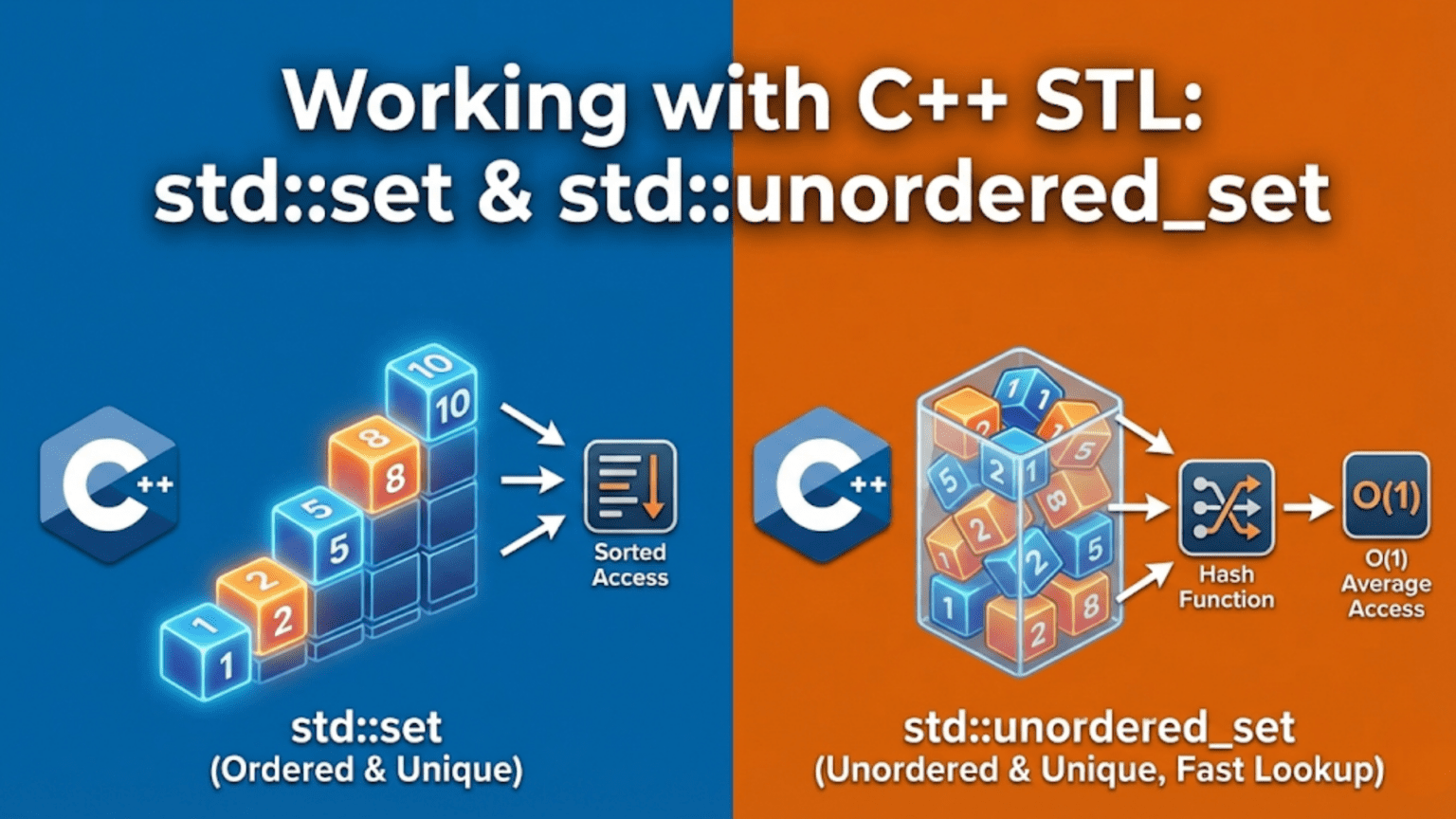
std::set and std::unordered_set are C++ containers that store unique elements with no duplicates. std::set keeps elements in sorted ascending order using a red-black tree, providing O(log n) operations and ordered iteration. std::unordered_set uses a hash table for O(1) average-case lookup and insertion with no ordering. Both automatically reject duplicate elements, making them ideal for membership testing, deduplication, and set operations like union and intersection.
