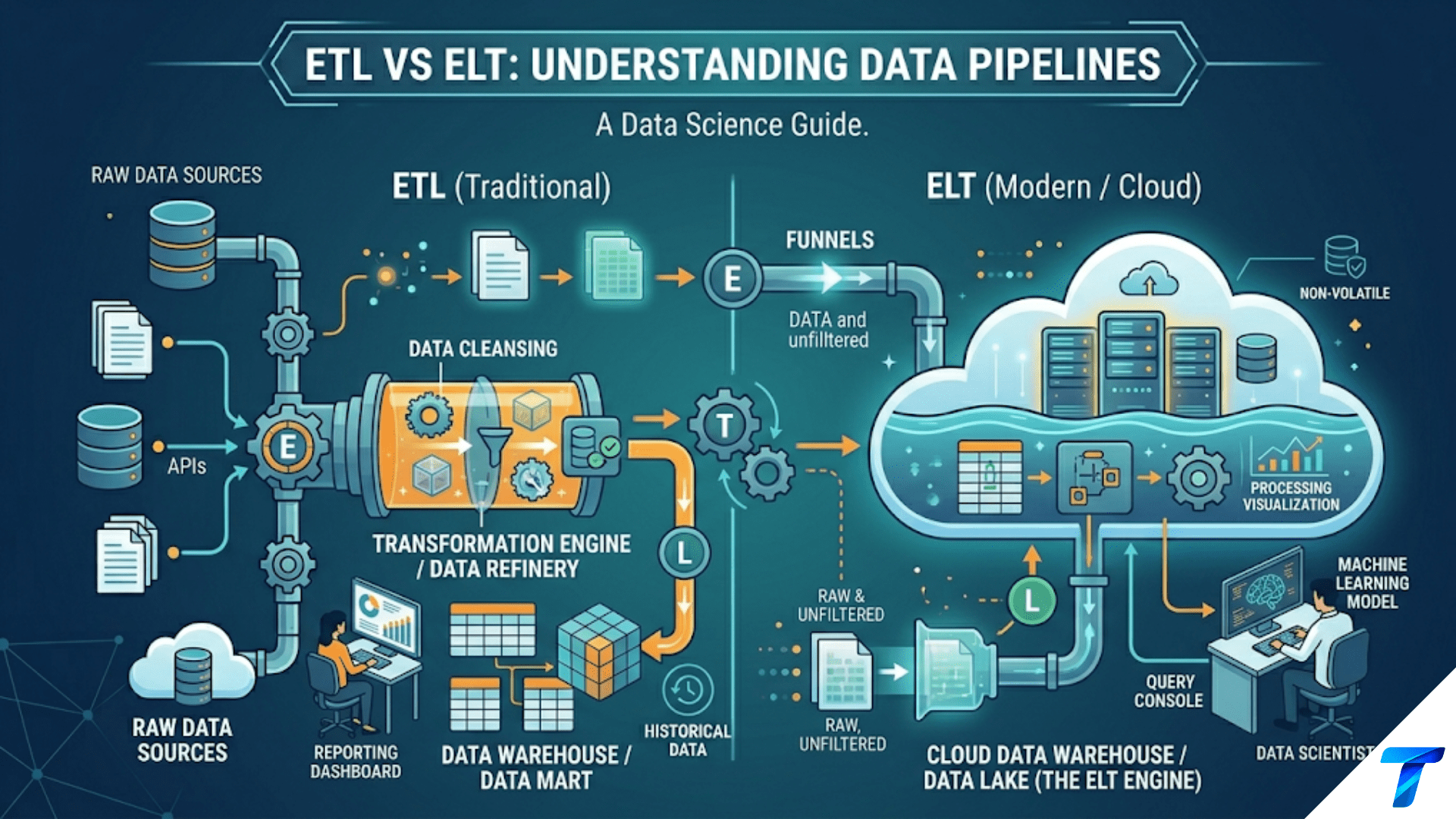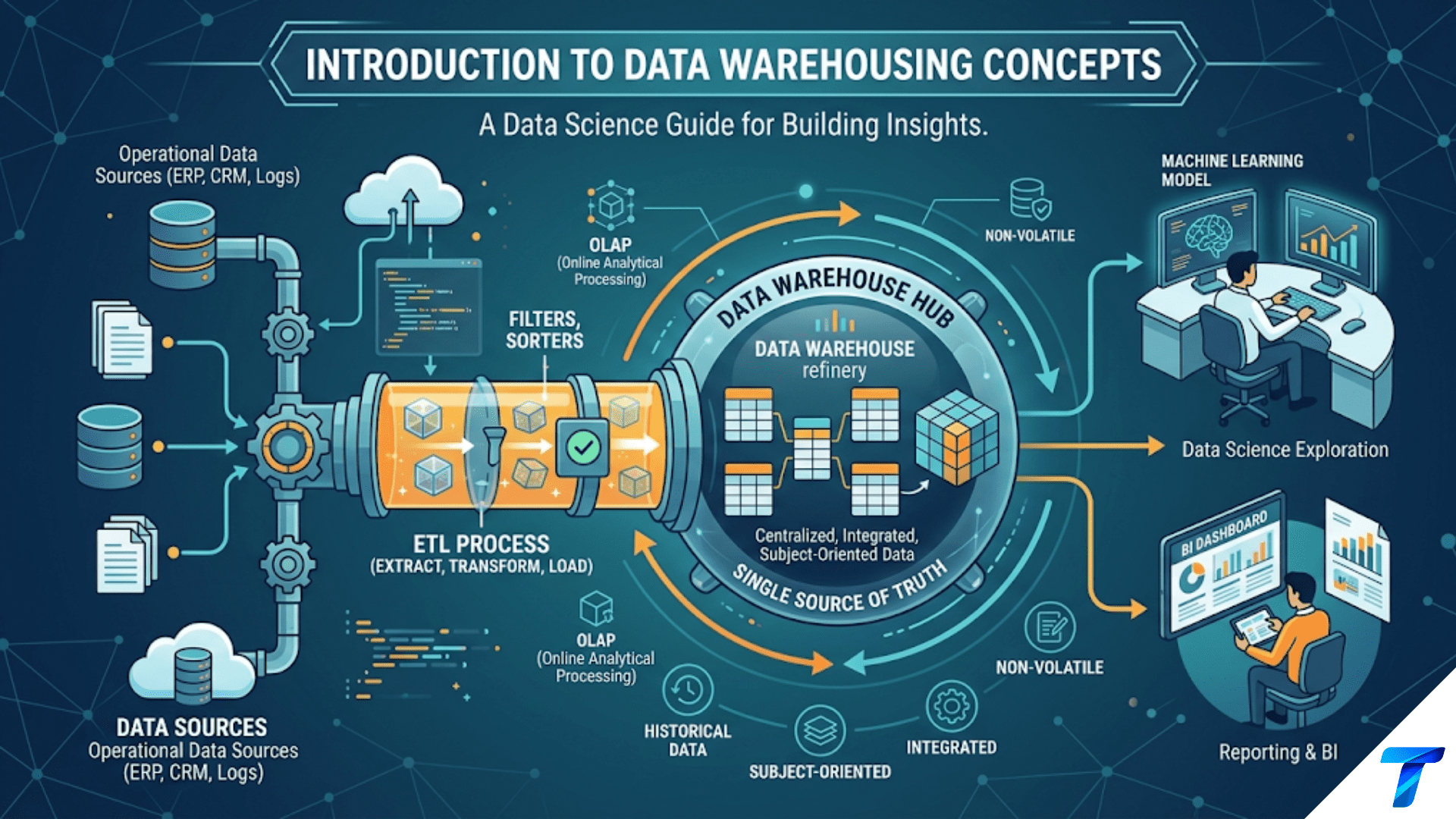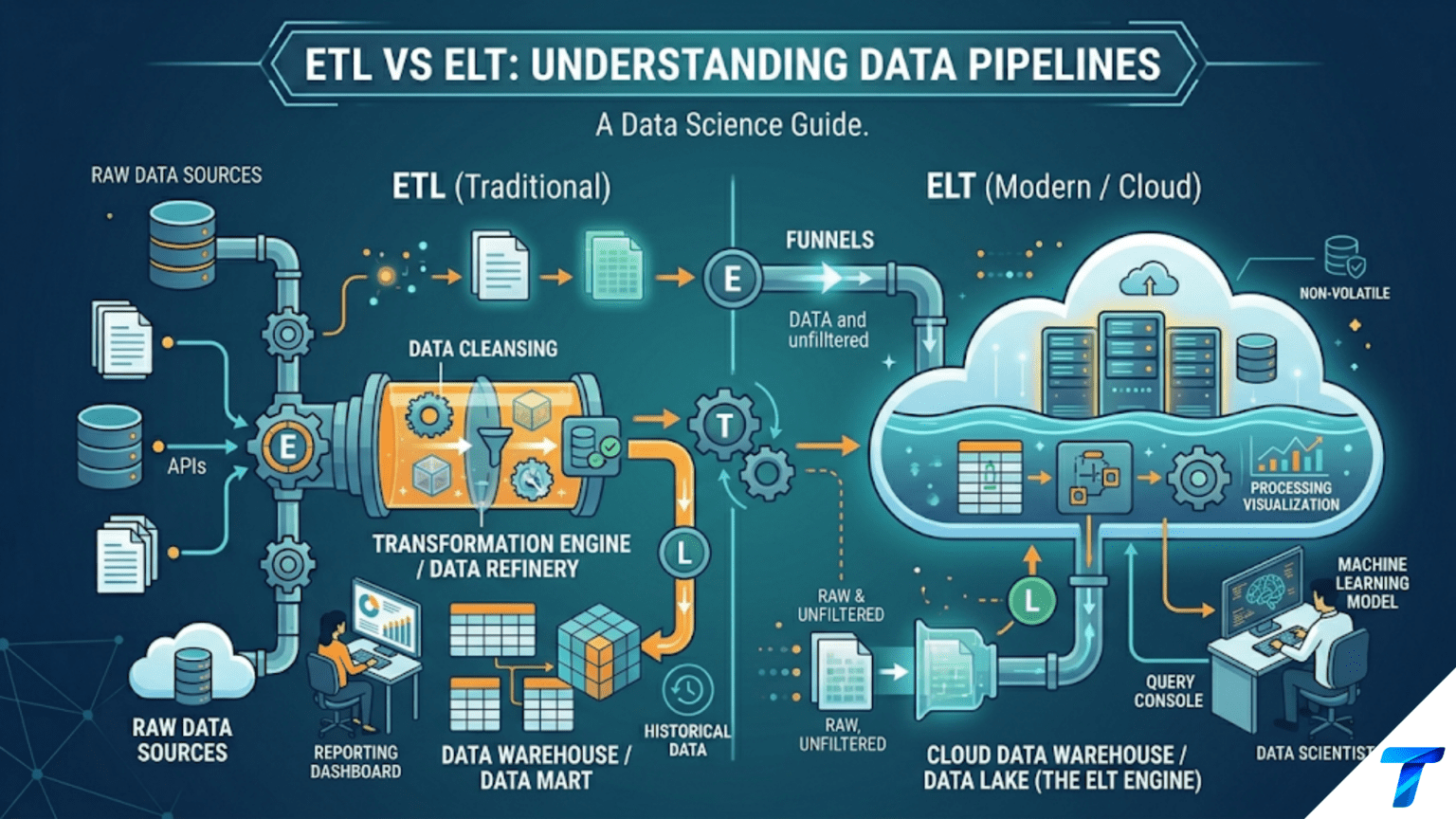
ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform) are the two fundamental patterns for moving data from source systems into analytical stores. In ETL, data is extracted from sources, transformed into a clean and structured form in an intermediate processing layer, then loaded into the destination. In ELT, data is extracted and loaded first — in raw form — into the destination system, and transformations happen there afterward, using the compute power of the destination (a cloud data warehouse or data lake). Modern data teams predominantly use ELT because cloud warehouses have abundant compute that is cheaper and more scalable than maintaining a separate transformation server, and raw data is always preserved for reprocessing.
