadata in a Data Catalog
Data catalogs organize metadata into several categories, each serving different purposes:
Technical Metadata
Technical metadata is harvested automatically from source systems. It describes the physical structure and characteristics of data assets.
# Example of technical metadata for a warehouse table
technical_metadata = {
"asset_id": "warehouse.analytics.dim_customer",
"asset_type": "table",
"data.base": "analytics_warehouse",
"sc.hema": "analytics",
"table_name": "dim_customer",
"row_count": 847293,
"column_count": 34,
"size_bytes": 892437504,
"created_at": "2021-06-15T09:00:00Z",
"last_modified_at": "2024-09-15T06:12:33Z",
"last_queried_at": "2024-09-15T14:45:01Z",
"columns": [
{
"name": "customer_key",
"data_type": "INTEGER",
"nullable": False,
"primary_key": True,
"description": "(auto-populated from sc.hema)"
},
{
"name": "customer_id",
"data_type": "VARCHAR(50)",
"nullable": False,
"description": "(auto-populated from sc.hema)"
},
{
"name": "lifetime_value",
"data_type": "DECIMAL(12,2)",
"nullable": True,
"description": "(no description yet)"
}
],
"partitioned_by": None,
"format": "Parquet (columnar)"
}Business Metadata
Business metadata is added manually by data owners, stewards, and subject matter experts. It transforms raw technical descriptions into business context.
# Business metadata layered on top of technical metadata
business_metadata = {
"asset_id": "warehouse.analytics.dim_customer",
"display_name": "Customer Dimension",
"description": (
"The primary customer dimension table for the analytics data warehouse. "
"Contains one row per customer (current version) with full demographic, "
"behavioral, and segmentation attributes. Uses SCD Type 2 — filter to "
"is_current=TRUE for current customer records."
),
"domain": "Customer Analytics",
"subdomain": "Customer Master",
"owner": "analytics-engineering@company.com",
"steward": "Jane Smith (Data Platform Team)",
"tags": ["customers", "demographics", "SCD-Type-2", "core-entity"],
"certification":"certified", # 'certified', 'approved', 'deprecated', 'experimental'
"certification_date": "2024-08-01",
"certified_by": "Data Platform Team",
"update_frequency": "Daily (refreshed at 3 AM UTC)",
"source_system": "Production PostgreSQL e-commerce data.base",
"usage_restrictions": "Contains PII — requires data access approval",
"data_classification": "confidential", # 'public', 'internal', 'confidential', 'restricted'
"related_assets": [
"warehouse.analytics.fct_sales",
"warehouse.analytics.mart_customer_summary",
"dashboard.customer_360_view"
],
"column_descriptions": {
"customer_key": "Warehouse surrogate key (auto-generated integer, never changes)",
"customer_id": "Business key from the source e-commerce system (CUST_XXXXXX format)",
"lifetime_value": "Cumulative revenue from all completed orders in USD, all time",
"recency_segment": "RFM recency tier: 'Champions', 'Loyal', 'At Risk', 'Lost'",
"is_current": "SCD Type 2 flag — TRUE for the current active record only"
}
}Operational Metadata
Operational metadata records how data assets are being used and how pipelines are performing.
operational_metadata = {
"asset_id": "warehouse.analytics.dim_customer",
"query_count_30d": 4823, # Queries in the last 30 days
"unique_users_30d": 47, # Distinct users who queried
"downstream_assets": 23, # Tables, dashboards, models that depend on this
"pipeline_runs_7d": 7, # Pipeline runs in last 7 days
"last_pipeline_run": "2024-09-15T03:12:45Z",
"last_pipeline_status": "success",
"avg_pipeline_duration_minutes": 4.2,
"data_freshness_hours": 8.2, # Hours since last successful load
"freshness_status": "fresh", # 'fresh', 'stale', 'unknown'
"popular_columns": ["customer_id", "customer_segment",
"lifetime_value", "is_current"],
"top_users": ["alice@company.com", "data-science@company.com",
"bi-team@company.com"]
}Social Metadata
Social metadata captures the human layer of knowledge — annotations, questions, ratings, and informal notes that hold the tribal knowledge about data.