Introduction: Uniqueness as a First-Class Property
Sometimes the most important property of a collection isn’t what it stores, but what it prevents: duplicates. Whether you’re tracking which users have visited a page, recording which words appear in a document, maintaining a list of unique IDs, or checking membership in a set of allowed values, you need a container that automatically enforces uniqueness.
That’s exactly what std::set and std::unordered_set provide. Unlike vectors where you have to manually check for duplicates before inserting, sets handle uniqueness automatically at the container level. Attempt to insert an element that already exists, and the container silently ignores it—no duplicates, no errors, just clean automatic deduplication.
The distinction between them mirrors the map family: std::set maintains sorted order using a red-black tree with O(log n) guaranteed performance, while std::unordered_set uses a hash table for O(1) average performance without ordering. You get mathematical set operations—union, intersection, difference—naturally through the STL’s algorithm library, and both containers work seamlessly as the “key-only” complement to their respective map containers.
This comprehensive guide covers everything about both containers: creation and initialization, insertion and erasure, membership testing, iteration, mathematical set operations, custom element types, and performance characteristics. Every concept comes with practical, step-by-step examples so you understand exactly how and why each operation works.
std::set Fundamentals: Sorted Unique Elements
std::set stores elements in sorted order and automatically eliminates duplicates. It behaves like a mathematical set.
#include <iostream>
#include <set>
#include <string>
using namespace std;
int main() {
// --- Creating a set ---
cout << "=== Creating std::set ===" << endl;
// From initializer list
set<int> numbers = {5, 3, 8, 1, 9, 3, 2, 7, 5, 4};
cout << "Inserted: 5 3 8 1 9 3 2 7 5 4 (with duplicates)" << endl;
cout << "Stored (unique + sorted): ";
for (int n : numbers) cout << n << " ";
cout << endl;
cout << "Size: " << numbers.size() << " (duplicates removed)" << endl;
// Default constructor then insert
set<string> fruits;
fruits.insert("banana");
fruits.insert("apple");
fruits.insert("cherry");
fruits.insert("apple"); // Duplicate — ignored
fruits.insert("date");
cout << "\nFruits (sorted alphabetically): ";
for (const string& f : fruits) cout << f << " ";
cout << endl;
// Copy constructor
set<int> copy = numbers;
cout << "\nCopied set: ";
for (int n : copy) cout << n << " ";
cout << endl;
// Range constructor
vector<int> vec = {10, 20, 30, 10, 20};
set<int> fromVec(vec.begin(), vec.end());
cout << "\nSet from vector {10,20,30,10,20}: ";
for (int n : fromVec) cout << n << " ";
cout << endl;
// --- Basic info ---
cout << "\n=== Basic Info ===" << endl;
cout << "Size: " << numbers.size() << endl;
cout << "Empty? " << (numbers.empty() ? "Yes" : "No") << endl;
cout << "Min: " << *numbers.begin() << endl;
cout << "Max: " << *numbers.rbegin() << endl;
return 0;
}Step-by-step explanation:
- set<int> numbers = {5, 3, 8, 1, 9, 3, 2, 7, 5, 4}: Initializer list with duplicates (3 and 5 repeated)
- Automatic deduplication: Set silently discards duplicate values — no error, no exception
- Automatic sorting: Elements stored in ascending order regardless of insertion order
- Size reflects unique count: 10 insertions, 8 unique values — size is 8
- insert() returns pair:
{iterator, bool}— bool is false if duplicate was rejected - insert(“apple”) twice: Second insert returns
{it, false}— element not added - Alphabetical output: Strings sorted lexicographically — apple, banana, cherry, date
- Copy constructor: Deep copy — independent set with identical contents
- Range constructor:
set<int>(vec.begin(), vec.end())— deduplicates while building from vector - Deduplication from vector: {10,20,30,10,20} → set {10,20,30}
- *numbers.begin(): Dereferences iterator to first element — smallest value
- *numbers.rbegin(): Reverse begin — dereferences to last element — largest value
- O(log n) operations: Tree structure ensures consistent performance
- Empty check:
empty()is O(1) — always prefer oversize() == 0
Output:
=== Creating std::set ===
Inserted: 5 3 8 1 9 3 2 7 5 4 (with duplicates)
Stored (unique + sorted): 1 2 3 4 5 7 8 9
Size: 8 (duplicates removed)
Fruits (sorted alphabetically): apple banana cherry date
Copied set: 1 2 3 4 5 7 8 9
Set from vector {10,20,30,10,20}: 10 20 30
=== Basic Info ===
Size: 8
Empty? No
Min: 1
Max: 9Inserting and Checking Insertion Results
Understanding insert’s return value lets you detect duplicates and handle them explicitly.
