Python has become the go-to programming language for artificial intelligence (AI) and machine learning (ML) due to its simplicity, readability, and extensive libraries. Whether you’re new to programming or an experienced developer, Python offers a robust ecosystem that makes it accessible for building AI applications. AI projects often require handling vast amounts of data, training complex algorithms, and optimizing models—tasks that Python simplifies with its rich library support and user-friendly syntax.
This article serves as a beginner’s guide to getting started with Python for AI. We’ll cover the fundamental libraries, set up your Python environment, and introduce the basic concepts needed for AI development, including data handling, model building, and deployment. Let’s dive into the essentials of Python for AI and the first steps to begin your journey.
Why Python for AI?
Python’s popularity in AI stems from several key factors that make it ideal for machine learning, data science, and AI applications:
- Ease of Use and Readability: Python’s syntax is straightforward and easy to understand, allowing developers to focus more on AI concepts rather than on complex code structure. This readability makes Python an excellent choice for beginners and facilitates collaboration among teams.
- Extensive Libraries and Frameworks: Python boasts an array of powerful libraries specifically designed for AI, ML, and data processing. Libraries like NumPy, Pandas, TensorFlow, and Scikit-Learn make it easy to perform calculations, manipulate data, and build complex models without starting from scratch.
- Community Support and Resources: Python has a vast community of developers and researchers in AI, providing a wealth of tutorials, documentation, and open-source code. This community support ensures that new learners have access to resources and that issues are quickly resolved.
- Compatibility with Major AI Tools: Python seamlessly integrates with major AI tools and platforms, including Jupyter Notebook, Google Colab, and cloud computing services. This compatibility allows developers to scale their projects and leverage cloud resources for faster processing.
With these advantages, Python offers an optimal environment for beginners and experts alike to build, test, and deploy AI models.
Setting Up Your Python Environment
Before you begin working on AI projects, you’ll need to set up a Python environment that includes the necessary tools and libraries. Here’s a step-by-step guide to getting started:
Step 1: Install Python
If you haven’t installed Python yet, you can download the latest version from Python’s official website. Python 3.x is recommended, as most AI libraries now support Python 3 rather than Python 2.
Step 2: Install Jupyter Notebook or JupyterLab
Jupyter Notebook is a popular tool for AI and data science projects, as it allows you to write code, run it, and visualize the results in an interactive environment. Install Jupyter Notebook by opening your command prompt or terminal and entering:
pip install jupyterAlternatively, you can install JupyterLab, a more feature-rich environment, using:
jupyter notebookor
jupyter labin your terminal. This will open a web-based interface where you can create and work with Python notebooks.
Step 3: Set Up a Virtual Environment
To manage dependencies for AI projects, it’s best practice to use a virtual environment. Virtual environments allow you to create isolated Python environments, ensuring that different projects do not interfere with each other’s dependencies.
To create a virtual environment, run:
python -m venv ai_envThen, activate it:
- On Windows:
ai_env\Scripts\activate- On macOS/Linux:
source ai_env/bin/activateOnce activated, install the necessary packages within this environment, which prevents version conflicts between projects.
Step 4: Install Essential Libraries
With your virtual environment ready, install the libraries that are fundamental for AI development:
pip install numpy pandas matplotlib scikit-learn tensorflowThese libraries provide the core functionality for data processing, visualization, and model building in Python, which we will explore further in the sections below.
Essential Python Libraries for AI
To build AI applications effectively, it’s crucial to understand the purpose of the main Python libraries used in AI development. Here’s an overview of some essential libraries:
1. NumPy
NumPy is a powerful library for numerical computing in Python, providing support for large, multi-dimensional arrays and matrices. It includes a collection of mathematical functions that are essential for AI, as data manipulation and mathematical operations form the foundation of machine learning.