social_metadata = {
"asset_id": "warehouse.analytics.dim_customer",
"ratings": {
"average_score": 4.2,
"total_ratings": 18,
"would_recommend": 0.89
},
"annotations": [
{
"author": "bob.johnson@company.com",
"date": "2024-08-15",
"comment": "Note: about 3% of records have NULL lifetime_value — these are "
"SSO customers imported before 2021-06 when order history wasn't "
"backfilled. Safe to treat as 0 for most analyses."
},
{
"author": "analytics-eng@company.com",
"date": "2024-09-01",
"comment": "IMPORTANT: Always filter is_current=TRUE or you'll get "
"multiple rows per customer (SCD Type 2 history rows)."
}
],
"open_questions": [
{
"author": "priya.patel@company.com",
"date": "2024-09-10",
"question":"Is lifetime_value updated nightly or in real-time?"
}
]
}The Business Glossary: Shared Definitions
One of the most valuable catalog features — and most commonly overlooked — is the business glossary: a shared dictionary of business terms with agreed definitions.
Without a glossary, “customer” means different things to different teams. The product team counts users who created an account. The revenue team counts users who made a purchase. The marketing team counts users who opted into email. The support team counts users who opened a ticket. When the CFO asks “how many customers do we have?” each team gives a different number — not because their data is wrong but because they’re using the same word for different things.
from dataclasses import dataclass, field
from typing import Optional
import json
@dataclass
class GlossaryTerm:
"""
A business glossary entry defining a term consistently across the organization.
"""
term: str
domain: str # Business domain this term belongs to
definition: str # Clear, unambiguous business definition
synonyms: list = field(default_factory=list)
related_terms: list = field(default_factory=list)
examples: list = field(default_factory=list)
non_examples: list = field(default_factory=list) # What this term is NOT
owner: str = "data-governance@company.com"
steward: str = "unknown"
status: str = "approved" # 'draft', 'approved', 'deprecated'
approved_date: Optional[str] = None
linked_assets: list = field(default_factory=list) # Tables/columns this term maps to
linked_columns: list = field(default_factory=list) # Specific column mappings
notes: str = ""
def to_dict(self) -> dict:
import dataclasses
return dataclasses.asdict(self)
# Build a company business glossary
glossary = [
GlossaryTerm(
term = "Customer",
domain = "Sales & Revenue",
definition = (
"An individual or organization that has completed at least one "
"paid transaction with the company. Trial users, free tier users, "
"and accounts without any completed payment do NOT qualify as customers."
),
synonyms = ["client", "buyer", "purchaser"],
related_terms= ["User", "Account", "Prospect", "Lead"],
examples = [
"Someone who bought a subscription last month",
"A company with an active paid contract"
],
non_examples= [
"A user on a free trial who hasn't paid yet",
"A demo account created by a sales rep",
"A churned customer (use 'Former Customer')"
],
owner = "revenue-team@company.com",
steward = "CFO Office",
status = "approved",
approved_date = "2024-01-15",
linked_columns= ["dim_customer.customer_id (WHERE has_paid_order = TRUE)"],
notes = (
"This definition was adopted in Q1 2024 after cross-functional alignment. "
"Pre-2024 reports may use different definitions — check report documentation."
)
),
GlossaryTerm(
term = "Active Customer",
domain = "Sales & Revenue",
definition = (
"A customer who has completed at least one paid transaction in the "
"trailing 12 months from the analysis date. 'Active' is always "
"measured relative to a specific point in time."
),
synonyms = ["active user", "retained customer"],
related_terms= ["Customer", "Churned Customer", "Dormant Customer"],
owner = "revenue-team@company.com",
status = "approved",
linked_columns= ["mart_customer_summary.is_active_12m"]
),
GlossaryTerm(
term = "Churned Customer",
domain = "Customer Success",
definition = (
"A customer who was active in the previous 12-month period but has "
"not made a purchase in the most recent 12-month period. Churn is "
"evaluated at the end of each month and is NOT retroactively revised."
