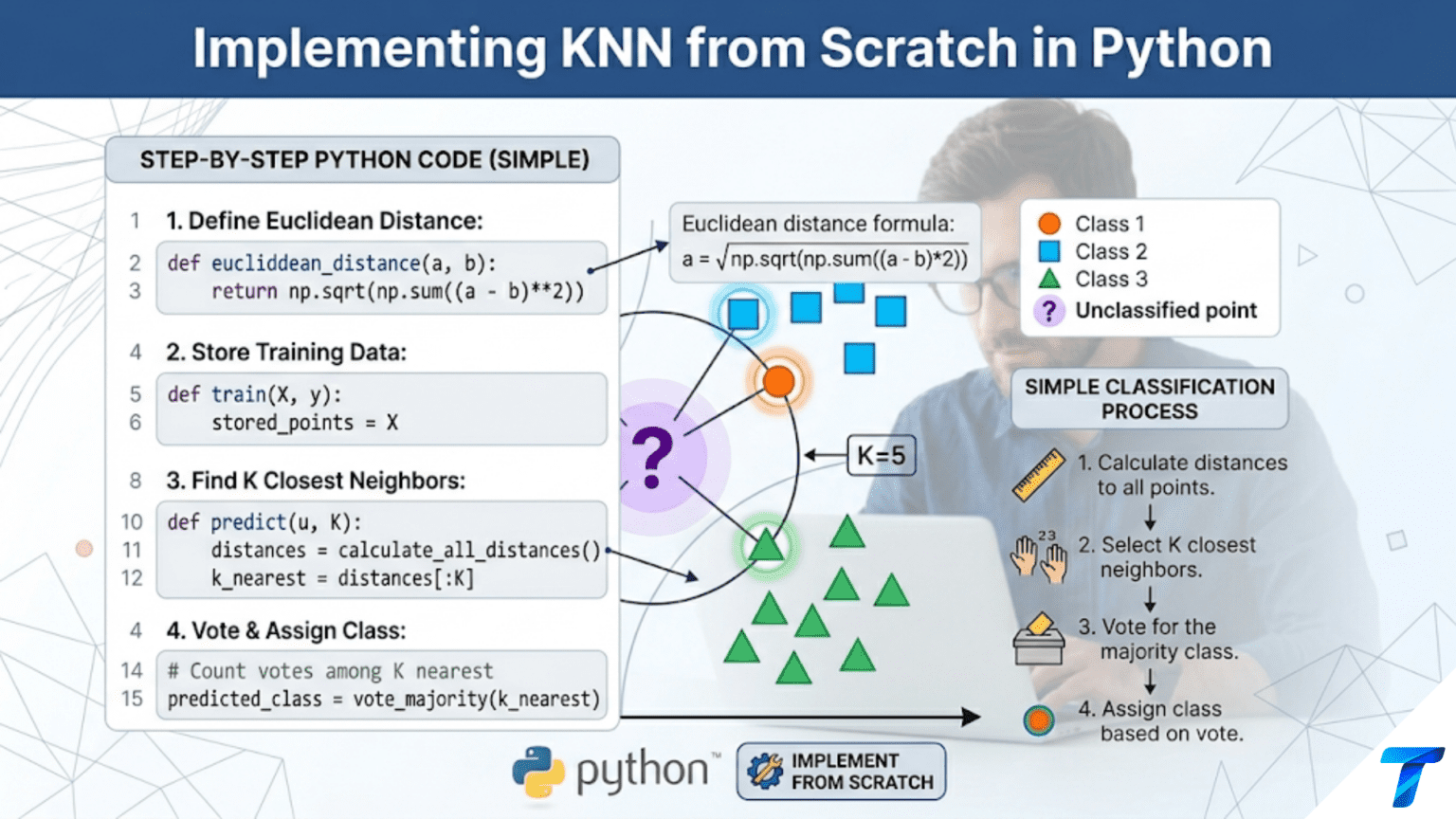
Implementing KNN from scratch requires three components: a distance function to measure similarity between data points, a neighbor-finding routine that identifies the K closest training samples to a query point, and a voting mechanism that aggregates neighbor labels into a prediction. The minimal implementation fits in under 40 lines of Python, but a production-quality version adds vectorized computation, multiple distance metrics, weighted voting, and efficient data structures — all of which this article builds step by step.
Introduction
The best way to understand any algorithm is to build it yourself. Reading pseudocode and calling library functions teaches you what an algorithm does, but implementing it from scratch teaches you why it works, where it can break, and what every design decision actually means.
KNN is an ideal algorithm to implement from scratch for this reason. Its logic is simple enough to fit on a single page, yet there is meaningful depth in every component: distance computation has vectorization opportunities that produce 100× speedups, neighbor finding has data structure choices that change asymptotic complexity, and voting has weighting schemes that improve accuracy. Building each layer explicitly — from a naive loop-based version to an optimized, full-featured classifier — reveals the engineering decisions that production ML libraries make and why.
This article builds a complete KNN implementation in stages. We start with the simplest possible version that works correctly, then systematically improve it: vectorizing distance computation, adding multiple metrics, implementing weighted voting, building a KD-tree for efficient neighbor search, and adding cross-validation and visualization utilities. At each stage, we benchmark against scikit-learn to verify correctness.
Stage 1: The Minimal Correct Implementation
Before optimizing anything, let’s build the simplest possible version that works correctly on real data. This establishes a correct baseline to validate all future improvements against.
import numpy as np
from collections import Counter
class KNNv1:
"""
Stage 1: Minimal KNN — correct but not optimized.
Every operation is explicit and readable.
Distance: Euclidean using a Python loop.
Voting: simple majority using Counter.
"""
def __init__(self, k=5):
self.k = k
def fit(self, X, y):
"""Store training data — KNN has no actual training step."""
self.X_train = np.array(X, dtype=float)
self.y_train = np.array(y)
return self
def _euclidean_distance(self, a, b):
"""Euclidean distance between two vectors using a Python loop."""
return sum((float(ai) - float(bi)) ** 2 for ai, bi in zip(a, b)) ** 0.5
def _predict_one(self, x):
"""Predict class for a single sample using Python loops."""
