

Supervised learning is one of the core types of machine learning, widely applied across industries for tasks that require precise predictions or classifications. In supervised learning, a model is trained on labeled data, meaning each data point in the training set is paired with the correct answer. The model learns to map inputs (features) to outputs (labels) by identifying patterns in the data, making it well-suited for tasks where a specific outcome or classification is required.
The name “supervised” learning comes from the fact that the model is “supervised” or guided during training. By providing the model with labeled examples, it can learn from its mistakes by comparing its predictions to the correct answers and adjusting accordingly. Once trained, the model is used to make predictions on new, unseen data, allowing it to generalize its learning to future cases.
This article provides an in-depth overview of supervised learning, its applications, popular algorithms, and the steps involved in building and evaluating a supervised learning model.
Key Concepts in Supervised Learning
To understand supervised learning, it’s essential to grasp a few foundational concepts that form the basis of this learning approach:
1. Labeled Data
Labeled data is the foundation of supervised learning. Each data point in a labeled dataset consists of input features (variables that represent information about the data point) and an output label (the correct answer or outcome). The goal is for the model to learn the relationship between these features and labels so that it can make accurate predictions on new data.
- Example: In a dataset for spam detection, the input features might include characteristics of an email, such as word frequency or sender information, while the label indicates whether the email is spam or not spam.
2. Features and Target Variable
In supervised learning, the inputs are called features, and the output is called the target variable. Features are the independent variables that the model uses to make predictions, while the target variable is the dependent variable that the model is trained to predict. The relationship between features and the target variable forms the basis of the predictive model.
- Example: For predicting house prices, features might include the number of bedrooms, square footage, and location, while the target variable would be the house price.
3. Training and Testing Data
A labeled dataset is typically split into two subsets: a training set and a testing set. The training set is used to train the model, allowing it to learn the relationship between features and labels. The testing set, which the model has not seen before, is used to evaluate the model’s performance and assess its ability to generalize to new data.
- Example: In a dataset of customer reviews, 80% of the reviews may be used to train a sentiment analysis model, while the remaining 20% are set aside to test the model’s accuracy in classifying unseen reviews.
4. Model Evaluation
Once a model is trained, it’s essential to evaluate its performance. Evaluation metrics, such as accuracy, precision, recall, and F1-score, provide insights into how well the model is performing on the testing set. These metrics help determine if the model is accurate, generalizes well, and meets the goals of the task.
- Example: A model predicting loan defaults may have high accuracy, but other metrics like precision and recall provide additional information on its effectiveness in identifying actual defaults and minimizing false predictions.
Types of Supervised Learning Tasks
Supervised learning encompasses two main types of tasks: classification and regression. Each task type has unique goals, methods, and applications.
1. Classification
In classification tasks, the goal is to categorize data into predefined classes or labels. The model learns to assign each data point to one of several possible categories based on its features. Classification is widely used for tasks that involve categorical outcomes, such as identifying whether an email is spam or not or classifying medical images.
- Binary Classification: Binary classification involves two classes, such as predicting whether a customer will churn (yes or no) or whether a loan will default (default or no default).
- Multi-Class Classification: Multi-class classification involves more than two classes, such as categorizing news articles into topics (e.g., politics, sports, technology) or identifying the species of a flower.Example Use Cases for Classification:
- Spam Detection: Email providers use binary classification to filter spam and non-spam emails.
- Medical Diagnosis: Classification models help diagnose diseases by classifying patient data into different categories (e.g., diagnosing types of cancer).
- Sentiment Analysis: In sentiment analysis, models categorize customer reviews as positive, neutral, or negative.
2. Regression
In regression tasks, the goal is to predict a continuous value, making it useful for problems where the target variable is numerical. The model learns to estimate a value based on input features, and regression is commonly used in forecasting and prediction tasks.
- Example Use Cases for Regression:
- Price Prediction: Real estate platforms use regression models to predict house prices based on factors like location, size, and number of rooms.
- Sales Forecasting: Businesses use regression to forecast sales figures based on historical data and seasonal patterns.
- Weather Prediction: Meteorologists use regression models to forecast temperature, humidity, and precipitation levels based on past weather data.
Each of these supervised learning tasks addresses a different kind of prediction challenge, making classification ideal for categorical outputs and regression suitable for numerical outputs.