- Example: Using NumPy to create an array and perform basic operations:
import numpy as np
# Creating an array
arr = np.array([1, 2, 3, 4, 5])
print("Array:", arr)
# Basic operations
print("Mean:", np.mean(arr))
print("Standard deviation:", np.std(arr))2.Pandas
Pandas is used for data manipulation and analysis, making it easier to clean, transform, and analyze datasets. Pandas provides data structures like DataFrames, which allow you to work with labeled and indexed data efficiently.
- Example: Loading a CSV file and performing basic data manipulation:
import pandas as pd
# Loading a CSV file
data = pd.read_csv('data.csv')
print(data.head())
# Basic data manipulation
data['New_Column'] = data['Existing_Column'] * 2
print(data.describe())3. Matplotlib
Visualization is key in AI, as it helps interpret data patterns and model performance. Matplotlib is a comprehensive library for creating static, animated, and interactive visualizations in Python.
- Example: Plotting data with Matplotlib:
import matplotlib.pyplot as plt
# Sample data
x = [1, 2, 3, 4, 5]
y = [2, 3, 5, 7, 11]
# Creating a line plot
plt.plot(x, y)
plt.xlabel('X-axis')
plt.ylabel('Y-axis')
plt.title('Sample Plot')
plt.show()4. Scikit-Learn
Scikit-Learn is a machine learning library that provides tools for data preprocessing, model selection, training, and evaluation. It includes a variety of ML algorithms, such as linear regression, decision trees, and clustering, making it a valuable library for AI beginners.
- Example: Performing linear regression with Scikit-Learn:
from sklearn.linear_model import LinearRegression
import numpy as np
# Sample data
X = np.array([[1], [2], [3], [4], [5]])
y = np.array([1, 2, 1.3, 3.75, 2.25])
# Model training
model = LinearRegression()
model.fit(X, y)
# Making predictions
predictions = model.predict(X)
print("Predictions:", predictions)5. TensorFlow
TensorFlow is an open-source deep learning library developed by Google. It is widely used for building and training neural networks, making it essential for AI projects that require deep learning techniques.
- Example: Creating a simple neural network with TensorFlow:
import tensorflow as tf
# Defining a simple model
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(10, activation='relu', input_shape=(5,)),
tf.keras.layers.Dense(1)
])
# Compiling the model
model.compile(optimizer='adam', loss='mse')