# Step 1: Compute distance from x to every training point
distances = []
for i, x_train in enumerate(self.X_train):
d = self._euclidean_distance(x, x_train)
distances.append((d, self.y_train[i]))
# Step 2: Sort by distance and take K nearest
distances.sort(key=lambda pair: pair[0])
k_nearest_labels = [label for _, label in distances[:self.k]]
# Step 3: Majority vote
vote_counts = Counter(k_nearest_labels)
return vote_counts.most_common(1)[0][0]
def predict(self, X):
"""Predict class labels for all samples in X."""
return np.array([self._predict_one(x) for x in X])
def score(self, X, y):
"""Compute accuracy."""
predictions = self.predict(X)
return np.mean(predictions == np.array(y))
# Quick test on Iris dataset
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
iris = load_iris()
X, y = iris.data, iris.target
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.25, random_state=42, stratify=y
)
scaler = StandardScaler()
X_train_s = scaler.fit_transform(X_train)
X_test_s = scaler.transform(X_test)
knn_v1 = KNNv1(k=5)
knn_v1.fit(X_train_s, y_train)
acc_v1 = knn_v1.score(X_test_s, y_test)
print(f"Stage 1 (Naive) accuracy: {acc_v1:.4f}")
print(f"Dataset: {X.shape[0]} samples, {X.shape[1]} features, {len(np.unique(y))} classes")This version is correct but slow. The inner loop over training points, combined with the Python-level zip and arithmetic, produces O(n × d) scalar operations entirely in Python — the slowest possible mode of numerical computation. For 1,000 training points and 10 features, that is 10,000 Python operations per prediction. For 100,000 training points and 100 features, it is 10 million per prediction. We need NumPy vectorization.
Stage 2: Vectorized Distance Computation
NumPy’s core strength is performing array operations in compiled C code, orders of magnitude faster than Python loops. The key insight for vectorizing distance computation: instead of computing the distance from a single query point to each training point one at a time, compute all distances simultaneously using array broadcasting.
Vectorizing Single-Query Distance
import numpy as np
# Naive approach: Python loop
def euclidean_distances_loop(X_train, query):
"""Python loop — slow."""
distances = []
for x in X_train:
dist = np.sqrt(np.sum((x - query) ** 2))
distances.append(dist)
return np.array(distances)
# Vectorized approach: NumPy broadcasting
def euclidean_distances_vectorized(X_train, query):
"""
NumPy broadcasting — fast.
X_train: shape (n, d)
query: shape (d,)
X_train - query: broadcasts query across all n rows → shape (n, d)
** 2: squares element-wise → shape (n, d)
sum(1): sum along feature axis → shape (n,)
sqrt(): element-wise sqrt → shape (n,)
"""
diff = X_train - query # Shape: (n, d)
diff_sq = diff ** 2 # Shape: (n, d)
sum_sq = diff_sq.sum(axis=1) # Shape: (n,)
return np.sqrt(sum_sq) # Shape: (n,)
# Even more concise (same computation):
def euclidean_distances_concise(X_train, query):
return np.sqrt(((X_train - query) ** 2).sum(axis=1))
# Benchmark: loop vs vectorized
np.random.seed(42)
n, d = 5000, 20
X_bench = np.random.randn(n, d)
q_bench = np.random.randn(d)
import time
start = time.time()
for _ in range(100):
euclidean_distances_loop(X_bench, q_bench)
loop_time = (time.time() - start) / 100
start = time.time()
for _ in range(100):
euclidean_distances_vectorized(X_bench, q_bench)
vec_time = (time.time() - start) / 100
print(f"=== Distance Computation Benchmark ===\n")
print(f" Dataset: {n:,} training points, {d} features")
print(f" Loop time per query: {loop_time*1000:.2f} ms")
print(f" Vectorized time per query: {vec_time*1000:.2f} ms")
print(f" Speedup: {loop_time/vec_time:.0f}×")Vectorizing Batch Distance Computation
When predicting for multiple query points simultaneously, we can compute all pairwise distances in one matrix operation.
import numpy as np
def pairwise_euclidean_distances(X_train, X_query):
"""
Compute all pairwise Euclidean distances between X_query and X_train.
Args:
X_train: shape (n_train, d)
X_query: shape (n_query, d)
Returns:
Distance matrix of shape (n_query, n_train)
dist[i, j] = distance from X_query[i] to X_train[j]
Uses the identity:
||a - b||² = ||a||² + ||b||² - 2 * a·b
This avoids an explicit subtraction loop and is very fast
for large matrices.
"""
# ||a||² for each query point: shape (n_query, 1)
sq_norms_query = (X_query ** 2).sum(axis=1, keepdims=True)
# ||b||² for each training point: shape (1, n_train)
sq_norms_train = (X_train ** 2).sum(axis=1, keepdims=True).T
# -2 * a·b: shape (n_query, n_train)
dot_products = X_query @ X_train.T
# Combine: dist² = ||a||² + ||b||² - 2*a·b
sq_distances = sq_norms_query + sq_norms_train - 2 * dot_products
# Numerical safety: clip small negatives to 0 before sqrt
sq_distances = np.clip(sq_distances, 0, None)
return np.sqrt(sq_distances)
# Test correctness
np.random.seed(42)
X_tr_test = np.random.randn(100, 5)
X_qu_test = np.random.randn(20, 5)
# Reference: scipy's cdist
from scipy.spatial.distance import cdist
D_scipy = cdist(X_qu_test, X_tr_test, metric='euclidean')
D_ours = pairwise_euclidean_distances(X_tr_test, X_qu_test)
max_error = np.max(np.abs(D_scipy - D_ours))
print(f"\nPairwise distance correctness check:")
print(f" Max absolute error vs scipy: {max_error:.2e} (should be ~1e-14)")
# Benchmark batch vs single-query approach
n_train, n_query, d = 5000, 200, 20
X_tr_bm = np.random.randn(n_train, d)
X_qu_bm = np.random.randn(n_query, d)
start = time.time()
for q in X_qu_bm:
euclidean_distances_vectorized(X_tr_bm, q)
single_time = time.time() - start
start = time.time()
pairwise_euclidean_distances(X_tr_bm, X_qu_bm)
batch_time = time.time() - start
print(f"\nBatch vs single-query distance computation:")
print(f" Single-query loop ({n_query} calls): {single_time*1000:.1f} ms")
print(f" Batch matrix multiply: {batch_time*1000:.1f} ms")
print(f" Speedup: {single_time/batch_time:.1f}×")The matrix multiplication approach exploits BLAS (Basic Linear Algebra Subprograms) routines that are highly optimized for modern CPUs with SIMD instructions. For large matrices, this is dramatically faster than computing individual distance vectors.