Introduction
Every data scientist depends on data pipelines, even when they’re not building them. The dashboard you’re interpreting, the feature table you’re training a model on, the customer list you’re analyzing — all of it arrived through a pipeline that extracted it from source systems, applied transformations, and loaded it somewhere analytical. Understanding how that pipeline works is not optional background knowledge; it directly affects what you can do with the data, how fresh it is, what errors might be hidden in it, and how you can get new data sources added.
Data pipelines are the plumbing of a data organization. Like the plumbing in a building, you notice them most when something goes wrong — the table that should have yesterday’s data still shows last week’s, the join that used to work started producing unexpected nulls, the feature engineering step that takes 4 hours is blocking the morning model run. Understanding the architecture of pipelines helps you diagnose these problems, communicate with data engineers, and — increasingly for data scientists — build your own simple pipelines.
This article covers the complete picture: what ETL and ELT are and how they differ, the tradeoffs between them, the modern tool ecosystem, how to build simple pipelines in Python, pipeline design principles, common failure patterns and how to avoid them, and what data scientists need to know about the pipelines they depend on.
What Is a Data Pipeline?
A data pipeline is a sequence of automated steps that moves data from one or more sources to a destination, with some transformation applied along the way. The most basic pipeline is three steps:
[Source System] ──── Extract ──── Transform ──── Load ──── [Destination]Extract: Retrieve data from a source — a database, an API, a file system, a message queue, a SaaS application. The extraction might be a full dump of the entire table, or an incremental update of only the records that changed since the last run.
Transform: Change the data — clean it, filter it, join it with other data, rename columns, cast types, apply business logic, aggregate it, derive new columns. This is where business rules are encoded.
Load: Write the transformed data to the destination — a data warehouse, a data lake, a dashboard database, a feature store, an operational database, or a file.
The three steps apply to both ETL and ELT. The difference is order and location.
ETL: Transform Before Loading
In the ETL pattern, transformation happens between extraction and loading — in a separate processing layer that is neither the source nor the destination.
Source Systems Processing Server Destination
(OLTP databases, (Data Warehouse)
APIs, flat files)
│ │ │
│ 1. Extract │ 2. Transform │
│ (raw data) │ (business rules │
│──────────────────────► │ applied here) │
│ │ │
│ │ 3. Load │
│ │ (only clean, structured │
│ │ data goes to warehouse) │
│ │ ──────────────────────► │How ETL Works
- Extract: The ETL tool queries the source systems on a schedule (nightly, hourly). It might pull entire tables (full extract) or only rows modified since the last run (incremental extract using a
updated_attimestamp or change data capture). - Transform: In a dedicated processing environment (historically, a server running the ETL tool), transformations are applied: data type casting, null handling, deduplication, joining reference data, applying business rules, calculating derived columns.
- Load: Only the clean, transformed data is written to the destination warehouse. If transformation fails, nothing is loaded. The warehouse never sees dirty data.
ETL Tools (Historical)
Classic ETL tools like Informatica, IBM DataStage, Microsoft SSIS, and Talend provide visual workflow designers where you drag and drop transformation steps. They handle scheduling, dependency management, error logging, and retry logic.
These tools were designed when:
- Data warehouses were expensive on-premises servers with limited compute
- Raw data storage was expensive — you only wanted clean data in the warehouse
- Transformations needed to happen before loading to preserve expensive warehouse space
ETL’s Advantages
- Destination always clean: The warehouse only receives validated, transformed data
- Privacy compliance: Sensitive data (SSNs, credit card numbers) can be masked or removed before ever reaching the warehouse
- Reduces warehouse load: Transformations happen externally, preserving warehouse compute
- Works with limited destination compute: Appropriate when the destination can’t run heavy transformations
ETL’s Disadvantages
- Separate transformation infrastructure: Need to maintain and scale ETL servers
- Schema coupling: If transformation logic changes, the pipeline may need to be rebuilt
- Raw data is lost: Once transformed and loaded, the original raw data may not be preserved
- Debugging difficulty: Errors in the transformation layer are separate from the warehouse, requiring different tools to investigate
- Rigid: Changing what the transformation produces often requires a complete rewrite
ELT: Load First, Transform in Place
In the ELT pattern, raw data is loaded into the destination first. Transformations happen inside the destination — using the destination’s compute engine.