# Summary of the model
model.summary()These libraries provide the foundational tools needed for data handling, machine learning, and visualization in Python. By familiarizing yourself with them, you’re better equipped to start your journey into AI development.
Key Concepts in Artificial Intelligence
To start building AI applications, it’s essential to understand a few core concepts that form the foundation of AI and machine learning. Here’s an overview of some key concepts:
1. Machine Learning
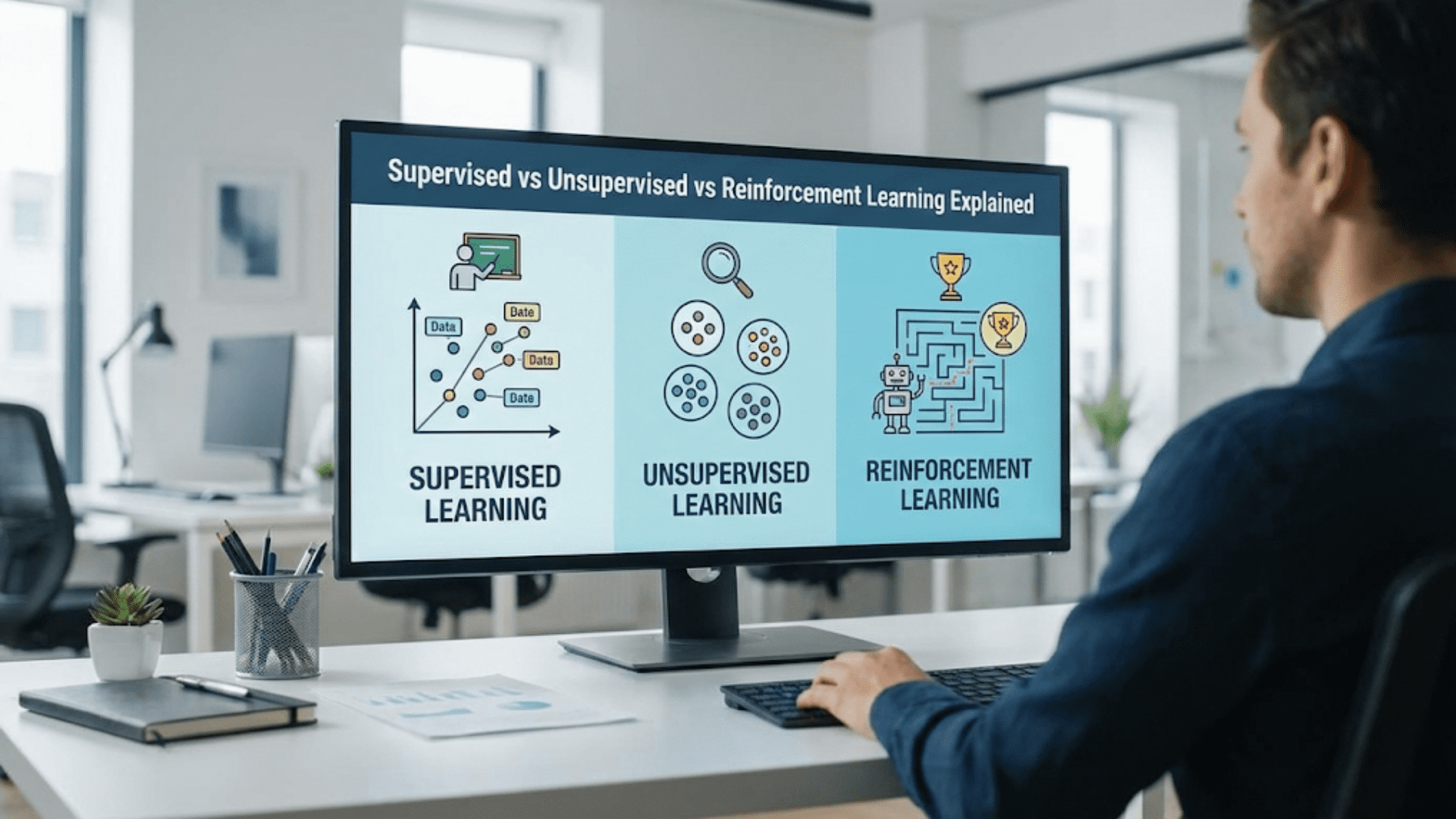
Machine Learning (ML) is a subset of AI that enables computers to learn from data and make predictions or decisions without explicit programming. ML algorithms analyze data, identify patterns, and improve over time. There are three main types of ML:
- Supervised Learning: In supervised learning, the model is trained on labeled data, meaning each input has a corresponding output. The goal is to map the input to the output accurately. Common algorithms include linear regression, decision trees, and support vector machines (SVMs).
- Unsupervised Learning: In unsupervised learning, the model is trained on unlabeled data. It finds patterns, clusters, or relationships within the data. Common techniques include clustering and dimensionality reduction (e.g., K-means clustering, principal component analysis).
- Reinforcement Learning: In reinforcement learning, an agent interacts with its environment and learns through trial and error, receiving rewards or penalties based on its actions. It’s commonly used in robotics, game playing, and self-driving cars.
2. Deep Learning
Deep Learning (DL) is a specialized subset of machine learning focused on neural networks with multiple layers (hence “deep” networks). These networks are particularly effective for processing large amounts of unstructured data, such as images, audio, and text. Deep learning enables complex tasks, including image recognition, natural language processing, and autonomous driving.
3. Model Training and Evaluation
Model training involves feeding data into a machine learning algorithm to help it “learn” and improve. This training process adjusts model parameters to minimize error and make accurate predictions. After training, the model is evaluated on unseen data (test data) to ensure it generalizes well and doesn’t just memorize training data.
4. Overfitting and Underfitting
- Overfitting: Overfitting occurs when a model performs exceptionally well on training data but poorly on new data, meaning it has memorized the training data rather than generalizing patterns.