Stage 3: Multiple Distance Metrics
A well-designed KNN implementation should support multiple distance metrics without duplicating code. We use a clean dispatch pattern.
import numpy as np
class DistanceMetrics:
"""
Vectorized distance metric implementations.
All methods accept X_train (n, d) and X_query (m, d)
and return distance matrix (m, n).
"""
@staticmethod
def euclidean(X_train, X_query):
"""L2 distance — straight-line distance."""
sq_norms_q = (X_query ** 2).sum(axis=1, keepdims=True)
sq_norms_t = (X_train ** 2).sum(axis=1, keepdims=True).T
sq_dist = sq_norms_q + sq_norms_t - 2 * (X_query @ X_train.T)
return np.sqrt(np.clip(sq_dist, 0, None))
@staticmethod
def manhattan(X_train, X_query):
"""L1 distance — sum of absolute differences."""
# This requires explicit broadcasting — can't use matrix multiply trick
# Shape: (m, 1, d) - (1, n, d) → (m, n, d) then sum
diff = X_query[:, np.newaxis, :] - X_train[np.newaxis, :, :]
return np.abs(diff).sum(axis=2)
@staticmethod
def chebyshev(X_train, X_query):
"""L∞ distance — maximum absolute difference along any dimension."""
diff = X_query[:, np.newaxis, :] - X_train[np.newaxis, :, :]
return np.abs(diff).max(axis=2)
@staticmethod
def cosine(X_train, X_query):
"""Cosine distance = 1 - cosine similarity."""
# Normalize both matrices
norms_q = np.linalg.norm(X_query, axis=1, keepdims=True)
norms_t = np.linalg.norm(X_train, axis=1, keepdims=True)
# Guard against zero vectors
norms_q = np.where(norms_q == 0, 1e-10, norms_q)
norms_t = np.where(norms_t == 0, 1e-10, norms_t)
X_query_norm = X_query / norms_q
X_train_norm = X_train / norms_t
# Cosine similarity matrix: (m, n)
similarity = X_query_norm @ X_train_norm.T
# Clip to [-1, 1] for numerical safety, then convert to distance
return 1.0 - np.clip(similarity, -1.0, 1.0)
@staticmethod
def minkowski(X_train, X_query, p=3):
"""General Minkowski distance with parameter p."""
diff = X_query[:, np.newaxis, :] - X_train[np.newaxis, :, :]
return (np.abs(diff) ** p).sum(axis=2) ** (1.0 / p)
@classmethod
def get(cls, name, **kwargs):
"""Factory method: return a distance function by name."""
if name == 'euclidean':
return cls.euclidean
elif name == 'manhattan':
return cls.manhattan
elif name == 'chebyshev':
return cls.chebyshev
elif name == 'cosine':
return cls.cosine
elif name == 'minkowski':
p = kwargs.get('p', 3)
return lambda Xt, Xq: cls.minkowski(Xt, Xq, p=p)
else:
raise ValueError(f"Unknown metric: '{name}'. "
f"Choose from: euclidean, manhattan, chebyshev, cosine, minkowski")
# Test all metrics produce sensible results
np.random.seed(42)
X_mt = np.random.randn(50, 4)
X_mq = np.random.randn(10, 4)
print("=== Distance Metrics: Shape and Value Checks ===\n")
print(f" X_train: {X_mt.shape}, X_query: {X_mq.shape}")
print(f" Expected output shape: ({X_mq.shape[0]}, {X_mt.shape[0]})\n")
for metric_name in ['euclidean', 'manhattan', 'chebyshev', 'cosine', 'minkowski']:
fn = DistanceMetrics.get(metric_name)
D = fn(X_mt, X_mq)
print(f" {metric_name:<12}: shape={D.shape}, "
f"min={D.min():.3f}, mean={D.mean():.3f}, max={D.max():.3f}, "
f"all_nonneg={np.all(D >= -1e-10)}")Stage 4: The Full KNN Classifier
Now we assemble all components — vectorized distance computation, multiple metrics, weighted voting, and probability estimates — into a complete, production-quality KNN classifier.
import numpy as np
from collections import Counter
class KNNClassifier:
"""
Full-featured KNN Classifier: vectorized, multi-metric, with weighted voting.
Features:
- Vectorized batch distance computation (fast)
- Multiple distance metrics: euclidean, manhattan, chebyshev, cosine, minkowski
- Uniform and distance-weighted voting
- predict_proba() for probability estimates
- score() for accuracy
- Scikit-learn compatible interface (fit/predict/score)
"""
SUPPORTED_METRICS = {'euclidean', 'manhattan', 'chebyshev', 'cosine', 'minkowski'}
SUPPORTED_WEIGHTS = {'uniform', 'distance'}
def __init__(self, k=5, metric='euclidean', weights='uniform', p=3):
"""
Args:
k: Number of neighbors (positive integer)
metric: Distance metric name
weights: 'uniform' or 'distance'
p: Minkowski p parameter (only used when metric='minkowski')
"""
if not isinstance(k, int) or k < 1:
raise ValueError(f"k must be a positive integer, got {k}")
if metric not in self.SUPPORTED_METRICS:
raise ValueError(f"metric must be one of {self.SUPPORTED_METRICS}")
if weights not in self.SUPPORTED_WEIGHTS:
raise ValueError(f"weights must be one of {self.SUPPORTED_WEIGHTS}")
self.k = k
self.metric = metric
self.weights = weights
self.p = p
self._dist_fn = None
self.X_train = None
self.y_train = None
self.classes_ = None
self._is_fitted = False
def fit(self, X, y):
"""
Store training data and set up distance function.