Source Systems Destination (Cloud Warehouse / Data Lake)
(OLTP databases,
APIs, flat files)
│ │
│ 1. Extract + Load (raw data) │
│───────────────────────────────► Raw Layer
│ │
│ │ 2. Transform (SQL inside the warehouse)
│ │
│ ▼
│ Cleaned / Modeled Layer
│ │
│ ▼
│ Presentation / Mart LayerHow ELT Works
- Extract + Load: Raw data from source systems is loaded directly into the destination’s raw/staging area with minimal transformation — just enough to get it into a queryable format (parse dates, handle encoding, basic schema mapping). Modern ingestion tools (Fivetran, Airbyte) handle this automatically for hundreds of connectors.
- Transform (inside the warehouse): SQL-based transformations run inside the warehouse using its native compute. A query reads from the raw tables, applies business logic, and writes clean results to new tables. dbt (data build tool) is the dominant tool for this step.
The Role of Cloud Warehouses in ELT
ELT became practical — and then dominant — because of cloud data warehouses. BigQuery, Snowflake, and Redshift have essentially unlimited compute that scales elastically, charging per byte scanned or per compute unit used. Running transformations directly in the warehouse became:
- Cheaper than maintaining dedicated ETL infrastructure
- Faster than pushing data out to an external server, transforming it, and pushing it back
- More reliable because transformations run on the same system as the destination data
- More reproducible because SQL transformations are version-controllable and testable
ELT’s Advantages
- Raw data preserved: The full history of source data is always available for reprocessing
- Flexible reprocessing: When business logic changes, re-run the transformation SQL against the already-loaded raw data — no need to re-extract from source systems
- Simplicity: Fewer moving parts — one system (the warehouse) stores and transforms data
- Transparency: SQL transformations are readable, testable, and version-controlled
- Debuggability: Data engineers and analysts can query intermediate stages directly
- Ecosystem maturity: Modern tools (dbt, Airflow, Prefect) are specifically designed for ELT
ELT’s Disadvantages
- Raw data in the warehouse: Sensitive data arrives raw before masking; requires careful access controls
- Warehouse compute costs: Heavy transformations consume warehouse credits; need monitoring
- Destination dependency: Transformation logic is tightly coupled to the destination’s SQL dialect
- Not for streaming: ELT is fundamentally batch-oriented; streaming data needs different patterns
The Modern Data Pipeline: A Concrete Example
Let’s trace the journey of data through a modern ELT pipeline from source to ML-ready features:
E-commerce OLTP DB Data Warehouse (Snowflake)
(PostgreSQL) │
│
Raw orders table ──── Fivetran ────► RAW_DB.POSTGRES.ORDERS
Raw customers table RAW_DB.POSTGRES.CUSTOMERS
Raw products table RAW_DB.POSTGRES.PRODUCTS
│
│ dbt (SQL transformations)
│
▼
STAGING:
stg_orders (cleaned, typed)
stg_customers (cleaned, typed)
stg_products (cleaned, typed)
│
▼
MART:
fct_sales (fact table)
dim_customer (customer dimension)
dim_product (product dimension)
│
├──► BI tools (Tableau, Looker)
│
└──► ML features
(Python queries warehouse)Building Simple Python Pipelines
While production ETL/ELT uses specialized tools, data scientists often need to build simple pipelines for their own work. Here’s a production-quality pattern for Python pipelines.
A Well-Structured Pipeline Module
# pipelines/customer_features_pipeline.py
"""
Customer feature engineering pipeline.
Extracts customer and order data from the data warehouse,
engineers features, and writes the result back for ML consumption.
Run: python -m pipelines.customer_features_pipeline
"""
import os
import logging
import pandas as pd
import numpy as np
from datetime import datetime, timezone
from pathlib import Path
from dotenv import load_dotenv
from sqlalchemy import create_engine
load_dotenv()
logging.basicConfig(
level=logging.INFO,
format="%(asctime)s [%(levelname)s] %(name)s: %(message)s",
datefmt="%Y-%m-%d %H:%M:%S"
)
logger = logging.getLogger(__name__)
# ── Configuration ─────────────────────────────────────────────────────────────
CONFIG = {
"reference_date": datetime(2024, 9, 15, tzinfo=timezone.utc),
"lookback_days": 365,
"min_orders": 2, # Minimum orders for a customer to be included
"output_table": "ml.customer_churn_features",
"output_path": "data/processed/customer_features.parquet"
}
# ── Extract ────────────────────────────────────────────────────────────────────
def extract_customers(engine) -> pd.DataFrame:
"""Extract current customer records from the warehouse."""
logger.info("Extracting customer data...")
query = """
SELECT
customer_key,
customer_id,
customer_segment,
region,
country,
signup_date,
is_premium
FROM dim_customer
WHERE is_current = TRUE
"""
df = pd.read_sql(query, engine, parse_dates=["signup_date"])
logger.info(f"Extracted {len(df):,} customers")
return df
def extract_order_history(engine, lookback_days: int) -> pd.DataFrame:
"""Extract order history for the lookback period."""
logger.info(f"Extracting {lookback_days}-day order history...")
query = f"""
SELECT
f.customer_key,
f.order_date_key,
d.full_date AS order_date,
f.line_revenue,
f.quantity_sold,
f.gross_profit,
p.category AS product_category
FROM fact_sales f
JOIN dim_date d ON f.order_date_key = d.date_key
JOIN dim_product p ON f.product_key = p.product_key
WHERE d.full_date >= CURRENT_DATE - INTERVAL '{lookback_days} days'
"""
df = pd.read_sql(query, engine, parse_dates=["order_date"])
logger.info(f"Extracted {len(df):,} order line items")
return df
def extract_support_tickets(engine, lookback_days: int) -> pd.DataFrame:
"""Extract support ticket history."""