- Underfitting: Underfitting happens when a model is too simple and doesn’t capture the underlying patterns in the data, leading to poor performance even on training data.
Balancing these issues is crucial in AI development to ensure that models are both accurate and adaptable to new situations.
Working with Datasets in Python
Data is at the heart of AI, and working effectively with datasets is essential. In this section, we’ll learn how to load, explore, and preprocess datasets using Python. For simplicity, we’ll use the famous Iris dataset, a popular dataset for beginners in machine learning, to illustrate these steps.
Loading the Dataset
The Iris dataset contains information about different species of Iris flowers, including their sepal length, sepal width, petal length, and petal width. The goal is to classify the flowers into three species based on these measurements.
The dataset can be loaded directly from the Scikit-Learn library:
from sklearn.datasets import load_iris
import pandas as pd
# Load the dataset
data = load_iris()
df = pd.DataFrame(data.data, columns=data.feature_names)
df['species'] = data.target
# Display the first few rows
print(df.head())Exploring the Dataset
Once the data is loaded, it’s essential to explore it to understand its structure, identify missing values, and visualize relationships between features. Here are some basic exploration steps:
# Summary statistics
print(df.describe())
# Checking for missing values
print(df.isnull().sum())
# Distribution of target classes (species)
print(df['species'].value_counts())Visualizing Data with Matplotlib
Data visualization is useful for identifying trends and relationships in the dataset. Using Matplotlib, we can create basic plots to examine the features in the Iris dataset.
import matplotlib.pyplot as plt
# Scatter plot of petal length vs petal width
plt.scatter(df['petal length (cm)'], df['petal width (cm)'], c=df['species'], cmap='viridis')
plt.xlabel('Petal Length (cm)')
plt.ylabel('Petal Width (cm)')
plt.title('Petal Length vs Petal Width')
plt.show()In this scatter plot, each point represents a flower, and colors indicate different species. This visualization helps us see how features are related and if they might be useful for classification.
Data Preprocessing
Data often needs to be preprocessed to make it suitable for machine learning. In this example, we’ll split the dataset into training and testing sets and scale the features to ensure uniformity, which can improve model performance.
- Splitting the Data: We’ll divide the data into training and testing sets to evaluate the model’s performance on unseen data.
- Scaling the Features: Scaling ensures that features are on a similar scale, which can improve the performance of many machine learning algorithms.
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
# Split the data into features and target variable
X = df.drop('species', axis=1)
y = df['species']
# Split into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Scale the features
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)ow we have our data prepared for model training. We’ve scaled the features and split the data to ensure that the model’s performance will be tested on unseen data.
Building a Simple Machine Learning Model
With the data ready, we can build a basic machine learning model to classify the Iris flowers. For this example, we’ll use a k-Nearest Neighbors (k-NN) classifier, a simple yet effective algorithm for classification.
Training the k-NN Model
The k-Nearest Neighbors algorithm classifies data points based on the classes of their nearest neighbors. It’s easy to implement and interpretable, making it a good choice for beginners.
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score
# Initialize the k-NN classifier with k=3
model = KNeighborsClassifier(n_neighbors=3)
# Train the model on the training data
model.fit(X_train, y_train)Evaluating the Model
Once the model is trained, we’ll test its performance on the test set and evaluate its accuracy. Accuracy is a basic metric that tells us the percentage of correct predictions.
# Make predictions on the test set
y_pred = model.predict(X_test)
# Calculate accuracy
accuracy = accuracy_score(y_test, y_pred)
print("Model Accuracy:", accuracy)This accuracy score gives us a quick idea of how well the model is performing. As you progress, you can explore additional metrics, such as precision, recall, and F1-score, to gain a more comprehensive understanding of the model’s effectiveness.
Experimenting with Different Models
Scikit-Learn provides several classification algorithms, such as Decision Trees, Support Vector Machines, and Naive Bayes, which you can try on the Iris dataset. Experimenting with different algorithms can help you understand which models work best for specific datasets.