Args:
X: shape (n_samples, n_features)
y: shape (n_samples,)
Returns:
self (for chaining)
"""
self.X_train = np.array(X, dtype=float)
self.y_train = np.array(y)
self.classes_ = np.unique(self.y_train)
self.n_classes_ = len(self.classes_)
self._class_to_idx = {c: i for i, c in enumerate(self.classes_)}
self._dist_fn = DistanceMetrics.get(self.metric, p=self.p)
self._is_fitted = True
return self
def _check_fitted(self):
if not self._is_fitted:
raise RuntimeError("Call fit() before predict().")
def _get_neighbor_indices_and_distances(self, X_query):
"""
Find K nearest neighbors for all query points in batch.
Returns:
neighbor_indices: shape (n_query, k)
neighbor_distances: shape (n_query, k)
"""
# Compute full distance matrix: shape (n_query, n_train)
D = self._dist_fn(self.X_train, X_query)
# Partial sort: only find the K smallest (faster than full sort)
# np.argpartition gives indices of K smallest in any order
k_indices_unsorted = np.argpartition(D, self.k, axis=1)[:, :self.k]
# Gather K distances for each query
k_dists_unsorted = D[np.arange(len(X_query))[:, None], k_indices_unsorted]
# Sort within the K neighbors by distance
sort_order = np.argsort(k_dists_unsorted, axis=1)
k_indices = k_indices_unsorted[np.arange(len(X_query))[:, None], sort_order]
k_dists = k_dists_unsorted[np.arange(len(X_query))[:, None], sort_order]
return k_indices, k_dists
def _compute_weights(self, distances):
"""
Compute voting weights for each neighbor.
Args:
distances: shape (n_query, k)
Returns:
weights: shape (n_query, k), normalized to sum to 1 per row
"""
if self.weights == 'uniform':
return np.ones_like(distances) / self.k
else: # 'distance'
# 1/distance weighting; handle exact zero distances
# If any distance is exactly 0, that neighbor gets weight 1,
# all others get weight 0
zero_mask = (distances == 0)
any_zero = zero_mask.any(axis=1)
inv_dist = np.where(distances == 0, 0.0, 1.0 / distances)
# For rows with any zero distance: zero-distance neighbors get
# weight 1/count_zeros, others get 0
inv_dist[any_zero] = 0.0
for i in np.where(any_zero)[0]:
n_zeros = zero_mask[i].sum()
inv_dist[i, zero_mask[i]] = 1.0 / n_zeros
# Normalize so weights sum to 1
row_sums = inv_dist.sum(axis=1, keepdims=True)
row_sums = np.where(row_sums == 0, 1.0, row_sums) # safety
return inv_dist / row_sums
def predict_proba(self, X):
"""
Predict class probability estimates.
For each query, returns the weighted fraction of K neighbors
belonging to each class.
Args:
X: shape (n_query, n_features)
Returns:
proba: shape (n_query, n_classes)
"""
self._check_fitted()
X = np.array(X, dtype=float)
n_query = len(X)
k_indices, k_dists = self._get_neighbor_indices_and_distances(X)
k_labels = self.y_train[k_indices] # shape: (n_query, k)
weights = self._compute_weights(k_dists) # shape: (n_query, k)
# Initialize probability matrix
proba = np.zeros((n_query, self.n_classes_))
# Accumulate weighted votes per class
for class_idx, cls in enumerate(self.classes_):
class_mask = (k_labels == cls) # shape: (n_query, k)
proba[:, class_idx] = (weights * class_mask).sum(axis=1)
return proba
def predict(self, X):
"""
Predict class labels.
Args:
X: shape (n_query, n_features)
Returns:
labels: shape (n_query,)
"""
proba = self.predict_proba(X)
return self.classes_[np.argmax(proba, axis=1)]
def score(self, X, y):
"""Accuracy score."""
return np.mean(self.predict(X) == np.array(y))
def kneighbors(self, X, n_neighbors=None):
"""
Find K nearest neighbors.
Matches scikit-learn's KNeighborsClassifier.kneighbors() interface.
Returns:
distances: shape (n_query, k)
indices: shape (n_query, k)
"""
self._check_fitted()
k = n_neighbors or self.k
X = np.array(X, dtype=float)
D = self._dist_fn(self.X_train, X)
indices = np.argpartition(D, k, axis=1)[:, :k]
distances = D[np.arange(len(X))[:, None], indices]
sort_order = np.argsort(distances, axis=1)
return (distances[np.arange(len(X))[:, None], sort_order],
indices[np.arange(len(X))[:, None], sort_order])
def __repr__(self):
return (f"KNNClassifier(k={self.k}, metric='{self.metric}', "
f"weights='{self.weights}')")Stage 5: Comprehensive Validation Against Scikit-learn
Before trusting any custom implementation, we must systematically verify it produces identical results to the reference implementation across many configurations.
import numpy as np
from sklearn.neighbors import KNeighborsClassifier as SklearnKNN
from sklearn.datasets import load_iris, load_wine, load_breast_cancer
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
def validate_against_sklearn(X, y, dataset_name,
k_values=[1, 3, 5, 10],
metrics=['euclidean', 'manhattan'],
weight_types=['uniform', 'distance'],
tol=1e-6):
"""
Compare our KNNClassifier against scikit-learn on the same data.
Tests predictions, probabilities, and neighbor indices for exact match.