logger.info("Extracting support ticket data...")
query = f"""
SELECT
customer_key,
ticket_date,
severity,
resolved_within_sla
FROM fact_support_tickets
WHERE ticket_date >= CURRENT_DATE - INTERVAL '{lookback_days} days'
"""
df = pd.read_sql(query, engine, parse_dates=["ticket_date"])
logger.info(f"Extracted {len(df):,} support tickets")
return df
# ── Transform ──────────────────────────────────────────────────────────────────
def transform_order_features(
orders_df: pd.DataFrame,
reference_date: datetime
) -> pd.DataFrame:
"""
Aggregate order history to customer-level features.
Parameters
----------
orders_df : pd.DataFrame
Order line items at transaction grain.
reference_date : datetime
Reference point for computing recency features.
Returns
-------
pd.DataFrame
One row per customer with order-based features.
"""
logger.info("Computing order features...")
ref_ts = pd.Timestamp(reference_date)
# Aggregate to customer grain
order_features = orders_df.groupby("customer_key").agg(
total_revenue = ("line_revenue", "sum"),
total_units = ("quantity_sold", "sum"),
total_gross_profit = ("gross_profit", "sum"),
n_line_items = ("line_revenue", "count"),
n_distinct_days = ("order_date", "nunique"),
n_categories = ("product_category", "nunique"),
avg_order_value = ("line_revenue", "mean"),
last_order_date = ("order_date", "max"),
first_order_date = ("order_date", "min"),
).reset_index()
# Derived features
order_features["recency_days"] = (
ref_ts - order_features["last_order_date"]
).dt.days
order_features["order_frequency_days"] = np.where(
order_features["n_distinct_days"] > 1,
(order_features["last_order_date"] - order_features["first_order_date"]).dt.days
/ (order_features["n_distinct_days"] - 1),
None
)
order_features["gross_margin_pct"] = (
order_features["total_gross_profit"] /
order_features["total_revenue"].replace(0, np.nan) * 100
)
logger.info(f"Computed order features for {len(order_features):,} customers")
return order_features
def transform_ticket_features(tickets_df: pd.DataFrame) -> pd.DataFrame:
"""Aggregate support ticket history to customer-level features."""
logger.info("Computing support ticket features...")
ticket_features = tickets_df.groupby("customer_key").agg(
n_tickets = ("ticket_date", "count"),
n_high_severity = ("severity", lambda x: (x == "high").sum()),
n_sla_breaches = ("resolved_within_sla", lambda x: (~x).sum()),
most_recent_ticket = ("ticket_date", "max"),
).reset_index()
ticket_features["sla_breach_rate"] = (
ticket_features["n_sla_breaches"] /
ticket_features["n_tickets"].replace(0, np.nan)
)
logger.info(f"Computed ticket features for {len(ticket_features):,} customers")
return ticket_features
def join_all_features(
customers_df: pd.DataFrame,
order_features: pd.DataFrame,
ticket_features: pd.DataFrame,
config: dict
) -> pd.DataFrame:
"""
Join all feature sets to the customer grain and finalize the feature table.
"""
logger.info("Joining feature sets to customer grain...")
ref_ts = pd.Timestamp(config["reference_date"])
# Left join: keep all customers, NaN for those without orders/tickets
df = customers_df.merge(order_features, on="customer_key", how="left")
df = df.merge(ticket_features, on="customer_key", how="left")
# Customer-level features from the customer dimension
df["tenure_days"] = (ref_ts - df["signup_date"]).dt.days
# Fill NaN for customers with no activity
fill_zeros = [
"n_line_items", "n_distinct_days", "n_categories",
"total_revenue", "total_units", "n_tickets",
"n_high_severity", "n_sla_breaches"
]
df[fill_zeros] = df[fill_zeros].fillna(0)
df["recency_days"] = df["recency_days"].fillna(999) # 999 = never ordered
# Filter to customers meeting minimum order threshold
before = len(df)
df = df[df["n_distinct_days"] >= config["min_orders"]].copy()
logger.info(f"Filtered to {len(df):,} customers with ≥{config['min_orders']} orders "
f"(removed {before - len(df):,})")
# Add pipeline metadata
df["feature_date"] = ref_ts.date()
df["pipeline_version"] = "v1.2"
df["created_at"] = datetime.now(timezone.utc)
return df
def validate_features(df: pd.DataFrame) -> bool:
"""
Run data quality checks on the feature table before loading.
Returns True if all checks pass, raises ValueError otherwise.
"""
logger.info("Validating feature table...")
errors = []
# Row count check
if len(df) < 100:
errors.append(f"Too few rows: {len(df)} (expected ≥ 100)")
# Primary key uniqueness
if df["customer_key"].duplicated().sum() > 0:
errors.append("Duplicate customer_key values found — grain violation!")
