Model-based learning is a type of machine learning approach in which the model learns general patterns or rules from the training data and uses these patterns to make predictions on new, unseen data. Unlike instance-based learning, which relies on memorizing specific examples, model-based learning builds a generalizable model that captures the underlying structure of the data. This approach, also known as parametric learning, allows the model to make predictions without storing all individual instances, making it scalable and efficient for large datasets.
In model-based learning, the training process involves estimating a set of parameters (such as coefficients in linear regression) or constructing a mathematical representation (like a decision tree) that best fits the data. This model can then generalize to new data, making predictions based on the learned parameters or structure. Common model-based algorithms include linear regression, logistic regression, support vector machines (SVM), decision trees, and neural networks. Model-based learning is particularly effective in tasks where understanding the global patterns or trends in data is crucial, such as in financial forecasting, image recognition, and predictive maintenance.
This article explores the foundational concepts, advantages, and limitations of model-based learning. We will also discuss how it differs from instance-based learning, outline the types of problems it is well-suited for, and highlight common model-based algorithms.
Key Concepts in Model-Based Learning
To understand model-based learning, it is essential to explore several foundational concepts that define how this approach works, including model generalization, parameter estimation, and the training process.
1. Generalization and Pattern Recognition
The primary goal of model-based learning is to generalize from the training data to new, unseen data. This means that the model does not memorize individual instances but instead learns to recognize patterns, relationships, and trends that can apply to future data points. This generalization ability makes model-based learning highly effective for predicting outcomes in large and complex datasets.
- Example: In predicting housing prices, a model-based algorithm like linear regression would analyze the relationship between features (such as square footage, number of bedrooms, and location) and the target variable (price). Instead of memorizing each house’s price, the model generalizes a pattern that it can use to predict prices for new houses based on their features.
2. Parameter Estimation
In model-based learning, the model’s ability to make predictions depends on estimating a set of parameters that best represent the data’s underlying structure. These parameters define the model’s decision-making process. For example, in a linear regression model, parameters are the coefficients for each feature, determining how much each feature influences the prediction.