For example, to use a Decision Tree classifier, you would initialize and train it as follows:
from sklearn.tree import DecisionTreeClassifier
# Initialize and train the Decision Tree model
tree_model = DecisionTreeClassifier()
tree_model.fit(X_train, y_train)
# Evaluate the Decision Tree model
tree_accuracy = accuracy_score(y_test, tree_model.predict(X_test))
print("Decision Tree Model Accuracy:", tree_accuracy)Testing multiple models is a great way to learn about different algorithms and their strengths and weaknesses in various scenarios.
Model Evaluation Techniques
After building a machine learning model, it’s essential to evaluate its performance thoroughly. Accuracy alone doesn’t always provide a complete picture, especially for unbalanced datasets. Let’s look at other key evaluation metrics and methods that help assess model quality:
1. Confusion Matrix
A confusion matrix is a table that summarizes the performance of a classification model by showing the counts of true positives, true negatives, false positives, and false negatives. It helps visualize how well the model performs across each class.
- Example:
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
# Generate confusion matrix
cm = confusion_matrix(y_test, y_pred)
ConfusionMatrixDisplay(cm, display_labels=data.target_names).plot()
plt.show()A confusion matrix is particularly helpful for detecting specific classes that the model may struggle to classify correctly.
2. Precision, Recall, and F1-Score
For cases where we care about minimizing false positives or false negatives, precision and recall are useful metrics:
- Precision: The percentage of positive predictions that are correct.
- Recall: The percentage of actual positives that the model correctly identifies.
- F1-Score: The harmonic mean of precision and recall, providing a balanced metric.
- Example:
from sklearn.metrics import precision_score, recall_score, f1_score
precision = precision_score(y_test, y_pred, average='macro')
recall = recall_score(y_test, y_pred, average='macro')
f1 = f1_score(y_test, y_pred, average='macro')
print(f"Precision: {precision}")
print(f"Recall: {recall}")
print(f"F1-Score: {f1}")These metrics are especially valuable for imbalanced datasets, where accuracy might be misleading.
3. Cross-Validation
Cross-validation is a technique that splits the dataset into multiple folds and trains the model on each fold, helping verify that the model generalizes well across different subsets of data.
- Example:
from sklearn.model_selection import cross_val_score
# Perform 5-fold cross-validation
cv_scores = cross_val_score(model, X, y, cv=5)
print("Cross-Validation Scores:", cv_scores)
print("Mean Cross-Validation Score:", cv_scores.mean())By using cross-validation, you can get a more reliable estimate of the model’s performance on unseen data, reducing the risk of overfitting.
Hyperparameter Tuning for Model Optimization
Hyperparameters are settings in machine learning models that influence their learning process. Unlike model parameters, which are learned during training, hyperparameters need to be set before training begins. Tuning these hyperparameters can significantly improve model performance.
1. Grid Search
Grid search is a systematic method to test different combinations of hyperparameters to find the best configuration for the model. This approach can be time-consuming but effective, especially for small datasets or simple models.
- Example:
from sklearn.model_selection import GridSearchCV
# Define hyperparameters to tune
param_grid = {
'n_neighbors': [3, 5, 7],
'weights': ['uniform', 'distance']
}
# Perform grid search with cross-validation
grid_search = GridSearchCV(KNeighborsClassifier(), param_grid, cv=5)
grid_search.fit(X_train, y_train)
print("Best Parameters:", grid_search.best_params_)
print("Best Cross-Validation Score:", grid_search.best_score_)2. Random Search
Random search is an alternative to grid search, where random combinations of hyperparameters are tested. It’s often faster and can still yield excellent results, especially for large parameter spaces.