"""
X_tr, X_te, y_tr, y_te = train_test_split(
X, y, test_size=0.25, random_state=42, stratify=y
)
scaler = StandardScaler()
X_tr_s = scaler.fit_transform(X_tr)
X_te_s = scaler.transform(X_te)
print(f"\n=== Validation: {dataset_name} ===")
print(f" Train: {len(y_tr)} | Test: {len(y_te)} | Features: {X.shape[1]}\n")
print(f" {'Config':<45} | {'Our Acc':>8} | {'SK Acc':>7} | {'Match':>8} | {'Prob ΔMax'}")
print(" " + "-" * 85)
all_passed = True
for k in k_values:
for metric in metrics:
for w in weight_types:
# Our implementation
our = KNNClassifier(k=k, metric=metric, weights=w)
our.fit(X_tr_s, y_tr)
our_pred = our.predict(X_te_s)
our_proba = our.predict_proba(X_te_s)
our_acc = our.score(X_te_s, y_te)
# Scikit-learn reference
# Note: sklearn uses 'minkowski' with p=1 for manhattan
sk_metric = 'minkowski' if metric == 'manhattan' else metric
sk_p = 1 if metric == 'manhattan' else 2
sk = SklearnKNN(n_neighbors=k, metric=sk_metric, p=sk_p, weights=w)
sk.fit(X_tr_s, y_tr)
sk_pred = sk.predict(X_te_s)
sk_proba = sk.predict_proba(X_te_s)
sk_acc = sk.score(X_te_s, y_te)
pred_match = np.all(our_pred == sk_pred)
proba_delta = np.max(np.abs(our_proba - sk_proba))
match_sym = "✓" if pred_match and proba_delta < tol else "✗"
if not (pred_match and proba_delta < tol):
all_passed = False
config = f"K={k}, metric={metric}, weights={w}"
print(f" {config:<45} | {our_acc:>8.4f} | {sk_acc:>7.4f} | "
f"{match_sym:>8} | {proba_delta:.2e}")
print(f"\n Overall: {'✓ ALL PASS' if all_passed else '✗ FAILURES DETECTED'}")
return all_passed
# Run validation on multiple datasets
datasets = [
("Iris", load_iris()),
("Wine", load_wine()),
("Breast Cancer", load_breast_cancer()),
]
all_pass = True
for name, data in datasets:
passed = validate_against_sklearn(data.data, data.target, name)
all_pass = all_pass and passed
print(f"\n{'='*50}")
print(f" FINAL RESULT: {'ALL TESTS PASSED ✓' if all_pass else 'SOME TESTS FAILED ✗'}")
print(f"{'='*50}")Stage 6: KD-Tree for Efficient Neighbor Search
The vectorized implementation is fast, but it still computes distances to every training point for each query. For very large training sets, this O(n) per query cost becomes prohibitive. The KD-tree data structure reduces average-case query time to O(log n) by organizing training points in a hierarchical binary tree.
How KD-Trees Work
A KD-tree (k-dimensional tree) partitions the feature space recursively:
- Choose the dimension with the largest spread (variance)
- Split the data at the median value along that dimension
- Create a left subtree (points below median) and right subtree (points above)
- Recurse until each leaf contains at most
leaf_sizepoints
At query time, traverse the tree: go left or right based on which side the query falls. When you reach a leaf, compute exact distances to its points. Then backtrack only through branches that could contain closer neighbors — skipping vast regions of the training set.
import numpy as np
class KDNode:
"""A node in the KD-tree."""
__slots__ = ['split_dim', 'split_val', 'left', 'right',
'indices', 'bbox_min', 'bbox_max']
def __init__(self):
self.split_dim = None
self.split_val = None
self.left = None
self.right = None
self.indices = None # Non-None only for leaf nodes
self.bbox_min = None # Bounding box min per dimension
self.bbox_max = None # Bounding box max per dimension
class KDTree:
"""
KD-Tree for accelerated K-nearest neighbor search.
Significantly faster than brute force for low-dimensional data
(d ≤ ~20) and large training sets (n ≥ ~1000).
Args:
X: Training points, shape (n, d)
leaf_size: Max points per leaf node (controls tree depth)
"""
def __init__(self, X, leaf_size=30):
self.X = np.array(X, dtype=float)
self.n, self.d = self.X.shape
self.leaf_size = leaf_size
self.root = self._build(np.arange(self.n))
def _build(self, indices):
"""Recursively build the KD-tree."""
node = KDNode()
# Bounding box for this node's points
node.bbox_min = self.X[indices].min(axis=0)
node.bbox_max = self.X[indices].max(axis=0)
# Leaf node: small enough to search directly
if len(indices) <= self.leaf_size:
node.indices = indices
return node
# Choose split dimension: the one with max spread
spreads = node.bbox_max - node.bbox_min
node.split_dim = int(np.argmax(spreads))
# Split at median for balanced tree
values_on_dim = self.X[indices, node.split_dim]
median_val = np.median(values_on_dim)
node.split_val = median_val
left_mask = values_on_dim <= median_val
right_mask = ~left_mask
# Handle degenerate case where median splits unevenly
if left_mask.sum() == 0 or right_mask.sum() == 0:
node.indices = indices
return node
node.left = self._build(indices[left_mask])
node.right = self._build(indices[right_mask])
return node
def _min_dist_to_bbox(self, query, bbox_min, bbox_max):
"""
Minimum possible distance from query to any point in a bounding box.
This is the key pruning heuristic: if the minimum possible distance
to a node's bounding box is ≥ current best distance, skip the node.
"""
# For each dimension, distance to box is 0 if inside, else distance to nearest edge
closest = np.clip(query, bbox_min, bbox_max)
return np.sqrt(np.sum((query - closest) ** 2))
def _search(self, node, query, k, heap):
"""
Recursive KD-tree search.
Uses a max-heap to track the K closest points found so far.
Prunes branches whose bounding box is farther than the K-th best.
"""
import heapq
# Pruning: skip node if its bbox is farther than current K-th best
if len(heap) >= k:
current_worst = -heap[0][0] # Max-heap stores negated distances
min_possible = self._min_dist_to_bbox(query, node.bbox_min, node.bbox_max)
if min_possible >= current_worst:
return
# Leaf node: check all points
if node.indices is not None:
for idx in node.indices:
dist = np.sqrt(np.sum((self.X[idx] - query) ** 2))
if len(heap) < k:
heapq.heappush(heap, (-dist, idx))
elif dist < -heap[0][0]:
heapq.heapreplace(heap, (-dist, idx))
return
# Internal node: go to the side the query falls on first
query_val = query[node.split_dim]
if query_val <= node.split_val:
first, second = node.left, node.right
else:
first, second = node.right, node.left
self._search(first, query, k, heap)
self._search(second, query, k, heap)
def query(self, X_query, k=5):
"""
Find K nearest neighbors for all query points.