- Example: In logistic regression, which is used for binary classification, the parameters (coefficients) are learned from the training data to determine the probability of a given instance belonging to a particular class. The model uses these parameters to calculate probabilities for new instances, based on the feature values.
3. Training and Optimization
Training a model-based algorithm involves finding the optimal set of parameters that minimizes the difference between the model’s predictions and the actual values in the training data. This process is typically done using optimization algorithms like gradient descent, which iteratively adjusts parameters to reduce prediction errors. By minimizing the error, the model can produce more accurate predictions on unseen data.
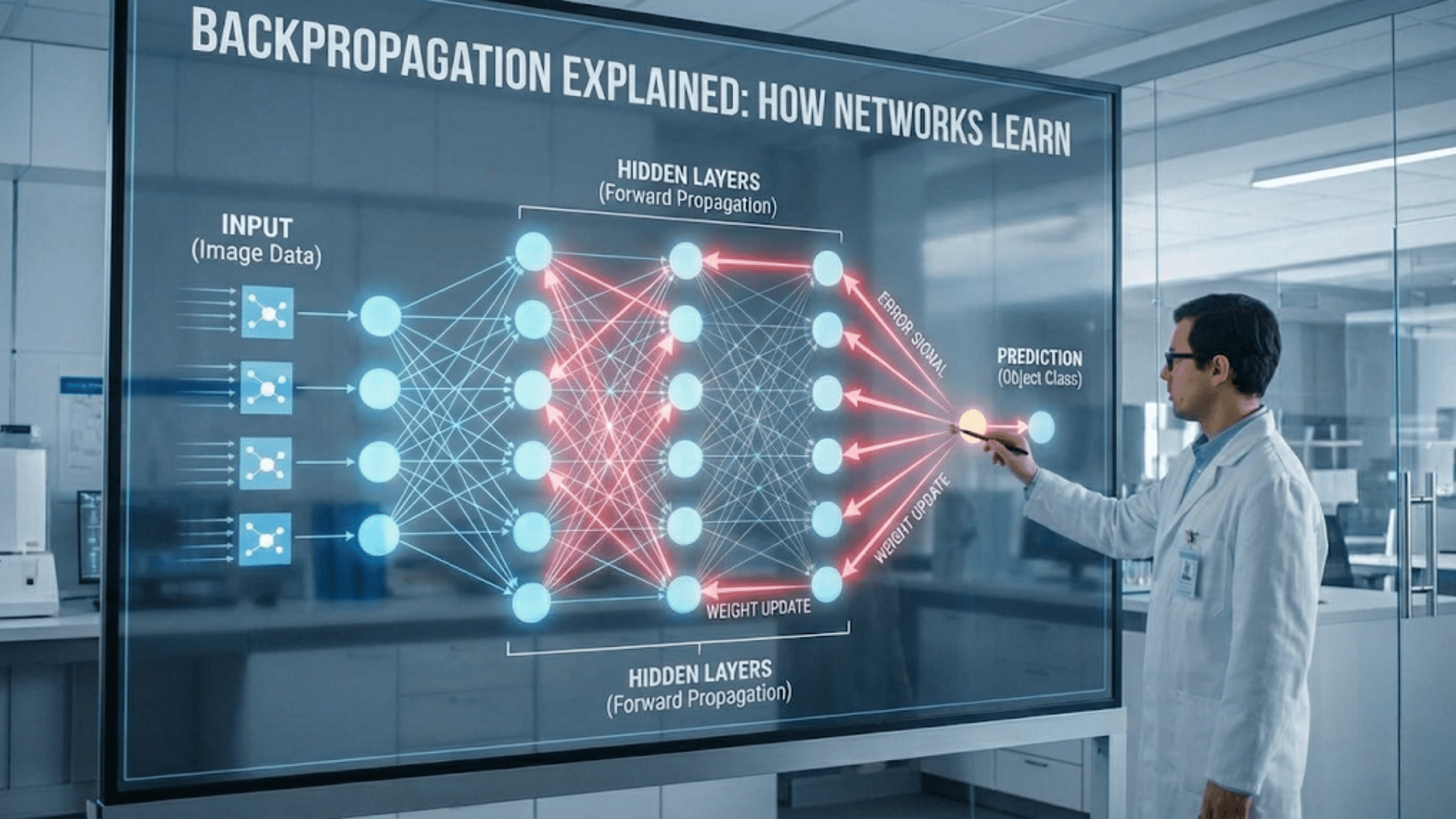
- Example: In neural networks, backpropagation is used to adjust weights and biases through gradient descent, allowing the model to improve its predictions by learning from its errors.
Model-based learning’s emphasis on generalization, parameter estimation, and optimization allows it to build a robust model that can make accurate predictions without relying on individual data instances.
Advantages of Model-Based Learning
Model-based learning offers several distinct advantages, making it suitable for tasks where pattern recognition, scalability, and interpretability are important. Here are some key benefits:
1. Scalability and Efficiency
Since model-based learning does not require storing each instance in the dataset, it is highly scalable and efficient, even with large datasets. Once trained, the model can make predictions using only the learned parameters, which significantly reduces memory usage and computation time.
- Example: In recommendation systems, a model-based algorithm like matrix factorization can predict user preferences without needing to retain detailed information about every user-item interaction, making it scalable for large platforms like Netflix or Amazon.
2. Ability to Capture Global Patterns
Model-based learning excels at capturing global patterns in data, which is valuable in tasks requiring high-level understanding rather than localized relationships. This global perspective allows the model to recognize overarching trends and generalize well across different scenarios.
- Example: In weather prediction, model-based algorithms use historical climate data to identify broad patterns, such as seasonal variations, allowing them to forecast future weather conditions more accurately.
3. Interpretability in Some Models
Certain model-based algorithms, like linear and logistic regression, offer high interpretability, as they produce coefficients or probabilities that indicate the contribution of each feature to the prediction. This interpretability makes model-based learning useful in fields that require transparency, such as healthcare and finance.
- Example: In credit scoring, logistic regression can show how factors like income, age, and credit history affect a borrower’s likelihood of defaulting, helping lenders make informed decisions while ensuring transparency.