Popular Algorithms in Supervised Learning
Several algorithms are used in supervised learning, each suited to specific types of problems, data structures, and computational needs. Here’s an overview of some of the most commonly used supervised learning algorithms:
1. Linear Regression
Linear Regression is one of the simplest and most widely used regression algorithms. It models the relationship between the features and the target variable as a linear equation, making it effective for predicting continuous values.
- Formula:
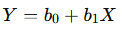
- Where Y is the target variable, X is the feature, b0 is the intercept, and b1 is the slope of the line.
Example: Linear regression is commonly used to predict house prices, where the target variable is the house price, and the features include factors like square footage and location.
2. Logistic Regression
Logistic Regression is a classification algorithm used for binary classification tasks. It predicts the probability of a data point belonging to a particular class by mapping the output to a logistic curve.
- Formula:
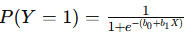
- Where P(Y=1) is the probability of the target variable being 1, and eee represents the natural exponential.
- Example: Logistic regression is used for email spam detection, where the model predicts whether an email is spam (1) or not spam (0) based on features like word frequency and sender details.
3. Decision Trees
Decision Trees use a tree-like structure to make decisions based on feature values, with branches representing decision paths. Decision trees are versatile and can be used for both classification and regression tasks. They are easy to interpret and particularly useful for tasks with complex, non-linear relationships.
- Example: In customer segmentation, decision trees categorize customers based on demographics and purchasing behavior, enabling targeted marketing.
4. Support Vector Machines (SVMs)
Support Vector Machines (SVMs) are powerful algorithms used for both classification and regression tasks. SVMs work by finding an optimal hyperplane that separates data points of different classes with the maximum margin, making them effective for high-dimensional data.
- Example: SVMs are commonly used in image recognition, where the model classifies images based on pixel values and feature vectors.
5. k-Nearest Neighbors (k-NN)
k-Nearest Neighbors (k-NN) is an instance-based learning algorithm used mainly for classification. It classifies a data point based on the classes of its nearest neighbors in feature space, where the majority class among the kkk nearest neighbors determines the prediction.
- Example: k-NN is used in recommendation systems to suggest products based on similar users’ preferences or past purchases.
6. Ensemble Methods
Ensemble Methods like Random Forests and Gradient Boosting combine multiple models to improve accuracy and robustness. By aggregating predictions from several models, ensemble methods often outperform single models and are widely used in both classification and regression tasks.
- Example: Random forests are commonly used in credit scoring, where the model predicts the likelihood of a loan default by combining multiple decision trees.
These algorithms form the backbone of supervised learning, each offering unique advantages for specific types of tasks. Choosing the right algorithm depends on the nature of the data, the task’s complexity, and the required level of interpretability.
Building a Supervised Learning Model
The process of building a supervised learning model involves several key steps, from data preparation to model evaluation. Each stage is essential for creating a model that can generalize well to new data and perform accurately on real-world tasks.
1. Data Collection
The first step in supervised learning is collecting a labeled dataset that includes both input features and corresponding labels. The quality and quantity of this data are critical, as the model’s performance depends heavily on the data it’s trained on.
- Example: For a customer churn prediction model, the data might include customer demographics, past purchase behavior, and whether each customer churned (label).
2. Data Preparation and Cleaning
Once the data is collected, it must be prepared and cleaned. Data cleaning ensures that the dataset is free from inconsistencies, missing values, and outliers that can negatively affect the model’s performance.
Key data preparation tasks include:
- Handling Missing Values: Missing values can be filled with the mean, median, or a specific value, depending on the context. In some cases, rows with missing values may be removed, or advanced techniques like K-nearest neighbor imputation may be used.
- Removing Outliers: Outliers can skew model predictions, particularly in regression tasks. Techniques like Z-score or IQR (Interquartile Range) can be used to identify and remove outliers.
- Encoding Categorical Variables: Machine learning models require numerical input, so categorical data must be converted into numerical form. Techniques like one-hot encoding and label encoding are commonly used to handle categorical features.
- Example: For a dataset with a “Gender” feature, values like “Male” and “Female” might be converted to 0 and 1, or represented as separate columns in a one-hot encoded format.
- Scaling and Normalization: Features with varying scales can affect model training, especially in algorithms like SVM and k-NN. Scaling (using techniques like Min-Max Scaling) or normalization (using Z-score) brings all features to a similar scale, improving training consistency.
3. Data Splitting
After cleaning the data, it’s divided into training and testing sets. The training set is used to train the model, while the testing set assesses the model’s generalization ability. A typical split is 80% of the data for training and 20% for testing, although this ratio may vary based on dataset size.