# No nulls in key columns
key_cols = ["customer_key", "customer_id", "total_revenue", "recency_days"]
for col in key_cols:
null_count = df[col].isna().sum()
if null_count > 0:
errors.append(f"Unexpected nulls in {col}: {null_count}")
# Logical value checks
if (df["total_revenue"] < 0).any():
errors.append("Negative total_revenue values found")
if (df["recency_days"] < 0).any():
errors.append("Negative recency_days values found")
if errors:
for err in errors:
logger.error(f"Validation failed: {err}")
raise ValueError(f"Feature validation failed: {len(errors)} errors")
logger.info(f"✓ Validation passed: {len(df):,} rows, {len(df.columns)} columns")
return True
# ── Load ───────────────────────────────────────────────────────────────────────
def load_to_parquet(df: pd.DataFrame, output_path: str) -> None:
"""Write features to Parquet file."""
Path(output_path).parent.mkdir(parents=True, exist_ok=True)
df.to_parquet(output_path, index=False, compression="snappy")
size_mb = Path(output_path).stat().st_size / 1e6
logger.info(f"Loaded {len(df):,} rows to {output_path} ({size_mb:.1f} MB)")
def load_to_warehouse(df: pd.DataFrame, engine, table_name: str) -> None:
"""Write features back to the data warehouse."""
schema, table = table_name.split(".", 1) if "." in table_name else ("public", table_name)
df.to_sql(
name=table,
con=engine,
schema=schema,
if_exists="replace",
index=False,
method="multi",
chunksize=1000
)
logger.info(f"Loaded {len(df):,} rows to {table_name}")
# ── Pipeline Orchestration ─────────────────────────────────────────────────────
def run_pipeline() -> dict:
"""
Execute the complete customer feature pipeline.
Returns a dict of run statistics for monitoring.
"""
start_time = datetime.now(timezone.utc)
logger.info("=" * 60)
logger.info("Starting Customer Feature Pipeline")
logger.info(f"Reference date: {CONFIG['reference_date']}")
logger.info("=" * 60)
engine = create_engine(
f"postgresql+psycopg2://"
f"{os.environ['DW_USER']}:{os.environ['DW_PASSWORD']}"
f"@{os.environ['DW_HOST']}:{os.environ['DW_PORT']}/{os.environ['DW_DB']}"
)
try:
# ── Extract ──────────────────────────────────────────────
customers = extract_customers(engine)
orders = extract_order_history(engine, CONFIG["lookback_days"])
tickets = extract_support_tickets(engine, CONFIG["lookback_days"])
# ── Transform ────────────────────────────────────────────
order_features = transform_order_features(orders, CONFIG["reference_date"])
ticket_features = transform_ticket_features(tickets)
features_df = join_all_features(
customers, order_features, ticket_features, CONFIG
)
# ── Validate ─────────────────────────────────────────────
validate_features(features_df)
# ── Load ─────────────────────────────────────────────────
load_to_parquet(features_df, CONFIG["output_path"])
load_to_warehouse(features_df, engine, CONFIG["output_table"])
duration = (datetime.now(timezone.utc) - start_time).total_seconds()
stats = {
"status": "success",
"rows_output": len(features_df),
"duration_seconds": round(duration, 1),
"completed_at": datetime.now(timezone.utc).isoformat()
}
logger.info(f"Pipeline completed in {duration:.1f}s: {stats}")
return stats
except Exception as e:
duration = (datetime.now(timezone.utc) - start_time).total_seconds()
logger.error(f"Pipeline FAILED after {duration:.1f}s: {e}", exc_info=True)
raise
if __name__ == "__main__":
run_pipeline()Incremental vs. Full Refresh Patterns
One of the most important pipeline design decisions is whether to process all data on every run or only new/changed data.
Full Refresh
Process everything every time. Simple but expensive at scale.
def full_refresh_load(source_query: str, dest_table: str,
source_engine, dest_engine) -> int:
"""
Full refresh: truncate destination table and reload from scratch.
Simple, always consistent, but expensive for large tables.
"""
logger.info(f"Full refresh: {dest_table}")
df = pd.read_sql(source_query, source_engine)
df.to_sql(dest_table, dest_engine, if_exists="replace", index=False)
logger.info(f"Full refresh complete: {len(df):,} rows")
return len(df)Incremental Load
Process only new or changed records since the last run.
import json
from pathlib import Path
WATERMARK_FILE = ".pipeline_watermarks.json"
def load_watermarks() -> dict:
"""Load saved high-water marks from previous runs."""
if Path(WATERMARK_FILE).exists():
with open(WATERMARK_FILE) as f:
return json.load(f)
return {}
def save_watermarks(watermarks: dict) -> None:
"""Save high-water marks for next run."""
with open(WATERMARK_FILE, "w") as f:
json.dump(watermarks, f, default=str)
def incremental_load(
table_name: str,
watermark_col: str,
dest_table: str,
source_engine,
dest_engine
) -> int:
"""
Incremental load: extract only records newer than the last watermark.
Parameters
----------
table_name : str
Source table to extract from.
watermark_col : str
Column to use as high-water mark (typically updated_at or created_at).
dest_table : str
Destination table to append to.
source_engine, dest_engine :
SQLAlchemy engines for source and destination.
Returns
-------
int
Number of rows loaded in this run.