4. Lower Risk of Overfitting
Model-based learning generally has a lower risk of overfitting compared to instance-based learning. Since the model learns from patterns across the entire dataset, it is less likely to rely on specific instances. Regularization techniques, such as L2 regularization in regression, can further reduce the chance of overfitting by penalizing complex models.
- Example: In medical diagnostics, a model-based algorithm can reduce overfitting by focusing on common patterns in patient data, such as symptoms and test results, rather than memorizing specific cases, improving its ability to generalize to new patients.
These advantages make model-based learning a powerful tool in applications that require efficiency, scalability, and the ability to generalize across large datasets.
Limitations of Model-Based Learning
Despite its strengths, model-based learning also has limitations that can make it less suitable for certain tasks. Here are some key limitations:
1. Requires Sufficiently Large Datasets for Accuracy
Model-based learning models rely on sufficient data to capture accurate patterns. When the dataset is small or lacks diversity, the model may fail to generalize well to new data, leading to poor performance.
- Example: In rare disease prediction, where data for certain diseases may be scarce, a model-based approach may struggle to recognize patterns accurately due to insufficient data, leading to inaccurate predictions.
2. Risk of Underfitting
Model-based learning can lead to underfitting if the model is too simple or if the chosen algorithm is not complex enough to capture the data’s underlying patterns. Underfitting results in low accuracy because the model fails to learn adequately from the data.
- Example: In image recognition, using a linear model might lead to underfitting, as images often contain complex, non-linear patterns that require more sophisticated models like neural networks for accurate classification.
3. Limited Interpretability in Complex Models
While some model-based algorithms, like linear regression, are easy to interpret, others—such as neural networks and support vector machines—can be complex and challenging to interpret. This lack of transparency can be problematic in applications where understanding the model’s decisions is important.
- Example: In financial forecasting, a neural network may provide accurate predictions but lack interpretability, making it difficult for analysts to explain the factors influencing the forecast.
4. Sensitivity to Hyperparameter Tuning
Model-based learning algorithms often require careful tuning of hyperparameters, such as learning rates, regularization parameters, or the number of layers in a neural network. Improper tuning can result in poor performance, requiring extensive experimentation to find optimal settings.
- Example: In natural language processing (NLP), training a transformer-based model for language understanding involves setting multiple hyperparameters. Suboptimal values can lead to inaccurate predictions or slow convergence, complicating model optimization.
While these limitations can affect the performance of model-based learning models, they can often be addressed through sufficient data collection, careful algorithm selection, and rigorous parameter tuning.
Comparison with Instance-Based Learning
Model-based learning is often contrasted with instance-based learning, which memorizes individual instances and makes predictions by comparing new data to these stored examples. Here’s a quick comparison:
- Model-Based Learning: Builds a generalizable model from the training data, requires parameter estimation, is suitable for tasks needing pattern recognition, and scales well with large datasets.
- Instance-Based Learning: Stores individual instances, relies on similarity measures, is ideal for tasks needing adaptability to new instances, but may be memory-intensive with large datasets.
For example, in customer segmentation, a model-based approach (such as clustering) could identify general groups of customers, while an instance-based approach (like KNN) would classify each customer based on specific similarities to others. The choice between model-based and instance-based learning depends on the application’s need for generalization versus instance-specific prediction.
Popular Algorithms in Model-Based Learning
Model-based learning encompasses a wide range of algorithms that differ in complexity, interpretability, and suitability for specific tasks. Here are some of the most popular model-based algorithms and their typical applications.
1. Linear Regression
Linear Regression is a foundational model-based learning algorithm used for predicting continuous values. It estimates the relationship between the target variable and one or more independent variables by fitting a line through the data points. The model calculates coefficients for each feature, representing the influence of each feature on the target variable.
- Example: In real estate, linear regression can predict housing prices based on features like square footage, number of rooms, and location, by establishing a linear relationship between these features and the sale price.
2. Logistic Regression
Logistic Regression is a classification algorithm used to predict binary or categorical outcomes. It models the probability of a certain class based on one or more features and is commonly used in binary classification tasks, such as spam detection or medical diagnosis. The model outputs probabilities for each class, which can be converted into classifications using a threshold.
- Example: In credit scoring, logistic regression is used to classify applicants as either low-risk or high-risk based on factors like income, age, and credit history.