),
related_terms= ["Active Customer", "Churn Rate", "Retention Rate"],
owner = "customer-success@company.com",
status = "approved",
linked_columns= ["mart_customer_summary.churned_flag",
"fct_churn_events.churn_date"]
),
GlossaryTerm(
term = "Monthly Recurring Revenue (MRR)",
domain = "Finance",
definition = (
"The predictable monthly revenue from all active subscription contracts, "
"normalized to a monthly value. One-time fees, setup fees, and usage-based "
"charges beyond the base subscription are excluded from MRR."
),
synonyms = ["MRR", "monthly recurring revenue"],
related_terms= ["ARR", "New MRR", "Expansion MRR", "Churned MRR"],
owner = "finance@company.com",
steward = "FP&A Team",
status = "approved",
linked_assets = ["warehouse.analytics.fct_subscription_revenue"]
),
]
class BusinessGlossary:
"""A simple in-memory business glossary with search functionality."""
def __init__(self, terms: list = None):
self.terms = {t.term.lower(): t for t in (terms or [])}
def add(self, term: GlossaryTerm):
self.terms[term.term.lower()] = term
def get(self, term: str) -> Optional[GlossaryTerm]:
return self.terms.get(term.lower())
def search(self, query: str) -> list:
"""Search terms by name, definition, synonyms, or domain."""
query_lower = query.lower()
results = []
for term_obj in self.terms.values():
if (query_lower in term_obj.term.lower()
or query_lower in term_obj.definition.lower()
or any(query_lower in s.lower() for s in term_obj.synonyms)
or query_lower in term_obj.domain.lower()):
results.append(term_obj)
return results
def get_by_domain(self, domain: str) -> list:
return [t for t in self.terms.values()
if domain.lower() in t.domain.lower()]
def print_term(self, term: str):
t = self.get(term)
if not t:
print(f"Term '{term}' not found in glossary.")
return
print(f"\n{'='*60}")
print(f"TERM: {t.term} [{t.status.upper()}]")
print(f"Domain: {t.domain}")
print(f"{'='*60}")
print(f"Definition:\n {t.definition}")
if t.synonyms:
print(f"\nSynonyms: {', '.join(t.synonyms)}")
if t.related_terms:
print(f"Related: {', '.join(t.related_terms)}")
if t.examples:
print(f"\nExamples:")
for ex in t.examples:
print(f" ✓ {ex}")
if t.non_examples:
print(f"\nNot examples (this term does NOT include):")
for ex in t.non_examples:
print(f" ✗ {ex}")
if t.linked_columns:
print(f"\nLinked columns: {', '.join(t.linked_columns)}")
if t.notes:
print(f"\nNotes: {t.notes}")
def to_json(self, filepath: str):
data = [t.to_dict() for t in self.terms.values()]
with open(filepath, "w") as f:
json.dump(data, f, indent=2)
print(f"Glossary saved: {len(data)} terms → {filepath}")
# Use the glossary
biz_glossary = BusinessGlossary(glossary)
biz_glossary.print_term("Customer")
# Search
print("\nSearch results for 'churn':")
for t in biz_glossary.search("churn"):
print(f" {t.term} ({t.domain}): {t.definition[:80]}...")
biz_glossary.to_json("catalog/business_glossary.json")Building a Lightweight Data Catalog in Python
Without a commercial catalog product, data scientists can build a lightweight catalog using Python data structures, JSON files, and a simple search interface:
import json
import pandas as pd
from pathlib import Path
from dataclasses import dataclass, field, asdict
from datetime import datetime, timezone
from typing import Optional, Any
@dataclass
class ColumnCatalogEntry:
"""Metadata for a single column."""
name: str
data_type: str
description: str = ""
nullable: bool = True
primary_key: bool = False
foreign_key: Optional[str] = None # "other_table.column"
sample_values: list = field(default_factory=list)
is_pii: bool = False
business_term: Optional[str] = None # Link to glossary term
notes: str = ""
@dataclass
class DataAssetCatalogEntry:
"""
A complete catalog entry for one data asset (table, file, model, etc.).