"""
watermarks = load_watermarks()
last_watermark = watermarks.get(table_name, "1970-01-01 00:00:00")
logger.info(f"Incremental load: {table_name} (since {last_watermark})")
# Extract only new/changed records
query = f"""
SELECT *
FROM {table_name}
WHERE {watermark_col} > '{last_watermark}'
ORDER BY {watermark_col}
"""
df = pd.read_sql(query, source_engine, parse_dates=[watermark_col])
if len(df) == 0:
logger.info(f"No new records in {table_name}")
return 0
# Load new records (append to destination)
df.to_sql(dest_table, dest_engine, if_exists="append", index=False)
# Update the watermark to the max value we just loaded
new_watermark = df[watermark_col].max()
watermarks[table_name] = str(new_watermark)
save_watermarks(watermarks)
logger.info(f"Loaded {len(df):,} new records, watermark → {new_watermark}")
return len(df)The Idempotency Principle
Well-designed pipelines are idempotent: running the pipeline multiple times produces the same result as running it once. This prevents duplicate data when a pipeline is accidentally re-run or retried after a failure.
def idempotent_load(
df: pd.DataFrame,
dest_table: str,
primary_key: list,
engine,
mode: str = "upsert"
) -> int:
"""
Idempotent load: insert new records, update existing ones.
Running this function multiple times with the same data produces
the same result as running it once.
Uses PostgreSQL's INSERT ... ON CONFLICT DO UPDATE (upsert).
"""
from sqlalchemy import text
if mode == "replace":
# Simplest idempotency: delete all records for the batch period, then insert
df.to_sql(dest_table, engine, if_exists="replace", index=False)
elif mode == "upsert":
# Insert new, update existing — true upsert
staging_table = f"staging_{dest_table}"
# Write to staging
df.to_sql(staging_table, engine, if_exists="replace",
index=False, method="multi")
# Upsert from staging to destination
key_conditions = " AND ".join(
[f"dest.{k} = stage.{k}" for k in primary_key]
)
all_cols = [c for c in df.columns if c not in primary_key]
update_cols = ", ".join([f"{c} = stage.{c}" for c in all_cols])
insert_cols = ", ".join(df.columns)
select_cols = ", ".join([f"stage.{c}" for c in df.columns])
upsert_sql = f"""
INSERT INTO {dest_table} ({insert_cols})
SELECT {select_cols} FROM {staging_table} stage
ON CONFLICT ({', '.join(primary_key)})
DO UPDATE SET {update_cols}
"""
with engine.begin() as conn:
conn.execute(text(upsert_sql))
conn.execute(text(f"DROP TABLE IF EXISTS {staging_table}"))
logger.info(f"Idempotent load complete: {len(df):,} rows → {dest_table}")
return len(df)Pipeline Orchestration: Scheduling and Dependencies
For pipelines beyond a single script, you need an orchestrator — a tool that schedules pipeline runs, manages dependencies between tasks, handles retries, and provides visibility into what ran when.
Apache Airflow
The most widely used open-source orchestrator. Pipelines are defined as DAGs (Directed Acyclic Graphs) in Python:
from airflow import DAG
from airflow.operators.python import PythonOperator
from airflow.operators.sql import SQLCheckOperator
from datetime import datetime, timedelta
default_args = {
"owner": "data-science-team",
"retries": 2,
"retry_delay": timedelta(minutes=5),
"email_on_failure": True,
"email": ["ds-alerts@company.com"]
}
with DAG(
dag_id="customer_features_pipeline",
default_args=default_args,
schedule_interval="0 6 * * *", # Run at 6 AM daily
start_date=datetime(2024, 1, 1),
catchup=False, # Don't backfill missed runs
tags=["ml", "features"]
) as dag:
extract_customers_task = PythonOperator(
task_id="extract_customers",
python_callable=extract_customers,
op_kwargs={"engine": engine}
)
extract_orders_task = PythonOperator(
task_id="extract_orders",
python_callable=extract_order_history,
op_kwargs={"engine": engine, "lookback_days": 365}
)
transform_task = PythonOperator(
task_id="transform_features",
python_callable=join_all_features,
# Pass outputs from prior tasks using XCom
)
validate_task = PythonOperator(
task_id="validate_features",
python_callable=validate_features
)
load_task = PythonOperator(
task_id="load_features",
python_callable=load_to_warehouse,
op_kwargs={"table_name": "ml.customer_features"}
)
# Define dependencies: extract tasks run first, then transform, then validate, then load
[extract_customers_task, extract_orders_task] >> transform_task
transform_task >> validate_task >> load_taskPrefect and Modern Alternatives
Prefect and Dagster are newer orchestrators with more Pythonic APIs and better developer experience:
import prefect
from prefect import flow, task
from prefect.schedules import CronSchedule
@task(retries=2, retry_delay_seconds=300)
def extract_data(source: str) -> pd.DataFrame:
logger.info(f"Extracting from {source}")
# ... extraction logic ...
return df
@task
def transform_data(df: pd.DataFrame) -> pd.DataFrame:
# ... transformation logic ...
return df_transformed
@task(retries=1)
def load_data(df: pd.DataFrame, destination: str) -> None:
# ... load logic ...
pass
@flow(
name="customer-features-pipeline",
schedule=CronSchedule(cron="0 6 * * *")
)
def customer_features_flow():
raw_df = extract_data("warehouse.dim_customer")
clean_df = transform_data(raw_df)
load_data(clean_df, "ml.customer_features")
if __name__ == "__main__":
customer_features_flow()dbt: SQL-Based Transformation at Scale
dbt (data build tool) deserves special attention because it has become the standard for the “T” in ELT. It allows you to write SQL SELECT statements that define data models, with testing, documentation, and lineage tracking built in.