3. Decision Trees
Decision Trees are tree-like structures that split data into subsets based on feature values. The model learns a series of decision rules from the data to arrive at a final classification or regression output. Decision trees are highly interpretable, as each decision point represents a feature-based rule, making it easy to understand how the model arrives at a prediction.
- Example: In loan approval systems, decision trees classify loan applicants by following a path through nodes that represent features like income level and employment status, ultimately predicting whether to approve or deny the application.
4. Support Vector Machines (SVM)
Support Vector Machines (SVM) are used for classification and regression tasks, especially when the data is high-dimensional or not linearly separable. SVM aims to find the optimal boundary (hyperplane) that separates data points of different classes. This approach works well for complex classification tasks and can handle both linear and non-linear data using kernel functions.
- Example: In image classification, SVM can classify images as different objects (e.g., cats or dogs) by finding a hyperplane that best separates the features of each class, making it suitable for visual pattern recognition.
5. Neural Networks
Neural Networks are powerful and versatile model-based learning algorithms inspired by the human brain. They consist of layers of interconnected nodes (neurons) that transform input data into a final output. Neural networks are particularly useful for complex tasks, such as image recognition, natural language processing, and speech recognition, and are the foundation for deep learning.
- Example: In speech recognition, neural networks process audio signals, breaking them down into recognizable patterns and identifying spoken words, making them ideal for voice-activated systems.
These algorithms each have strengths that make them suitable for different types of tasks. Choosing the right algorithm depends on the problem requirements, the data characteristics, and the balance between interpretability and complexity.
Step-by-Step Guide to Implementing a Model-Based Learning Model
Implementing a model-based learning model involves a series of steps, from data preparation to model selection, training, and evaluation. Here’s a guide to help you build an effective model-based learning model.
Step 1: Data Collection and Preprocessing
A model-based learning model’s accuracy depends on the quality of the data. Collect a comprehensive dataset and preprocess it to ensure the model learns accurate patterns. Data preprocessing steps may include data cleaning, handling missing values, and feature engineering.
- Data Cleaning: Remove duplicate entries, handle outliers, and address any inconsistencies in the data to ensure reliability.
- Feature Engineering: Create new features or transform existing ones to help the model capture meaningful patterns. This could include scaling numerical features or encoding categorical features for compatibility with certain algorithms.
from sklearn.preprocessing import StandardScaler, OneHotEncoder
# Example of scaling and encoding features
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
encoder = OneHotEncoder()
X_encoded = encoder.fit_transform(X_categorical)Step 2: Choosing the Model
Select a model based on the task requirements. For simple linear relationships, linear or logistic regression may be sufficient. For complex, non-linear data, decision trees, SVM, or neural networks may be more appropriate.
- Example: In a fraud detection system, logistic regression may work well if the data is linearly separable, but if the patterns are complex, a neural network may capture the nuances more effectively.
Step 3: Splitting the Data
Divide the dataset into training and testing sets to assess the model’s performance on unseen data. A common split is 80% for training and 20% for testing, though the exact ratio may vary depending on the dataset’s size and nature.
- Example: For a customer churn prediction model, splitting the data allows the model to learn from part of the dataset and evaluate its accuracy on the remaining data, ensuring it can generalize to new customer data.
Step 4: Training the Model
Once the data is ready, train the model by fitting it to the training dataset. During training, the model learns to adjust its parameters to minimize prediction errors. For complex models like neural networks, training may involve iterative optimization using algorithms like gradient descent.
from sklearn.linear_model import LogisticRegression
# Example of training a logistic regression model
model = LogisticRegression()
model.fit(X_train, y_train)Step 5: Model Evaluation
Evaluate the model’s performance on the testing set using relevant metrics, such as accuracy for classification, mean squared error (MSE) for regression, or F1-score for imbalanced datasets. Monitoring these metrics helps determine whether the model generalizes well to new data.