- Example:
from sklearn.model_selection import RandomizedSearchCV
from scipy.stats import randint
# Define hyperparameter distribution
param_dist = {
'n_neighbors': randint(1, 20),
'weights': ['uniform', 'distance']
}
# Perform random search
random_search = RandomizedSearchCV(KNeighborsClassifier(), param_distributions=param_dist, n_iter=10, cv=5)
random_search.fit(X_train, y_train)
print("Best Parameters:", random_search.best_params_)
print("Best Cross-Validation Score:", random_search.best_score_)Hyperparameter tuning, whether via grid search or random search, can make a significant difference in model performance, especially for complex models like decision trees, neural networks, or ensemble models.
Deploying AI Models in Production
After building and tuning a model, the final step is deploying it in a real-world environment. Deployment means making the model accessible for live predictions, either through an application or a cloud-based API. Here are some practical approaches to model deployment:
1. Saving and Loading Models
Scikit-Learn provides a straightforward way to save and load models, which is useful for deploying a model or sharing it with others.
- Example:
import joblib
# Save the model
joblib.dump(model, 'knn_model.pkl')
# Load the model
loaded_model = joblib.load('knn_model.pkl')Once saved, the model file can be loaded in a different environment for predictions, allowing seamless deployment.
2. Flask for Web API Deployment
Flask is a lightweight web framework in Python that can be used to create an API endpoint for your model. By using Flask, you can expose your model’s predictions over HTTP, making it accessible for web or mobile applications.
- Example:
from flask import Flask, request, jsonify
import joblib
# Load the trained model
model = joblib.load('knn_model.pkl')
# Initialize Flask app
app = Flask(__name__)
@app.route('/predict', methods=['POST'])
def predict():
# Get JSON data from request
data = request.get_json(force=True)
prediction = model.predict([data['features']])
return jsonify({'prediction': prediction[0]})
if __name__ == '__main__':
app.run(debug=True)This code sets up a simple API endpoint that accepts input data (in JSON format) and returns predictions. Flask applications can be deployed on cloud platforms, such as AWS, Google Cloud, or Heroku, for real-time predictions.
3. Using Cloud Platforms
Cloud platforms like Amazon SageMaker, Google AI Platform, and Microsoft Azure offer managed services for deploying AI models. These platforms allow you to upload and deploy your model in a scalable, secure environment with minimal infrastructure setup.
- Benefits of Cloud Deployment:
- Scalability: Cloud platforms handle increased traffic and scale as needed, ensuring consistent performance.
- Security: Cloud providers implement strong security measures, safeguarding data and predictions.
- Integrated Tools: Most platforms include monitoring, logging, and version control, simplifying model management in production.
By deploying on a cloud platform, you can make your AI model available to multiple users and applications, ensuring reliable, scalable predictions.
Tips for Successful AI Development
- Document Your Process: Keep thorough records of your data sources, model parameters, and evaluation metrics. This documentation will help you understand your results and facilitate collaboration.
- Use Version Control: Using version control systems like Git allows you to track changes, revert to previous versions, and collaborate with others seamlessly. Version control is especially valuable for complex AI projects with multiple iterations.
- Monitor Model Performance: Once a model is in production, its performance may change over time due to new data or environmental changes. Monitoring tools help detect performance drift and identify when a model needs retraining.
- Stay Updated with Libraries and Tools: Python libraries are frequently updated with new features, optimizations, and bug fixes. Staying current ensures you’re using the latest advancements in AI development.
- Experiment and Iterate: AI development often requires multiple iterations, so don’t hesitate to try different models, parameters, and data preprocessing techniques. Experimentation is key to finding the best solution.
Conclusion
Python provides an accessible yet powerful foundation for diving into artificial intelligence and machine learning. With its intuitive syntax and robust ecosystem of libraries, Python simplifies the AI development process, from data handling and model training to evaluation and deployment. In this guide, we explored the essential tools, built a basic model, and examined best practices for evaluating, tuning, and deploying AI models.
Starting your journey with Python for AI is an exciting step into a field that’s shaping the future of technology. As you gain experience, experiment with different algorithms, explore deeper into neural networks, and engage with the AI community to stay updated on best practices. Python will be a reliable partner in your AI journey, enabling you to turn data into valuable insights and innovative solutions.