Args:
X_query: shape (n_query, d)
k: Number of neighbors
Returns:
distances: shape (n_query, k), sorted ascending
indices: shape (n_query, k), corresponding training indices
"""
import heapq
X_query = np.array(X_query, dtype=float)
n_query = len(X_query)
all_distances = np.zeros((n_query, k))
all_indices = np.zeros((n_query, k), dtype=int)
for i, query in enumerate(X_query):
heap = [] # Max-heap (negated distances) of (−dist, idx)
self._search(self.root, query, k, heap)
# Extract results sorted by distance (ascending)
results = sorted(heap, key=lambda x: x[0]) # Sort by negated dist (most neg = farthest)
results = sorted([(−d, idx) for d, idx in heap]) # Sort ascending
for j, (neg_dist, idx) in enumerate(results):
all_distances[i, j] = -neg_dist
all_indices[i, j] = idx
return all_distances, all_indices
# Fix the sorting in query method
class KDTree:
"""KD-Tree for accelerated K-nearest neighbor search (corrected)."""
def __init__(self, X, leaf_size=30):
self.X = np.array(X, dtype=float)
self.n, self.d = self.X.shape
self.leaf_size = leaf_size
self.root = self._build(np.arange(self.n))
def _build(self, indices):
node = KDNode()
node.bbox_min = self.X[indices].min(axis=0)
node.bbox_max = self.X[indices].max(axis=0)
if len(indices) <= self.leaf_size:
node.indices = indices
return node
spreads = node.bbox_max - node.bbox_min
node.split_dim = int(np.argmax(spreads))
values_on_dim = self.X[indices, node.split_dim]
median_val = np.median(values_on_dim)
node.split_val = median_val
left_mask = values_on_dim <= median_val
right_mask = ~left_mask
if left_mask.sum() == 0 or right_mask.sum() == 0:
node.indices = indices
return node
node.left = self._build(indices[left_mask])
node.right = self._build(indices[right_mask])
return node
def _min_dist_to_bbox(self, query, bbox_min, bbox_max):
closest = np.clip(query, bbox_min, bbox_max)
return np.sqrt(np.sum((query - closest) ** 2))
def _search(self, node, query, k, heap):
import heapq
if len(heap) >= k:
current_worst = -heap[0][0]
min_possible = self._min_dist_to_bbox(query, node.bbox_min, node.bbox_max)
if min_possible >= current_worst:
return
if node.indices is not None:
for idx in node.indices:
dist = float(np.sqrt(np.sum((self.X[idx] - query) ** 2)))
if len(heap) < k:
heapq.heappush(heap, (-dist, int(idx)))
elif dist < -heap[0][0]:
heapq.heapreplace(heap, (-dist, int(idx)))
return
query_val = query[node.split_dim]
if query_val <= node.split_val:
first, second = node.left, node.right
else:
first, second = node.right, node.left
self._search(first, query, k, heap)
self._search(second, query, k, heap)
def query(self, X_query, k=5):
import heapq
X_query = np.array(X_query, dtype=float)
n_query = len(X_query)
all_distances = np.zeros((n_query, k))
all_indices = np.zeros((n_query, k), dtype=int)
for i, query in enumerate(X_query):
heap = []
self._search(self.root, query, k, heap)
# Sort ascending by distance
results = sorted(heap, key=lambda x: x[0], reverse=True) # heap stores -dist
for j, (neg_dist, idx) in enumerate(results[:k]):
all_distances[i, j] = -neg_dist
all_indices[i, j] = idx
return all_distances, all_indices
# Benchmark: brute force vs KD-tree
np.random.seed(42)
n_train, n_query, d = 5000, 200, 8
X_bm_tr = np.random.randn(n_train, d)
X_bm_qu = np.random.randn(n_query, d)
print("=== KD-Tree vs Brute Force: Correctness and Speed ===\n")
print(f" Training: {n_train:,} samples, {d} features")
print(f" Queries: {n_query} samples\n")
# Build KD-tree
t0 = time.time()
kdtree = KDTree(X_bm_tr, leaf_size=30)
build_time = time.time() - t0
print(f" KD-tree build time: {build_time*1000:.1f} ms")
# KD-tree query time
t0 = time.time()
kd_dists, kd_idx = kdtree.query(X_bm_qu, k=5)
kd_time = time.time() - t0
# Brute force using our vectorized implementation
t0 = time.time()
D_brute = DistanceMetrics.euclidean(X_bm_tr, X_bm_qu)
bf_idx = np.argpartition(D_brute, 5, axis=1)[:, :5]
bf_time = time.time() - t0
print(f" KD-tree query time ({n_query} queries): {kd_time*1000:.1f} ms")
print(f" Brute force time ({n_query} queries): {bf_time*1000:.1f} ms")
print(f" Speedup: {bf_time/kd_time:.1f}×")
# Verify correctness: KD-tree neighbors should match brute force
# Sort brute force results for comparison
bf_idx_sorted = np.sort(bf_idx, axis=1)
kd_idx_sorted = np.sort(kd_idx, axis=1)
# Note: For ties in distance, order may differ; check distances instead
print(f"\n Correctness check on first 10 queries:")
for i in range(min(10, n_query)):
kd_d_set = set(np.round(kd_dists[i], 6))
bf_d = np.sort(D_brute[i][bf_idx[i]])
bf_d_set = set(np.round(np.sort(D_brute[i])[:5], 6))
match = "✓" if kd_d_set == bf_d_set else "~"
print(f" Query {i:2d}: {match}")Stage 7: Performance Benchmark
With a complete implementation, let’s run a systematic benchmark comparing different versions across dataset sizes.
import numpy as np
import time
import matplotlib.pyplot as plt
from sklearn.neighbors import KNeighborsClassifier as SklearnKNN
from sklearn.preprocessing import StandardScaler
def benchmark_knn_implementations(n_train_values, n_test=200, n_features=10, k=5):
"""
Benchmark KNN prediction time across different training set sizes
for our implementation vs scikit-learn.