- Example: In spam detection, measure the model’s accuracy, precision, and recall to ensure it correctly identifies spam emails without misclassifying legitimate ones.
from sklearn.metrics import accuracy_score
# Example of evaluating a model's accuracy
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print("Model Accuracy:", accuracy)Step 6: Fine-Tuning and Hyperparameter Optimization
Fine-tuning the model involves adjusting hyperparameters to improve performance. For instance, tuning the regularization strength in logistic regression or the maximum depth in decision trees can help optimize accuracy and prevent overfitting.
- Example: In a decision tree, increasing the maximum depth might improve accuracy but could also lead to overfitting, so careful tuning is necessary to balance performance and generalizability.
from sklearn.model_selection import GridSearchCV
# Example of hyperparameter tuning for a decision tree
from sklearn.tree import DecisionTreeClassifier
param_grid = {'max_depth': [3, 5, 10]}
grid_search = GridSearchCV(DecisionTreeClassifier(), param_grid, cv=5)
grid_search.fit(X_train, y_train)Step 7: Model Deployment
Once evaluated and fine-tuned, deploy the model for use in a real-world setting. Model-based learning models often require periodic retraining to stay accurate, especially if the data distribution changes over time.
- Example: In a financial forecasting application, the model may need to be retrained periodically to reflect changes in market trends, ensuring predictions remain reliable.
By following these steps, practitioners can implement effective model-based learning models that are accurate, generalizable, and optimized for real-world applications.
Practical Considerations for Optimizing Model-Based Learning
While model-based learning models offer scalability and generalization, several practical considerations can help ensure they operate efficiently and accurately.
1. Feature Engineering and Selection
Feature engineering can significantly impact the model’s performance. Selecting the most relevant features or creating new ones helps the model learn meaningful patterns, reducing noise and enhancing interpretability.
- Best Practice: Use domain knowledge to guide feature selection and consider using techniques like Principal Component Analysis (PCA) to reduce dimensionality, especially with high-dimensional datasets.
2. Regularization to Prevent Overfitting
Overfitting is a common challenge in model-based learning, where the model becomes too specific to the training data. Regularization techniques, such as L2 regularization in regression, penalize large coefficients, promoting simpler models that generalize better.
- Best Practice: Apply regularization based on the complexity of the data and model type. For example, regularization is critical in neural networks to prevent overfitting, especially in smaller datasets.
3. Cross-Validation for Robust Evaluation
Cross-validation is an effective technique to evaluate model performance and ensure it generalizes well. By training and testing the model across multiple subsets of the data, cross-validation reduces the risk of biased results due to random data splits.
- Best Practice: Use k-fold cross-validation, where the dataset is split into k subsets, and the model is trained and evaluated on each subset. This approach improves reliability, particularly when data is limited.
4. Hyperparameter Tuning for Optimal Performance
Many model-based algorithms require tuning of hyperparameters for optimal performance. Techniques like grid search and random search help identify the best combination of parameters by testing multiple configurations.
- Best Practice: Use automated hyperparameter tuning methods like GridSearchCV in scikit-learn or Bayesian optimization for large, complex models where manual tuning would be inefficient.
5. Monitor for Concept Drift in Dynamic Environments
In dynamic environments where data distributions change over time, concept drift can degrade model performance. Regularly monitoring performance metrics and retraining the model as needed ensures it remains accurate.
- Best Practice: Implement a retraining schedule and monitor key performance metrics. When accuracy declines due to concept drift, retrain the model using updated data.
By addressing these considerations, practitioners can build robust model-based learning models that perform well in various environments, providing scalable, accurate, and efficient solutions for predictive tasks.
Real-World Applications of Model-Based Learning
Model-based learning is widely applied across various industries, particularly where scalability, pattern recognition, and predictive accuracy are required. Here are some key applications of model-based learning:
1. Financial Forecasting and Risk Analysis
Model-based learning plays a significant role in financial services, where models predict stock prices, evaluate risks, and detect fraudulent activities. The ability to generalize from past data allows these models to capture trends and predict future behaviors effectively.
- Example: In risk analysis, logistic regression models assess the likelihood of credit default by learning from historical borrower data. By generalizing from past cases, the model helps financial institutions make informed lending decisions, balancing risk and profitability.
2. Image Recognition and Computer Vision
In computer vision, model-based learning models, especially neural networks, excel at recognizing patterns and classifying images. By learning from large datasets, these models can identify objects, people, and even emotions in images, making them useful for automated image processing in numerous fields.