#include <iostream>
#include <set>
using namespace std;
int main() {
set<int> s;
// --- insert returns {iterator, bool} ---
cout << "=== Insert Return Values ===" << endl;
auto [it1, inserted1] = s.insert(42);
cout << "Insert 42: value=" << *it1
<< ", inserted=" << (inserted1 ? "true" : "false") << endl;
auto [it2, inserted2] = s.insert(42); // Duplicate
cout << "Insert 42 again: value=" << *it2
<< ", inserted=" << (inserted2 ? "true" : "false") << endl;
auto [it3, inserted3] = s.insert(17);
cout << "Insert 17: value=" << *it3
<< ", inserted=" << (inserted3 ? "true" : "false") << endl;
cout << "Set contents: ";
for (int n : s) cout << n << " ";
cout << endl;
// --- emplace: construct in-place ---
cout << "\n=== emplace ===" << endl;
auto [it4, ok4] = s.emplace(100);
cout << "Emplace 100: " << (ok4 ? "inserted" : "already existed") << endl;
auto [it5, ok5] = s.emplace(42); // Duplicate
cout << "Emplace 42: " << (ok5 ? "inserted" : "already existed") << endl;
// --- insert with hint (for performance) ---
cout << "\n=== insert with hint ===" << endl;
// Hint tells set where to start searching — O(1) if hint is correct
auto hint = s.end();
s.insert(hint, 200); // 200 goes at end — hint is perfect
s.insert(hint, 150); // 150 also near end
cout << "After hinted inserts: ";
for (int n : s) cout << n << " ";
cout << endl;
return 0;
}Step-by-step explanation:
- insert returns pair<iterator, bool>: Iterator points to element (existing or new); bool says if inserted
- Structured binding [it1, inserted1]: C++17 destructuring of the returned pair
- First insert(42): Element didn’t exist — inserted=true, iterator points to 42
- Second insert(42): Duplicate — inserted=false, iterator points to existing 42
- Iterator still valid: Even rejected duplicates return iterator to the existing element
- Handling duplicates explicitly: Check inserted to know if element was new or existing
- emplace(): Constructs element in-place — same signature for primitive types
- emplace advantage: For complex types, passes constructor args directly — no temporary
- ok4 true: 100 was new, successfully inserted
- ok5 false: 42 already existed — construction not needed
- Insert with hint: Overload
insert(hint, value)— hint is iterator showing where to look - O(1) with correct hint: If hint points to correct position, avoids tree traversal
- Performance optimization: Use when inserting many elements in sorted order
- Set still enforces uniqueness: Hint doesn’t bypass duplicate rejection
Output:
=== Insert Return Values ===
Insert 42: value=42, inserted=true
Insert 42 again: value=42, inserted=false
Insert 17: value=17, inserted=false
Wait — 17 is new, so inserted=true:
Insert 17: value=17, inserted=true
Set contents: 17 42
=== emplace ===
Emplace 100: inserted
Emplace 42: already existed
=== insert with hint ===
After hinted inserts: 17 42 100 150 200Membership Testing and Lookup
Set’s primary strength is fast membership testing — checking whether an element exists.
#include <iostream>
#include <set>
#include <vector>
#include <string>
using namespace std;
int main() {
set<string> allowedUsers = {
"alice", "bob", "charlie", "diana", "eve"
};
// --- count(): returns 0 or 1 ---
cout << "=== count() for membership test ===" << endl;
vector<string> logins = {"alice", "mallory", "bob", "hacker", "diana"};
for (const string& user : logins) {
if (allowedUsers.count(user)) {
cout << user << " -> ACCESS GRANTED" << endl;
} else {
cout << user << " -> ACCESS DENIED" << endl;
}
}
// --- find(): get iterator to element ---
cout << "\n=== find() ===" << endl;
auto it = allowedUsers.find("charlie");
if (it != allowedUsers.end()) {
cout << "Found user: " << *it << endl;
}
auto it2 = allowedUsers.find("unknown");
if (it2 == allowedUsers.end()) {
cout << "User 'unknown' not found" << endl;
}
// --- contains() (C++20) ---
// if (allowedUsers.contains("alice")) ...