"""
np.random.seed(42)
our_times = []
sk_times = []
print(f"=== KNN Performance Benchmark ===\n")
print(f" Test queries: {n_test} | Features: {n_features} | K: {k}\n")
print(f" {'N Train':>10} | {'Our (ms)':>10} | {'SK (ms)':>9} | {'SK Speedup':>11} | {'Our Acc':>8}")
print(" " + "-" * 58)
for n_train in n_train_values:
X_tr = np.random.randn(n_train, n_features)
X_te = np.random.randn(n_test, n_features)
y_tr = np.random.randint(0, 3, n_train)
y_te = np.random.randint(0, 3, n_test)
# Normalize
sc = StandardScaler()
X_tr_s = sc.fit_transform(X_tr)
X_te_s = sc.transform(X_te)
# Our implementation
our = KNNClassifier(k=k, metric='euclidean')
our.fit(X_tr_s, y_tr)
t0 = time.time()
our.predict(X_te_s)
our_t = (time.time() - t0) * 1000
our_acc = our.score(X_te_s, y_te)
# Scikit-learn
sk = SklearnKNN(n_neighbors=k, algorithm='auto', n_jobs=1)
sk.fit(X_tr_s, y_tr)
t0 = time.time()
sk.predict(X_te_s)
sk_t = (time.time() - t0) * 1000
our_times.append(our_t)
sk_times.append(sk_t)
speedup = our_t / sk_t
print(f" {n_train:>10,} | {our_t:>10.1f} | {sk_t:>9.1f} | {speedup:>11.1f}× | {our_acc:>8.4f}")
# Plot
fig, ax = plt.subplots(figsize=(10, 5))
ax.loglog(n_train_values, our_times, 'o-', color='coral',
lw=2.5, markersize=8, label='Our Implementation')
ax.loglog(n_train_values, sk_times, 's-', color='steelblue',
lw=2.5, markersize=8, label='Scikit-learn')
ax.set_xlabel("Training Set Size (log scale)", fontsize=12)
ax.set_ylabel("Prediction Time for 200 Queries (ms, log scale)", fontsize=12)
ax.set_title(f"KNN Performance: Our Implementation vs Scikit-learn\n"
f"({n_features}D features, K={k})", fontsize=12, fontweight='bold')
ax.legend(fontsize=10)
ax.grid(True, alpha=0.3, which='both')
plt.tight_layout()
plt.savefig("knn_performance_benchmark.png", dpi=150)
plt.show()
print("\nSaved: knn_performance_benchmark.png")
benchmark_knn_implementations(
n_train_values=[100, 500, 1000, 2000, 5000, 10000, 20000],
n_test=200, n_features=10, k=5
)Putting It All Together: Complete End-to-End Example
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import StratifiedKFold, cross_val_score
from sklearn.preprocessing import StandardScaler
import numpy as np
# Load dataset
data = load_breast_cancer()
X_bc, y_bc = data.data, data.target
print("=== Complete KNN Pipeline: Breast Cancer Dataset ===\n")
print(f" Samples: {X_bc.shape[0]} | Features: {X_bc.shape[1]}")
print(f" Positive (malignant): {(y_bc==0).sum()} | Negative (benign): {(y_bc==1).sum()}\n")
# Scale features (mandatory for KNN)
scaler_bc = StandardScaler()
X_bc_s = scaler_bc.fit_transform(X_bc)
# Grid search over K and weights using our implementation
print(" K sweep with cross-validation:\n")
print(f" {'K':>4} | {'Uniform Acc':>12} | {'Distance Acc':>13} | {'Best'}")
print(" " + "-" * 45)
skf = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)
best_acc, best_config = 0, None
for k in [1, 3, 5, 7, 10, 15, 20, 30]:
accs_uniform = []
accs_dist = []
for train_idx, val_idx in skf.split(X_bc_s, y_bc):
X_tr_f, X_va_f = X_bc_s[train_idx], X_bc_s[val_idx]
y_tr_f, y_va_f = y_bc[train_idx], y_bc[val_idx]
# Uniform
knn_u = KNNClassifier(k=k, weights='uniform')
knn_u.fit(X_tr_f, y_tr_f)
accs_uniform.append(knn_u.score(X_va_f, y_va_f))
# Distance-weighted
knn_d = KNNClassifier(k=k, weights='distance')
knn_d.fit(X_tr_f, y_tr_f)
accs_dist.append(knn_d.score(X_va_f, y_va_f))
acc_u = np.mean(accs_uniform)
acc_d = np.mean(accs_dist)
best_here = "← ★" if max(acc_u, acc_d) > best_acc else ""
if max(acc_u, acc_d) > best_acc:
best_acc = max(acc_u, acc_d)
best_config = (k, 'distance' if acc_d > acc_u else 'uniform')
print(f" {k:>4} | {acc_u:>12.4f} | {acc_d:>13.4f} | {best_here}")
print(f"\n Best: K={best_config[0]}, weights='{best_config[1]}', "
f"CV Accuracy={best_acc:.4f}")Stage 8: KNN Regressor
The KNNClassifier can be extended to regression with minimal changes: replace the voting step with a weighted mean. This demonstrates how the same architecture supports a completely different output type.
import numpy as np
class KNNRegressor:
"""
KNN Regressor: predicts the (weighted) mean of K nearest neighbors' values.
Shares all distance/neighbor-finding logic with KNNClassifier.
Only the aggregation step differs: mean instead of majority vote.
"""
def __init__(self, k=5, metric='euclidean', weights='uniform', p=3):
self.k = k
self.metric = metric
self.weights = weights
self.p = p
def fit(self, X, y):
self.X_train = np.array(X, dtype=float)
self.y_train = np.array(y, dtype=float)
self._dist_fn = DistanceMetrics.get(self.metric, p=self.p)
return self
def predict(self, X):
"""
Predict target values as the (weighted) mean of K neighbors.