- Example: Self-driving cars rely on convolutional neural networks (CNNs) to interpret visual data from cameras. These models recognize road signs, pedestrians, and obstacles, ensuring safe navigation by predicting the location and behavior of objects in real time.
3. Healthcare and Medical Diagnostics
Model-based learning models support healthcare professionals by aiding in disease prediction, medical imaging, and patient monitoring. By identifying patterns in medical data, these models assist in early diagnosis and personalized treatment recommendations, improving patient outcomes.
- Example: In cancer detection, neural networks analyze medical images, such as MRIs or CT scans, to identify potential tumors. By training on labeled images, these models learn to recognize patterns that indicate malignancy, enabling early and accurate diagnosis.
4. Customer Churn Prediction in Retail and Telecommunications
In customer-centric industries, model-based learning models help predict customer churn, allowing businesses to identify and retain at-risk customers. These models analyze historical customer behavior to recognize factors associated with churn, empowering companies to take preventive actions.
- Example: In telecommunications, logistic regression models predict customer churn by examining usage patterns, service complaints, and demographic factors. This helps telecom companies proactively engage with customers who may be considering leaving.
5. Natural Language Processing (NLP) for Sentiment Analysis
Model-based learning models are essential in NLP tasks, including sentiment analysis, machine translation, and speech recognition. By learning from large text corpora, these models can understand language structure, sentiment, and intent, enabling applications in customer service and social media monitoring.
- Example: In sentiment analysis, a support vector machine (SVM) classifies customer feedback as positive, neutral, or negative. This allows companies to gauge customer sentiment toward products or services and adapt their strategies accordingly.
These applications demonstrate the versatility of model-based learning in handling complex, large-scale problems across industries that require reliable predictions, generalization, and interpretability.
Future Trends in Model-Based Learning
As machine learning advances, several trends are emerging that enhance the capabilities and applicability of model-based learning models.
1. Integration of Model-Based and Instance-Based Learning
Hybrid models that combine model-based and instance-based approaches are becoming more common. These models benefit from the generalization ability of model-based learning and the adaptability of instance-based learning, making them effective for tasks where both global and local patterns are relevant.
- Example: In recommendation systems, a hybrid approach could use collaborative filtering (model-based) to identify general user preferences, combined with KNN (instance-based) to provide recommendations based on the most similar users.
2. Transfer Learning and Pre-Trained Models
Transfer learning enables models to apply knowledge from one task to another, reducing the need for extensive training on new data. Pre-trained models, especially in NLP and computer vision, are becoming standard, allowing organizations to leverage sophisticated, high-performing models with minimal customization.
- Example: In medical imaging, a pre-trained model on general image recognition tasks can be fine-tuned on a smaller medical dataset, providing accurate predictions without needing an extensive training set.
3. Model Interpretability and Explainable AI (XAI)
As machine learning applications expand into regulated industries like healthcare and finance, the demand for explainable AI (XAI) is rising. Techniques for making complex models more interpretable—such as SHAP (Shapley Additive Explanations) and LIME (Local Interpretable Model-agnostic Explanations)—are increasingly integrated into model-based learning.
- Example: In financial forecasting, explainability tools can help analysts understand the factors driving predictions, making neural network models more transparent for decision-makers.
4. Automated Machine Learning (AutoML) and Hyperparameter Optimization
AutoML platforms are simplifying model-based learning by automating the selection, training, and tuning of models, making machine learning accessible to non-experts. AutoML platforms also include hyperparameter optimization tools, streamlining the tuning process to produce high-quality models with minimal manual intervention.
- Example: Small businesses can use AutoML to build predictive models for demand forecasting, allowing them to make data-driven decisions without a dedicated data science team.
5. Handling Concept Drift in Dynamic Environments
Concept drift, where the data distribution changes over time, is a challenge for model-based learning models in dynamic fields. New algorithms for detecting and adapting to drift are helping models stay accurate over time, ensuring their predictions remain relevant as conditions evolve.
- Example: In stock market prediction, concept drift detection helps financial models adapt to economic shifts, ensuring that forecasts reflect the latest market trends.