Combines technical, business, operational, and social metadata.
"""
# Identity
asset_id: str # Unique identifier: "schema.table" or file path
asset_type: str # 'table', 'view', 'file', 'dashboard', 'model', 'feature_store'
display_name: str
# Location
system: str # 'snowflake', 'bigquery', 'S3', 'local', etc.
loca.tion: str # Full path or connection string
# Business context
description: str = ""
domain: str = "unknown"
owner: str = "unknown"
steward: str = "unknown"
tags: list = field(default_factory=list)
certification: str = "experimental" # 'certified', 'approved', 'experimental', 'deprecated'
# Quality and freshness
data_classification: str = "internal"
update_frequency: str = "unknown"
last_updated: Optional[str] = None
row_count: Optional[int] = None
quality_score: Optional[float] = None # 0.0 – 1.0
# Schema
columns: list = field(default_factory=list) # List of ColumnCatalogEntry dicts
# Lineage links
upstream_assets: list = field(default_factory=list)
downstream_assets: list = field(default_factory=list)
# Social
notes: list = field(default_factory=list) # User annotations
usage_hints: list = field(default_factory=list) # "Always filter is_current=TRUE"
# Metadata
created_at: str = field(
default_factory=lambda: datetime.now(timezone.utc).isoformat()
)
last_reviewed: Optional[str] = None
def add_column(self, name: str, data_type: str, description: str = "",
nullable: bool = True, is_pii: bool = False,
business_term: str = None, **kwargs):
"""Add a column description to this asset."""
self.columns.append(ColumnCatalogEntry(
name=name, data_type=data_type, description=description,
nullable=nullable, is_pii=is_pii, business_term=business_term,
**kwargs
))
def add_note(self, author: str, note: str):
"""Add a user annotation."""
self.notes.append({
"author": author,
"note": note,
"added_at": datetime.now(timezone.utc).isoformat()
})
def to_dict(self) -> dict:
d = asdict(self)
return d
class DataCatalog:
"""
A lightweight data catalog stored as JSON files.
Provides search, discovery, and metadata management
without requiring a dedicated catalog product.
"""
def __init__(self, catalog_dir: str = "catalog"):
self.catalog_dir = Path(catalog_dir)
self.catalog_dir.mkdir(parents=True, exist_ok=True)
self.assets: dict = {}
self._load_existing()
def _load_existing(self):
"""Load all existing catalog entries from disk."""
for json_file in self.catalog_dir.glob("*.json"):
if json_file.name == "business_glossary.json":
continue
try:
with open(json_file) as f:
data = json.load(f)
asset_id = data.get("asset_id")
if asset_id:
self.assets[asset_id] = data
except Exception as e:
print(f"Warning: could not load {json_file}: {e}")
if self.assets:
print(f"Loaded {len(self.assets)} catalog entries from {self.catalog_dir}")
def register(self, entry: DataAssetCatalogEntry):
"""Register or update a data asset in the catalog."""
self.assets[entry.asset_id] = entry.to_dict()
self._save_entry(entry.asset_id)
print(f"Registered: {entry.asset_id} ({entry.asset_type})")
def _save_entry(self, asset_id: str):
"""Save one catalog entry to disk."""
safe_name = asset_id.replace("/", "__").replace(".", "__")
filepath = self.catalog_dir / f"{safe_name}.json"
with open(filepath, "w") as f:
json.dump(self.assets[asset_id], f, indent=2)
def get(self, asset_id: str) -> Optional[dict]:
"""Retrieve a catalog entry by asset ID."""
return self.assets.get(asset_id)
def search(self, query: str, asset_type: str = None,
domain: str = None, owner: str = None,
tags: list = None) -> list:
"""
Search the catalog for matching assets.