- Validation Set: In some cases, the data is further split into a validation set, which is used to fine-tune model parameters without touching the test set. This approach helps avoid overfitting and ensures that model performance on the test set reflects true generalization.
from sklearn.model_selection import train_test_split
# Split the data
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)4. Model Selection and Training
Once the data is prepared and split, the next step is selecting an appropriate algorithm based on the task type and data characteristics. For instance, logistic regression or decision trees are commonly used for classification, while linear regression or random forests are effective for regression tasks.
After choosing the algorithm, the model is trained on the training set. During training, the model learns the relationship between the input features and the output labels, adjusting its parameters to minimize prediction errors.
- Example: Training a logistic regression model for binary classification.
from sklearn.linear_model import LogisticRegression
# Initialize and train the model
model = LogisticRegression()
model.fit(X_train, y_train)Evaluating Supervised Learning Models
Once a model is trained, it’s essential to evaluate its performance. Model evaluation metrics provide insights into how well the model generalizes to new data and help identify areas for improvement. The choice of metrics depends on whether the task is classification or regression.
1. Evaluation Metrics for Classification
Classification models are evaluated using metrics that measure the accuracy of categorical predictions. Here are some of the most commonly used classification metrics:
Accuracy: Accuracy measures the percentage of correct predictions among all predictions. While simple to interpret, accuracy can be misleading for imbalanced datasets, where one class dominates the data.
- Formula:
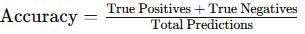
from sklearn.metrics import accuracy_score
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)Precision: Precision measures the proportion of positive predictions that are actually correct. It’s useful in scenarios where false positives are costly, such as in fraud detection.
- Formula:
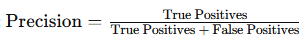
from sklearn.metrics import precision_score
precision = precision_score(y_test, y_pred)
print("Precision:", precision)Recall: Recall measures the proportion of actual positives that the model correctly identifies. It’s valuable in cases where missing positive cases is costly, such as in medical diagnoses.
- Formula:
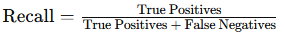
from sklearn.metrics import recall_score
recall = recall_score(y_test, y_pred)
print("Recall:", recall)F1-Score: The F1-Score is the harmonic mean of precision and recall, providing a single metric that balances the two. It’s particularly useful for imbalanced datasets.
- Formula:
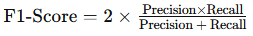
from sklearn.metrics import f1_score
f1 = f1_score(y_test, y_pred)
print("F1-Score:", f1)ROC-AUC Score: The ROC-AUC Score evaluates the model’s ability to distinguish between classes by measuring the area under the ROC curve, where higher values indicate better classification performance.
from sklearn.metrics import roc_auc_score
roc_auc = roc_auc_score(y_test, model.predict_proba(X_test)[:, 1])
print("ROC-AUC Score:", roc_auc)2. Evaluation Metrics for Regression
Regression models are evaluated based on their ability to predict continuous values accurately. Common metrics include:
Mean Absolute Error (MAE): MAE measures the average magnitude of prediction errors, providing a simple interpretation of model accuracy. Lower values indicate better performance.
- Formula:
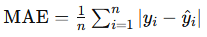
from sklearn.metrics import mean_absolute_error
mae = mean_absolute_error(y_test, y_pred)
print("Mean Absolute Error:", mae)Mean Squared Error (MSE): MSE squares the errors before averaging, penalizing larger errors more heavily. It’s valuable when large deviations are costly.
- Formula:

from sklearn.metrics import mean_squared_error
mse = mean_squared_error(y_test, y_pred)
print("Mean Squared Error:", mse)Root Mean Squared Error (RMSE): RMSE is the square root of MSE, bringing the metric back to the original units of the target variable.
rmse = mean_squared_error(y_test, y_pred, squared=False)
print("Root Mean Squared Error:", rmse)R² Score: The R² score measures the proportion of variance in the target variable that is predictable from the features, with values closer to 1 indicating better fit.
- Formula:
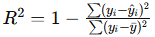
from sklearn.metrics import r2_score
r2 = r2_score(y_test, y_pred)
print("R² Score:", r2)Choosing the right evaluation metric is crucial, as each metric provides unique insights into model performance. In classification, a balanced metric like F1-score is valuable for imbalanced data, while in regression, RMSE is often preferred for its sensitivity to large errors.