These trends are advancing model-based learning’s capabilities, making it more flexible, interpretable, and accessible for a broader range of applications.
Best Practices for Optimizing Model-Based Learning Models
To build and deploy effective model-based learning models, it’s important to follow best practices that ensure accuracy, scalability, and reliability.
1. Ensure Data Quality and Feature Engineering
Model-based learning models rely heavily on data quality. Proper data cleaning, feature selection, and feature engineering are crucial for ensuring that the model captures the most relevant information and can generalize accurately.
- Best Practice: Conduct thorough data exploration, removing outliers and irrelevant features. Feature engineering should focus on creating informative features that enhance the model’s predictive power, such as transforming categorical variables or aggregating numerical data.
2. Regularization to Improve Generalization
Regularization techniques, like L1 and L2 regularization, reduce the risk of overfitting by penalizing overly complex models. Regularization is especially important in models like linear regression, where high-dimensional data can lead to poor generalization.
- Best Practice: Apply regularization based on model complexity and data characteristics. For example, L2 regularization helps simplify linear models by minimizing large coefficients, while dropout regularization is beneficial in neural networks.
3. Use Cross-Validation for Robust Model Evaluation
Cross-validation provides a reliable measure of model performance by training and testing on multiple data splits. This approach reduces the risk of overfitting and ensures that the model’s performance metrics are robust and consistent across different subsets of the data.
- Best Practice: Use k-fold cross-validation to evaluate models, particularly when working with small or imbalanced datasets. For more reliable results, consider using stratified k-fold cross-validation, which maintains the proportion of classes in each fold for classification tasks.
4. Tune Hyperparameters for Optimal Performance
Hyperparameter tuning is critical to improving model performance. Methods like grid search, random search, and Bayesian optimization help identify the optimal combination of hyperparameters, maximizing the model’s accuracy and efficiency.
- Best Practice: Use automated tuning methods, such as GridSearchCV in scikit-learn, to streamline hyperparameter selection. For complex models, consider using Bayesian optimization, which balances exploration and exploitation to find the best hyperparameter settings efficiently.
5. Implement Concept Drift Detection in Dynamic Environments
In industries where data distributions evolve, such as finance and e-commerce, monitoring for concept drift helps ensure models remain accurate. Implement drift detection methods to trigger model retraining when significant changes are detected.
- Best Practice: Set thresholds for performance metrics to indicate drift, and use monitoring tools to track prediction accuracy over time. Retrain models regularly or as soon as drift is detected to keep predictions relevant.
6. Prioritize Model Interpretability When Necessary
In fields like healthcare, finance, and legal services, interpretability is crucial for trust and compliance. Choose interpretable models, such as linear or logistic regression, or apply model interpretation tools to more complex models to ensure transparency.
- Best Practice: For models like neural networks, use interpretability tools like SHAP or LIME to explain feature importance and individual predictions. This helps stakeholders understand the model’s decisions and builds trust in its predictions.
By following these best practices, practitioners can develop model-based learning models that are accurate, scalable, and well-suited to dynamic real-world applications.
The Significance of Model-Based Learning
Model-based learning is a foundational approach in machine learning, enabling models to generalize from data, recognize patterns, and make predictions on unseen data. Unlike instance-based learning, which relies on specific examples, model-based learning builds a generalized model that can efficiently scale to large datasets, making it ideal for tasks requiring high-level understanding and prediction accuracy.
From financial forecasting and healthcare diagnostics to image recognition and customer churn prediction, model-based learning models are transforming industries by enabling more data-driven decision-making. The growing capabilities of these models, such as hybrid models, transfer learning, and interpretability tools, further expand their applicability across a range of domains. Emerging trends, including AutoML and concept drift detection, are making model-based learning more accessible and adaptable, ensuring that models can meet the demands of fast-paced environments.
By adhering to best practices—such as ensuring data quality, regularizing models to prevent overfitting, tuning hyperparameters, and implementing drift detection—data scientists can build robust model-based learning models that deliver accurate, interpretable, and scalable solutions for modern AI challenges. As technology evolves, model-based learning will continue to play a critical role in advancing AI and machine learning, offering reliable predictions and actionable insights for businesses and organizations worldwide.