-- models/staging/stg_orders.sql
-- dbt model: reads from raw source, outputs cleaned staging table
WITH source AS (
SELECT * FROM {{ source('postgres', 'orders') }} -- Raw source table
),
cleaned AS (
SELECT
order_id::TEXT AS order_id,
customer_id::TEXT AS customer_id,
order_date::DATE AS order_date,
total_amount::DECIMAL(10,2) AS total_amount,
status::TEXT AS status,
-- Standardize status values
CASE
WHEN LOWER(status) IN ('complete', 'completed', 'done') THEN 'completed'
WHEN LOWER(status) IN ('cancel', 'cancelled', 'void') THEN 'cancelled'
ELSE LOWER(status)
END AS status_clean,
-- Metadata
_fivetran_synced AS source_loaded_at
FROM source
WHERE order_id IS NOT NULL
AND order_date >= '2020-01-01'
)
SELECT * FROM cleaned-- models/marts/fct_sales.sql
-- Fact table combining staged orders, customers, products
WITH orders AS (
SELECT * FROM {{ ref('stg_orders') }} -- References another dbt model
),
customers AS (
SELECT * FROM {{ ref('stg_customers') }}
),
products AS (
SELECT * FROM {{ ref('stg_order_items') }}
)
SELECT
o.order_id,
o.order_date,
c.customer_key,
p.product_key,
p.quantity,
p.unit_price,
p.quantity * p.unit_price AS line_revenue
FROM products p
JOIN orders o ON p.order_id = o.order_id
JOIN customers c ON o.customer_id = c.customer_id# models/staging/stg_orders.yml — tests and documentation
version: 2
models:
- name: stg_orders
description: "Cleaned and typed orders from the Postgres source system"
columns:
- name: order_id
description: "Unique order identifier"
tests:
- unique
- not_null
- name: status_clean
description: "Standardized order status"
tests:
- not_null
- accepted_values:
values: ['completed', 'cancelled', 'pending', 'shipped']
- name: total_amount
tests:
- not_null
- dbt_expectations.expect_column_values_to_be_between:
min_value: 0
max_value: 100000dbt runs these SQL models in the correct order based on {{ ref() }} dependencies, tests them, and generates documentation with lineage diagrams — all from SQL SELECT statements.
Common Pipeline Failure Patterns and How to Avoid Them
| Failure Pattern | Description | Prevention |
|---|---|---|
| Silent data loss | Records dropped with no error or log entry | Row count checks at each step; alert on unexpected drops |
| Schema drift | Source schema changes break the pipeline | Schema validation on ingestion; alerting on new/dropped columns |
| Non-idempotent loads | Re-running a pipeline duplicates data | Use upsert or truncate-insert patterns; test idempotency |
| Missing incremental records | Rows with updated_at = NULL never replicated incrementally | Include full refresh fallback; validate counts against source |
| Time zone bugs | Source data in local time, destination in UTC (or vice versa) | Always normalize to UTC at ingestion; document timezone assumptions |
| Fanout from joins | Undocumented one-to-many relationship inflates row counts | Verify grain at each join; assert unique keys |
| Late-arriving data | Yesterday’s pipeline ran before today’s source data was ready | Use data availability checks before triggering pipeline; add buffer |
| Cascading failures | One pipeline failing blocks all downstream pipelines | Circuit breakers; independent scheduling for critical vs. nice-to-have |
| Unmonitored drift | Pipeline runs successfully but produces wrong results | Statistical tests on output distributions; alerting on metric anomalies |
Summary
ETL and ELT are not competing technologies — they are different architectures suited to different constraints. ETL, which transforms data before loading, made sense when data warehouse compute was expensive and limited. ELT, which loads raw data first and transforms inside the destination, became dominant with cloud data warehouses that provide cheap, elastic compute. Most modern data teams use ELT with dedicated tooling: Fivetran or Airbyte for extraction and loading, dbt for SQL-based transformation, and Airflow, Prefect, or Dagster for orchestration.
For data scientists, the most important things to understand are: where in the pipeline your data was transformed (which determines what errors might be present), whether the pipeline is full-refresh or incremental (which determines data freshness guarantees), and how to build simple reliable pipelines when you need to create your own data processing flows. The fundamental principles — validate early, make pipelines idempotent, make failures loud not silent, document the grain at each stage — apply whether you’re writing a 20-line pandas script or a 20-task Airflow DAG.
Key Takeaways
- ETL (Extract-Transform-Load) transforms data in an intermediate layer before loading to the destination; ELT (Extract-Load-Transform) loads raw data first and transforms inside the destination using its compute — modern teams predominantly use ELT because cloud warehouse compute is cheap and elastic
- The primary advantage of ELT is that raw data is always preserved — when business logic changes, you re-run SQL transformations against already-loaded raw data rather than re-extracting from source systems
- Well-structured pipelines follow the Extract → Transform → Validate → Load pattern, with explicit validation checks (row counts, null rates, value ranges, grain assertions) before writing to the destination
- Incremental loads (process only new/changed records using a watermark column) are far more efficient than full refreshes for large tables; the watermark approach tracks the highest
updated_atvalue from the last successful run - Idempotency — running a pipeline multiple times produces the same result as running it once — prevents duplicate data on retries; implement using upsert (
INSERT ... ON CONFLICT) or truncate-insert patterns - dbt (data build tool) is the standard tool for the transformation step in ELT: SQL SELECT statements define data models,
{{ ref() }}dependencies automatically determine execution order, and YAML schema tests validate data quality with every run - Common pipeline orchestrators — Airflow, Prefect, Dagster — provide scheduling, dependency management, retry logic, and observability; pipelines should be code (version-controlled, testable) rather than GUI-configured
- Silent failures are the most dangerous pipeline problem — always validate row counts between stages, alert on unexpected drops, test that pipelines are idempotent, and use statistical distribution checks to catch subtle data quality regressions