Hyperparameter Tuning in Supervised Learning
Hyperparameters are settings in a machine learning algorithm that are not learned from the data but defined by the user. Optimizing these settings, known as hyperparameter tuning, can significantly improve model performance. Common methods include:
- Grid Search: Grid search tests all combinations of specified hyperparameters, though it can be computationally expensive.
from sklearn.model_selection import GridSearchCV
param_grid = {'C': [0.1, 1, 10], 'kernel': ['linear', 'rbf']}
grid_search = GridSearchCV(SVC(), param_grid, cv=5)
grid_search.fit(X_train, y_train)- Random Search: Random search tests random combinations of hyperparameters and is faster than grid search.
- Cross-Validation: Cross-validation assesses model performance on multiple data splits, providing a reliable estimate of generalization.
Hyperparameter tuning enhances model accuracy, efficiency, and reliability, making it a critical part of the supervised learning workflow.
Challenges in Supervised Learning
Supervised learning offers powerful tools for prediction and classification, but it also presents specific challenges. Overcoming these challenges is essential for building accurate and reliable models that can perform effectively in production environments.
1. Data Quality and Quantity
Supervised learning depends on high-quality, labeled data. However, collecting and labeling data can be time-consuming and costly, particularly in fields like medical diagnostics or legal document analysis, where expert knowledge is required.
- Data Quantity: Supervised learning algorithms need a sufficient volume of labeled data to capture complex patterns accurately. Small datasets may lead to overfitting, where the model performs well on the training data but poorly on new data.
- Data Quality: The model’s accuracy depends on the quality of the training data. Inconsistent labeling, missing values, and irrelevant features can introduce noise, leading to inaccurate predictions.
2. Overfitting and Underfitting
Balancing model complexity is crucial in supervised learning. Two common issues are overfitting and underfitting:
- Overfitting: This occurs when a model learns the noise in the training data rather than general patterns. Overfitted models perform well on training data but fail to generalize to new data.
- Solution: Techniques like cross-validation, regularization (e.g., Lasso or Ridge regression), and pruning (in decision trees) help prevent overfitting by reducing model complexity.
- Underfitting: Underfitting occurs when a model is too simple to capture the underlying patterns in the data. As a result, it performs poorly on both training and testing data.
- Solution: Increasing model complexity, adding more features, or selecting a more sophisticated algorithm can help address underfitting.
3. Imbalanced Data
Imbalanced data is a common challenge in supervised learning, especially in binary classification tasks. For example, in fraud detection, fraudulent transactions are rare, leading to a skewed dataset where the majority class (non-fraudulent) dominates. Imbalanced data can result in a biased model that predicts the majority class well but performs poorly on the minority class.
- Solution: Techniques such as oversampling the minority class, undersampling the majority class, and using specialized metrics like F1-score and ROC-AUC for evaluation can help address class imbalance.
4. Feature Selection and Engineering
The quality of input features has a significant impact on model performance. Feature selection involves choosing the most relevant features to reduce noise, while feature engineering creates new features from existing ones to improve predictive power.
- Solution: Using techniques like principal component analysis (PCA) for dimensionality reduction, recursive feature elimination (RFE), and domain knowledge can help identify and engineer valuable features.
5. Interpretability and Transparency
In some applications, such as healthcare or finance, understanding the model’s decision-making process is crucial. Complex models, like deep neural networks, can be challenging to interpret, making it difficult to explain predictions to stakeholders.
- Solution: Interpretable models like decision trees or logistic regression, along with model explainability tools like SHAP (Shapley Additive exPlanations) and LIME (Local Interpretable Model-agnostic Explanations), help improve transparency.
Real-World Applications of Supervised Learning Across Industries
Supervised learning is widely applied across various sectors due to its ability to provide accurate predictions and insights based on labeled data. Here are some notable applications:
1. Healthcare
In healthcare, supervised learning models support diagnostics, treatment planning, and patient management by predicting outcomes based on historical patient data.
- Medical Diagnostics: Classification models help identify diseases from medical images, such as detecting tumors in MRI scans or classifying skin lesions as malignant or benign.
- Patient Outcome Prediction: Hospitals use regression models to predict patient outcomes, such as survival rates for certain conditions, which aids in personalized treatment planning.
2. Finance
The finance industry relies on supervised learning for risk assessment, fraud detection, and customer relationship management.
- Credit Scoring: Classification models are used to assess the creditworthiness of loan applicants, predicting whether a customer is likely to default based on historical lending data.
- Fraud Detection: Supervised models analyze transaction patterns to detect anomalies, flagging potentially fraudulent transactions in real-time.