Parameters
----------
query : str
Full-text search across name, description, tags, and column names.
asset_type : str, optional
Filter by asset type ('table', 'file', 'dashboard', etc.)
domain : str, optional
Filter by business domain.
owner : str, optional
Filter by owner email or team.
tags : list, optional
Filter to assets having ALL specified tags.
Returns
-------
list
Matching catalog entries sorted by relevance.
"""
query_lower = query.lower() if query else ""
results = []
for asset_id, entry in self.assets.items():
# Type filter
if asset_type and entry.get("asset_type") != asset_type:
continue
# Domain filter
if domain and domain.lower() not in entry.get("domain", "").lower():
continue
# Owner filter
if owner and owner.lower() not in entry.get("owner", "").lower():
continue
# Tag filter
if tags:
entry_tags = [t.lower() for t in entry.get("tags", [])]
if not all(t.lower() in entry_tags for t in tags):
continue
# Text search
if query_lower:
searchable_text = " ".join([
entry.get("asset_id", ""),
entry.get("display_name", ""),
entry.get("description", ""),
entry.get("domain", ""),
" ".join(entry.get("tags", [])),
" ".join(c.get("name", "") for c in entry.get("columns", [])),
" ".join(c.get("description", "") for c in entry.get("columns", []))
]).lower()
if query_lower not in searchable_text:
continue
# Relevance scoring (simple)
score = 0
if query_lower in entry.get("asset_id", "").lower():
score += 3
if query_lower in entry.get("display_name", "").lower():
score += 2
if entry.get("certification") == "certified":
score += 1
results.append({"entry": entry, "score": score})
results.sort(key=lambda x: x["score"], reverse=True)
return [r["entry"] for r in results]
def print_asset(self, asset_id: str):
"""Display a formatted catalog entry."""
entry = self.get(asset_id)
if not entry:
print(f"Asset '{asset_id}' not found in catalog.")
return
cert_icon = {"certified": "✓", "approved": "✓", "deprecated": "⚠", "experimental": "~"
}.get(entry.get("certification", ""), "?")
print(f"\n{'='*65}")
print(f"{cert_icon} {entry['display_name']} [{entry.get('certification','').upper()}]")
print(f" ID: {entry['asset_id']} | Type: {entry['asset_type']}")
print(f" Domain: {entry.get('domain','')} | Owner: {entry.get('owner','')}")
print(f"{'='*65}")
print(f"\nDescription:\n {entry.get('description','(No description)')}")
if entry.get("row_count"):
print(f"\nSize: {entry['row_count']:,} rows")
if entry.get("update_frequency"):
print(f"Updated: {entry.get('update_frequency')}")
if entry.get("tags"):
print(f"Tags: {', '.join(entry['tags'])}")
cols = entry.get("columns", [])
if cols:
print(f"\nColumns ({len(cols)}):")
for col in cols:
pii_flag = "🔒" if col.get("is_pii") else " "
pk_flag = "🔑" if col.get("primary_key") else " "
null_flag = "?" if col.get("nullable") else "!"
desc = col.get("description") or "(no description)"
print(f" {pii_flag}{pk_flag} {null_flag} {col['name']:30s} "
f"{col.get('data_type',''):15s} {desc[:50]}")
if entry.get("usage_hints"):
print(f"\n⚠ Important usage notes:")
for hint in entry["usage_hints"]:
print(f" • {hint}")
if entry.get("upstream_assets"):
print(f"\nUpstream: {', '.join(entry['upstream_assets'])}")
if entry.get("downstream_assets"):
print(f"Downstream: {', '.join(entry['downstream_assets'])}")
if entry.get("notes"):
print(f"\nAnnotations:")
for note in entry["notes"]:
print(f" [{note['author']}]: {note['note'][:100]}")
def summary_report(self) -> pd.DataFrame:
"""Generate a summary DataFrame of all catalog entries."""