For uniform weights: mean(y_k1, y_k2, ..., y_kK)
For distance weights: sum(w_i * y_ki) / sum(w_i)
where w_i = 1/d_i
"""
X = np.array(X, dtype=float)
# Compute all pairwise distances
D = self._dist_fn(self.X_train, X)
# Find K nearest neighbors for each query
k_indices = np.argpartition(D, self.k, axis=1)[:, :self.k]
k_dists = D[np.arange(len(X))[:, None], k_indices]
k_values = self.y_train[k_indices] # shape: (n_query, k)
if self.weights == 'uniform':
return k_values.mean(axis=1)
else: # distance-weighted
# Handle exact zero distances
zero_mask = (k_dists == 0)
any_zero = zero_mask.any(axis=1)
with np.errstate(divide='ignore', invalid='ignore'):
weights = np.where(k_dists == 0, 0.0, 1.0 / k_dists)
# For rows with zero distance: only zero-distance neighbors count
for i in np.where(any_zero)[0]:
weights[i] = 0.0
weights[i, zero_mask[i]] = 1.0
# Weighted mean
total_weight = weights.sum(axis=1, keepdims=True)
total_weight = np.where(total_weight == 0, 1.0, total_weight)
return (weights * k_values).sum(axis=1) / total_weight.ravel()
def score(self, X, y):
"""R² score (coefficient of determination)."""
y_pred = self.predict(X)
y = np.array(y, dtype=float)
ss_res = np.sum((y - y_pred) ** 2)
ss_tot = np.sum((y - y.mean()) ** 2)
return 1 - ss_res / ss_tot if ss_tot > 0 else 0.0
# Demonstrate on synthetic regression data
from sklearn.datasets import make_regression
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsRegressor as SklearnKNNR
from sklearn.metrics import r2_score, mean_squared_error
import numpy as np
np.random.seed(42)
# Nonlinear regression: KNN should handle this well
X_reg = np.linspace(0, 4 * np.pi, 500).reshape(-1, 1)
y_reg = np.sin(X_reg.ravel()) + np.cos(2 * X_reg.ravel()) + np.random.normal(0, 0.2, 500)
X_tr_r, X_te_r, y_tr_r, y_te_r = train_test_split(
X_reg, y_reg, test_size=0.2, random_state=42
)
scaler_r = StandardScaler()
X_tr_rs = scaler_r.fit_transform(X_tr_r)
X_te_rs = scaler_r.transform(X_te_r)
print("=== KNN Regressor: Nonlinear Regression ===\n")
print(f" {'K':>4} | {'Our R²':>9} | {'SK R²':>8} | {'Match':>7} | Weights")
print(" " + "-" * 45)
for k in [1, 5, 10, 20]:
for w in ['uniform', 'distance']:
# Our implementation
our_r = KNNRegressor(k=k, weights=w)
our_r.fit(X_tr_rs, y_tr_r)
our_r2 = our_r.score(X_te_rs, y_te_r)
# Scikit-learn reference
sk_r = SklearnKNNR(n_neighbors=k, weights=w)
sk_r.fit(X_tr_rs, y_tr_r)
sk_r2 = sk_r.score(X_te_rs, y_te_r)
match = "✓" if abs(our_r2 - sk_r2) < 0.001 else "✗"
print(f" {k:>4} | {our_r2:>9.4f} | {sk_r2:>8.4f} | {match:>7} | {w}")
# Visualize regression predictions at best K
import matplotlib.pyplot as plt
fig, axes = plt.subplots(1, 2, figsize=(14, 5))
x_vis = np.linspace(X_reg.min(), X_reg.max(), 300).reshape(-1, 1)
x_vis_s = scaler_r.transform(x_vis)
for ax, (k_vis, title) in zip(axes, [
(1, "K=1: Overfitting — jagged curve, memorizes each point"),
(15, "K=15: Smooth curve — captures trend, ignores noise"),
]):
reg_vis = KNNRegressor(k=k_vis, weights='distance')
reg_vis.fit(X_tr_rs, y_tr_r)
y_vis = reg_vis.predict(x_vis_s)
r2_vis = reg_vis.score(X_te_rs, y_te_r)
ax.scatter(X_tr_r, y_tr_r, color='steelblue', s=15, alpha=0.5, label='Training points')
ax.scatter(X_te_r, y_te_r, color='coral', s=20, alpha=0.7, label='Test points')
ax.plot(x_vis, y_vis, 'darkgreen', lw=2.5, label=f'KNN prediction (R²={r2_vis:.3f})')
# True function
y_true_vis = np.sin(x_vis.ravel()) + np.cos(2 * x_vis.ravel())
ax.plot(x_vis, y_true_vis, 'k--', lw=1.5, alpha=0.6, label='True function')
ax.set_title(title, fontsize=10, fontweight='bold')
ax.set_xlabel("X", fontsize=10)
ax.set_ylabel("y", fontsize=10)
ax.legend(fontsize=8)
ax.grid(True, alpha=0.3)
plt.suptitle("KNN Regression: Overfitting vs Appropriate Smoothing",
fontsize=13, fontweight='bold')
plt.tight_layout()
plt.savefig("knn_regression_demo.png", dpi=150)
plt.show()
print("Saved: knn_regression_demo.png")The regression visualization makes the bias-variance tradeoff concrete in a way that is visually unmistakable: K=1 produces a jagged interpolation that passes through every training point but oscillates wildly between them, while K=15 produces a smooth curve that captures the underlying sinusoidal pattern despite the noise.
Summary
Building KNN from scratch in stages reveals the algorithm’s full structure. The naive version is just a few lines of readable Python. Each optimization layer — vectorized distance computation, multiple metrics, weighted voting, partial sorting with argpartition, and KD-tree indexing — adds a capability or removes a performance bottleneck while keeping the core logic unchanged.
The most impactful optimizations are vectorizing the distance computation (replacing Python loops with NumPy array operations for a 50–200× speedup) and using np.argpartition instead of a full sort (O(n) instead of O(n log n) for finding the K smallest distances). Together, these make our implementation competitive with scikit-learn’s vectorized brute-force mode on small-to-medium datasets.
For production use, scikit-learn’s KNeighborsClassifier is still preferred — it implements KD-trees and ball trees in compiled C code with careful edge-case handling. But understanding how to build it from scratch means you can confidently adapt the algorithm to custom scenarios: non-standard distance metrics, weighted training examples, novel data structures, or hardware-specific optimizations.