3. Retail and E-Commerce
Supervised learning is essential in retail for customer segmentation, demand forecasting, and personalized marketing.
- Customer Segmentation: Classification models categorize customers based on behavior and demographics, enabling retailers to create targeted marketing campaigns.
- Product Recommendation: Regression models predict product affinity based on customer preferences, powering recommendation systems for e-commerce platforms like Amazon.
4. Transportation and Logistics
In transportation and logistics, supervised learning models optimize route planning, fleet management, and safety.
- Demand Forecasting: Regression models forecast demand for transportation services, helping companies manage resources and reduce operational costs.
- Autonomous Vehicles: Classification models in autonomous vehicles detect obstacles, traffic signs, and pedestrians, improving navigation and safety in real time.
5. Marketing and Advertising
Supervised learning enables personalized advertising, customer insights, and campaign optimization, enhancing marketing efficiency.
- Sentiment Analysis: Classification models analyze customer reviews and social media posts to gauge customer sentiment, helping brands understand customer opinions and tailor their messaging.
- Churn Prediction: In subscription-based businesses, supervised models predict customer churn based on usage data, enabling companies to intervene with retention strategies.
Each industry benefits uniquely from supervised learning, as it provides accurate, data-driven insights that improve decision-making, optimize operations, and enhance customer experiences.
Best Practices for Implementing Supervised Learning Models
Implementing supervised learning successfully requires adherence to best practices that enhance model reliability, accuracy, and interpretability. Here are some essential guidelines:
1. Ensure Data Quality and Quantity
The quality of a supervised learning model depends on the quality of the data. Cleaning, validating, and preprocessing the data before training are essential for building an accurate model.
- Best Practice: Invest time in data preparation, including handling missing values, removing outliers, and normalizing or scaling features. Collect a sufficient amount of labeled data to train a robust model.
2. Start Simple and Iterate
While complex models may seem appealing, simpler models are often more interpretable and efficient. Starting with a simpler algorithm, like linear regression or a decision tree, provides a solid baseline and allows you to assess if more complex models are needed.
- Best Practice: Begin with simpler models and gradually increase complexity if needed. This approach allows you to better understand the data and the model’s behavior before implementing more computationally intensive algorithms.
3. Use Cross-Validation
Cross-validation, especially k-fold cross-validation, helps assess model performance by evaluating it on multiple data splits. This approach provides a more reliable measure of generalization and reduces the risk of overfitting.
- Best Practice: Use cross-validation to fine-tune model parameters and choose the best-performing model without risking overfitting to a single train-test split.
4. Optimize Hyperparameters
Hyperparameters, which control model behavior, have a significant impact on performance. Tuning these settings can improve accuracy and efficiency, but it requires a systematic approach.
- Best Practice: Use grid search or random search to identify the optimal hyperparameters. Automated hyperparameter tuning tools, like Bayesian optimization, can also be valuable for complex models.
5. Monitor and Update the Model
Supervised learning models may need to be retrained or fine-tuned over time as data changes. Monitoring the model’s performance and accuracy in real-world scenarios helps identify when updates are necessary.
- Best Practice: Implement a monitoring pipeline to track model performance on new data. Regular updates and retraining are essential, especially in dynamic environments where data distributions may shift.
6. Ensure Model Interpretability
In fields where model decisions impact individuals directly, such as healthcare or finance, interpretability is crucial for transparency and trust.
- Best Practice: Use interpretable models where possible, and apply model-agnostic explainability tools like SHAP or LIME to clarify complex model decisions. This approach ensures stakeholders understand and trust the model’s predictions.
Conclusion: Why Supervised Learning Matters
Supervised learning has become an essential component of machine learning, offering accurate, data-driven insights that drive decision-making across diverse industries. From predicting customer behavior and detecting fraud to diagnosing diseases and optimizing logistics, supervised learning provides a foundation for numerous applications. Its ability to learn from labeled data and generalize to unseen data makes it invaluable for both predictive and classification tasks.
While supervised learning has its challenges, such as the need for labeled data and potential overfitting, these can be addressed through careful data preparation, hyperparameter tuning, and robust evaluation methods. By following best practices, practitioners can implement supervised learning models that are accurate, reliable, and adaptable, meeting the evolving needs of real-world applications.
As supervised learning continues to evolve, its role will expand, empowering organizations to leverage data more effectively and innovate in ways that were previously unimaginable. Understanding supervised learning fundamentals is key to navigating and succeeding in today’s data-driven world.