rows = []
for entry in self.assets.values():
rows.append({
"asset_id": entry["asset_id"],
"display_name": entry["display_name"],
"asset_type": entry["asset_type"],
"domain": entry.get("domain", ""),
"certification": entry.get("certification", "experimental"),
"owner": entry.get("owner", "unknown"),
"column_count": len(entry.get("columns", [])),
"row_count": entry.get("row_count"),
"quality_score": entry.get("quality_score"),
"last_updated": entry.get("last_updated"),
"n_annotations": len(entry.get("notes", [])),
"has_description": bool(entry.get("description")),
"pii_columns": sum(1 for c in entry.get("columns", [])
if c.get("is_pii"))
})
df = pd.DataFrame(rows)
return df
# ── Build a sample catalog ────────────────────────────────────────────────────
catalog = DataCatalog("catalog/")
# Register dim_customer
dim_customer = DataAssetCatalogEntry(
asset_id = "analytics.dim_customer",
asset_type = "table",
display_name = "Customer Dimension",
system = "Snowflake",
location = "ANALYTICS_DB.ANALYTICS.DIM_CUSTOMER",
description = (
"Primary customer dimension (SCD Type 2). Contains one row per customer "
"per version. Always filter WHERE is_current = TRUE for current records."
),
domain = "Customer Analytics",
owner = "analytics-engineering@company.com",
steward = "Jane Smith",
tags = ["customers", "dimension", "SCD-Type-2", "PII"],
certification = "certified",
data_classification = "confidential",
update_frequency = "Daily at 3 AM UTC",
last_updated = "2024-09-15T03:12:45Z",
row_count = 847293,
quality_score = 0.97,
upstream_assets = ["source.postgres.customers", "source.salesforce.accounts"],
downstream_assets= ["analytics.fct_sales", "analytics.mart_customer_summary"],
usage_hints = [
"Always filter WHERE is_current = TRUE for current records",
"Use customer_key (not customer_id) for all warehouse joins",
"~3% of records have NULL lifetime_value — SSO customers imported pre-2021"
]
)
dim_customer.add_column("customer_key", "INTEGER", "Warehouse surrogate key (never changes)", nullable=False, primary_key=True)
dim_customer.add_column("customer_id", "VARCHAR", "Source system business key (CUST_XXXXXX)", nullable=False)
dim_customer.add_column("email", "VARCHAR", "Customer email address", nullable=True, is_pii=True)
dim_customer.add_column("lifetime_value", "DECIMAL", "All-time cumulative revenue from completed orders in USD", nullable=True, business_term="Customer Lifetime Value")
dim_customer.add_column("customer_segment","VARCHAR", "Current RFM-based segment: Champions, Loyal, At Risk, Lost", nullable=False)
dim_customer.add_column("is_current", "BOOLEAN", "TRUE for the current active SCD record; FALSE for historical versions", nullable=False)
dim_customer.add_note("analytics-eng@company.com",
"SCD Type 2 implemented — use is_current=TRUE for present-state queries, "
"or join on customer_key to get historical attribute values at time of event.")
catalog.register(dim_customer)
# Register the churn features dataset
churn_features = DataAssetCatalogEntry(
asset_id = "feature_store.churn_features_v3",
asset_type = "feature_store",
display_name = "Churn Prediction Features v3",
system = "S3 + Feature Store",
location = "s3://ml-artifacts/feature-store/churn_features_v3/",
description = "Customer features for the churn prediction model. "
"One row per customer. 365-day lookback window. Refreshed daily.",
domain = "Machine Learning",
owner = "data-science@company.com",
tags = ["churn", "ML-features", "customers"],
certification = "approved",
update_frequency = "Daily at 7 AM UTC",
row_count = 9234,
quality_score = 0.99,
upstream_assets = ["analytics.dim_customer", "analytics.fct_sales",
"analytics.fact_support_tickets"],
)
churn_features.add_column("customer_id", "VARCHAR", "Business key for joining to other tables")
churn_features.add_column("lifetime_value", "FLOAT", "Total completed order revenue in USD, all time")
churn_features.add_column("recency_days", "INTEGER", "Days since most recent order (999 = never ordered)")
churn_features.add_column("n_high_severity_tickets","INTEGER", "Support tickets with severity='high' in last 365 days")
churn_features.add_column("n_orders", "INTEGER", "Count of completed orders in last 365 days")
catalog.register(churn_features)
# ── Use the catalog ────────────────────────────────────────────────────────────
# Display a catalog entry
catalog.print_asset("analytics.dim_customer")
# Search the catalog
print("\n=== Search: 'customer churn' ===")
results = catalog.search("churn")
for r in results:
print(f" [{r.get('certification','?').upper():12s}] {r['asset_id']}: "
f"{r.get('description','')[:60]}...")
# Summary report
print("\n=== Catalog Summary ===")
summary = catalog.summary_report()
print(summary[["asset_id", "certification", "column_count",
"quality_score", "has_description"]].to_string(index=False))Commercial and Open-Source Catalog Tools
Open-Source
DataHub (LinkedIn): The most widely deployed open-source catalog. Supports 50+ integrations (Hive, Kafka, Airflow, dbt, Looker, etc.), column-level lineage, business glossary, and access control. Self-hosted.
Apache Atlas: Strong Hadoop ecosystem integration. Good for Hive, HBase, Kafka, and Spark environments. Heavily used in financial services.
Amundsen (Lyft): Focus on search and discovery. Good for data scientists who need to find data quickly. Lighter-weight than DataHub.
OpenMetadata: Modern, API-first design with strong connector ecosystem and built-in data quality integration.
Commercial
Atlan: Popular with data teams using dbt + modern data stack. Strong lineage visualization and collaboration features.
Alation: Strong in regulated industries (finance, healthcare). Excellent search and stewardship workflows.
Collibra: Enterprise-focused, strong governance and policy management. Common in large organizations with complex compliance needs.
data.world: Focused on collaborative data sharing and documentation.
The Data Catalog Selection Matrix
| Tool | Best For | Strengths | Weaknesses |
|---|---|---|---|
| DataHub | Large organizations, diverse tech stacks | 50+ connectors, open-source, column lineage | Complex to self-host |
| Amundsen | Data discovery focus | Simple, fast search | Limited governance |
| OpenMetadata | API-first teams | Modern design, extensible | Newer, smaller community |
| Apache Atlas | Hadoop/Hive ecosystems | Mature, financial industry adoption | Complex, dated UI |
| Atlan | Modern data stack (dbt+Snowflake) | Beautiful UX, dbt integration | Commercial, expensive |
| Alation | Regulated industries | Enterprise governance, compliance | Very expensive |
| Collibra | Large enterprises, compliance | Policy management, mature | Very expensive, complex |
What Data Scientists Should Expect From a Catalog
Data scientists are primarily consumers of catalog metadata, not producers. Here’s what a good catalog should enable you to do:
Before starting a project:
- Search for all tables related to “customer churn” or “revenue” and find certified, current ones
- Understand what each table contains without running exploratory SQL first
- Know who owns the data and who to ask questions
When choosing between two tables:
- See which is certified vs. experimental
- Compare row counts, freshness, and quality scores
- Read usage notes from previous users
- See which downstream assets use each table (popularity as a trust signal)
When your results look wrong:
- Trace the upstream lineage to find where a metric was defined
- Read existing annotations to check for known issues
- Contact the owner directly from the catalog
For compliance:
- Know which columns contain PII before using data for analysis
- Understand data classification before sharing results
- Verify consent and legal basis for specific data sources
Contributing to the Catalog as a Data Scientist
Data scientists are not just consumers — they are also knowledge holders. Contributing to the catalog is one of the highest-leverage things you can do for your team:
# Practical ways data scientists contribute to a catalog
# 1. Document your findings as annotations
# After discovering that lifetime_value has 3% nulls for SSO customers:
catalog.assets["analytics.dim_customer"]["notes"].append({
"author": "priya.patel@company.com",
"note": "Discovered: ~3% null lifetime_value for SSO customers "
"imported before June 2021. These customers' orders weren't "
"backfilled. Treat as 0 for churn model features. "
"Ticket filed with data-engineering to backfill: JIRA-4821.",
"added_at": datetime.now(timezone.utc).isoformat()
})
# 2. Register datasets you create
new_feature_set = DataAssetCatalogEntry(
asset_id = "ml.rfm_segments_2024q3",
asset_type = "file",
display_name = "RFM Customer Segments — Q3 2024",
system = "S3",
location = "s3://data-science/rfm_segments/2024q3/",
description = "Customer segmentation based on Recency, Frequency, Monetary "
"analysis as of 2024-09-15. Used for targeted email campaign "
"planning. See notebook: analysis/rfm_segmentation_2024q3.ipynb",
domain = "Customer Analytics",
owner = "priya.patel@company.com",
tags = ["RFM", "segmentation", "customers", "Q3-2024"],
certification = "experimental",
row_count = 847293
)
catalog.register(new_feature_set)
# 3. Improve column descriptions
# When you figure out what an undocumented column means:
for col in catalog.assets["analytics.dim_customer"]["columns"]:
if col["name"] == "acq_channel_code" and not col.get("description"):
col["description"] = (
"Customer acquisition channel code. Values: ORG=organic search, "
"PAD=paid ads, REF=referral, EML=email, SOC=social media, DIR=direct. "
"NULL for customers acquired before 2022-01 when channel tracking was added."
)
catalog._save_entry("analytics.dim_customer")
print("Updated column description for acq_channel_code")Summary
A data catalog is the organizational infrastructure that makes data assets findable, understandable, and trustworthy. Without it, the 200 tables in your warehouse are effectively invisible — you can only use what you know about already or what a colleague happens to mention. With a catalog, data discovery becomes a search rather than an expedition, and the metadata that experienced team members carry in their heads becomes documented institutional knowledge.
The four types of metadata a catalog manages — technical (schema, row counts, types), business (descriptions, ownership, domain, certification), operational (usage patterns, freshness, pipeline health), and social (annotations, questions, tribal knowledge) — together answer the question “is this data right for my use case?” before you write a single query.
For data scientists, the catalog is most valuable in three moments: before starting a project (to find and evaluate available data), when results look wrong (to trace upstream lineage and check known issues), and for compliance (to understand data classification and sensitivity before sharing results). Contributing to the catalog — adding column descriptions, documenting your findings as annotations, registering your derived datasets — is one of the highest-leverage contributions you can make to your team’s long-term productivity.
Key Takeaways
- A data catalog is an organized, searchable inventory of data assets enriched with metadata — it solves the “dark data” problem where most of an organization’s data is unknown, undiscovered, or unusable because it can’t be found or understood
- The four metadata types in a catalog serve different purposes: technical (schema, types, row counts — auto-harvested), business (descriptions, ownership, definitions — human-curated), operational (usage patterns, freshness, pipeline health — auto-collected from systems), and social (annotations, questions, ratings — community contributions)
- The business glossary is among the most valuable but most commonly neglected catalog feature — it provides agreed definitions for terms like “customer,” “active user,” and “MRR” that different teams otherwise interpret inconsistently
- Certification levels (certified, approved, experimental, deprecated) are the most important trust signals in a catalog — always prefer certified assets for production work and avoid deprecated ones
- Data scientists are both consumers and contributors: consume the catalog to find, understand, and trust data before using it; contribute by adding column descriptions, documenting discovered issues as annotations, and registering derived datasets
- A lightweight catalog can be implemented with Python dataclasses, JSON files, and a simple search function — meaningful catalog practices don’t require a commercial product to start
- Open-source catalog tools include DataHub (most connectors), Amundsen (search-focused), OpenMetadata (modern API-first), and Apache Atlas (Hadoop ecosystems); commercial options include Atlan (modern data stack), Alation (regulated industries), and Collibra (enterprise governance)
- The catalog’s value compounds over time: each description added, each annotation contributed, each lineage link recorded makes the entire catalog more valuable — treat documentation as a first-class deliverable alongside the analysis itself