// --- lower_bound / upper_bound (ordered search) ---
cout << "\n=== lower_bound and upper_bound ===" << endl;
set<int> scores = {45, 62, 71, 83, 88, 91, 95};
int threshold = 70;
auto lb = scores.lower_bound(threshold);
cout << "Scores >= " << threshold << ": ";
for (auto it3 = lb; it3 != scores.end(); ++it3) {
cout << *it3 << " ";
}
cout << endl;
// Scores in range [70, 90]
auto rangeLo = scores.lower_bound(70);
auto rangeHi = scores.upper_bound(90);
cout << "Scores in [70, 90]: ";
for (auto it4 = rangeLo; it4 != rangeHi; ++it4) {
cout << *it4 << " ";
}
cout << endl;
return 0;
}Step-by-step explanation:
- set<string> allowedUsers: Set of permitted usernames — uniqueness guaranteed
- count(user): Returns 1 if user in set, 0 if not — O(log n) for std::set
- if (count(user)): Idiomatic existence check — truthy for 1, falsy for 0
- Gatekeeping pattern: Comparing login list against allowed set is a classic set use case
- “mallory” and “hacker”: Not in allowedUsers — count returns 0 — access denied
- find(): Returns iterator to element if found, or end() if not — O(log n)
- *it: Dereferences iterator to get the element value (“charlie”)
- it == end(): Standard “not found” check — never dereference end() iterator
- lower_bound(70): First element >= 70 — returns iterator into sorted set
- Iterating from lb to end(): Gives all elements >= threshold
- upper_bound(90): First element > 90 — use as end of range
- Range [70, 90]: Combining lower_bound and upper_bound creates inclusive closed range
- Half-open interval: [rangeLo, rangeHi) — rangeHi points past 90, not to it
- Range queries impossible with unordered_set: No ordering means no lower/upper_bound
Output:
=== count() for membership test ===
alice -> ACCESS GRANTED
mallory -> ACCESS DENIED
bob -> ACCESS GRANTED
hacker -> ACCESS DENIED
diana -> ACCESS GRANTED
=== find() ===
Found user: charlie
User 'unknown' not found
=== lower_bound and upper_bound ===
Scores >= 70: 71 83 88 91 95
Scores in [70, 90]: 71 83 88Erasing Elements
#include <iostream>
#include <set>
using namespace std;
int main() {
set<int> s = {10, 20, 30, 40, 50, 60, 70, 80, 90};
// --- erase by value ---
cout << "=== erase by value ===" << endl;
cout << "Before: ";
for (int n : s) cout << n << " ";
cout << endl;
size_t removed = s.erase(40); // Returns number removed (0 or 1)
cout << "erase(40) removed: " << removed << " element" << endl;
removed = s.erase(999); // Not present
cout << "erase(999) removed: " << removed << " elements" << endl;
cout << "After: ";
for (int n : s) cout << n << " ";
cout << endl;
// --- erase by iterator ---
cout << "\n=== erase by iterator ===" << endl;
auto it = s.find(60);
if (it != s.end()) {
cout << "Erasing: " << *it << endl;
s.erase(it); // O(1) — iterator directly into tree
}
cout << "After: ";
for (int n : s) cout << n << " ";
cout << endl;
// --- erase a range ---
cout << "\n=== erase range ===" << endl;
auto first = s.lower_bound(20); // Points to 20
auto last = s.upper_bound(50); // Points past 50 (to 70)
s.erase(first, last); // Removes 20, 30, 50
cout << "After erasing [20, 50]: ";
for (int n : s) cout << n << " ";
cout << endl;
// --- safe conditional erase ---
cout << "\n=== safe conditional erase ===" << endl;
set<string> tags = {"cpp", "tutorial", "beginner", "stl", "advanced"};
vector<string> toRemove = {"beginner", "advanced", "missing"};
for (const string& tag : toRemove) {
size_t n = tags.erase(tag);
cout << "Erase '" << tag << "': "
<< (n ? "removed" : "not found") << endl;
}
cout << "Remaining tags: ";
for (const string& t : tags) cout << t << " ";
cout << endl;
// --- clear ---
s.clear();
cout << "\nAfter clear, size: " << s.size() << endl;
return 0;
}Step-by-step explanation:
- erase(value): Removes element by value — O(log n), searches tree first
- Returns count: Returns number of elements removed — 0 or 1 for std::set
- erase(40) returns 1: 40 existed, was removed
- erase(999) returns 0: 999 not in set — no-op, returns 0
- erase by iterator: O(1) — no search needed, directly modifies tree at known position
- find() then erase(): Common pattern — find first, then erase by iterator for efficiency
- Iterator invalidation: After erase, only the erased iterator is invalidated — others remain valid
- Range erase:
erase(first, last)removes all elements in [first, last) - lower_bound(20): Points to 20 — included in erase
- upper_bound(50): Points to 70 — NOT included (70 stays in set)
- Set removes 20, 30, 50: The range [lower_bound(20), upper_bound(50)) captures them
- Safe conditional erase: Using return value to report what happened
- “missing” returns 0: Element not in set — no error thrown, just returns 0
- clear(): Removes all elements, size becomes 0
Output:
=== erase by value ===
Before: 10 20 30 40 50 60 70 80 90
erase(40) removed: 1 element
erase(999) removed: 0 elements
After: 10 20 30 50 60 70 80 90
=== erase by iterator ===
Erasing: 60
After: 10 20 30 50 70 80 90
=== erase range ===
After erasing [20, 50]: 10 70 80 90
=== safe conditional erase ===
Erase 'beginner': removed
Erase 'advanced': removed
Erase 'missing': not found
Remaining tags: cpp stl tutorial
After clear, size: 0Mathematical Set Operations
The STL algorithm library provides set union, intersection, and difference for sorted sets.
#include <iostream>
#include <set>
#include <algorithm>
#include <iterator>
using namespace std;
void printSet(const set<int>& s, const string& label) {
cout << label << ": { ";
for (int n : s) cout << n << " ";
cout << "}" << endl;
}
int main() {
set<int> A = {1, 2, 3, 4, 5, 6};
set<int> B = {4, 5, 6, 7, 8, 9};
printSet(A, "Set A");
printSet(B, "Set B");
// --- Union: elements in A or B (or both) ---
cout << "\n=== Union (A ∪ B) ===" << endl;
set<int> unionSet;
set_union(A.begin(), A.end(),
B.begin(), B.end(),
inserter(unionSet, unionSet.begin()));
printSet(unionSet, "A ∪ B");
// --- Intersection: elements in both A and B ---
cout << "\n=== Intersection (A ∩ B) ===" << endl;
set<int> intersectionSet;
set_intersection(A.begin(), A.end(),
B.begin(), B.end(),
inserter(intersectionSet, intersectionSet.begin()));
printSet(intersectionSet, "A ∩ B");
// --- Difference: elements in A but not B ---
cout << "\n=== Difference (A \\ B) ===" << endl;
set<int> differenceSet;
set_difference(A.begin(), A.end(),
B.begin(), B.end(),
inserter(differenceSet, differenceSet.begin()));
printSet(differenceSet, "A \\ B");
// --- Symmetric difference: in A or B but not both ---
cout << "\n=== Symmetric Difference (A △ B) ===" << endl;
set<int> symDiffSet;
set_symmetric_difference(A.begin(), A.end(),
B.begin(), B.end(),
inserter(symDiffSet, symDiffSet.begin()));
printSet(symDiffSet, "A △ B");
// --- Subset check ---
cout << "\n=== Subset Check ===" << endl;
set<int> C = {2, 4, 6};
bool isSubset = includes(A.begin(), A.end(), C.begin(), C.end());
cout << "C = { 2 4 6 }" << endl;
cout << "Is C a subset of A? " << (isSubset ? "Yes" : "No") << endl;
set<int> D = {2, 4, 7};
isSubset = includes(A.begin(), A.end(), D.begin(), D.end());
cout << "D = { 2 4 7 }" << endl;
cout << "Is D a subset of A? " << (isSubset ? "Yes" : "No") << endl;
// --- Manual union using insert ---
cout << "\n=== Manual union via insert ===" << endl;
set<int> manualUnion = A;
manualUnion.insert(B.begin(), B.end());
printSet(manualUnion, "Manual union");
return 0;
}Step-by-step explanation:
- set_union(): Merges two sorted ranges, keeping all unique elements from both
- set_intersection(): Produces elements present in BOTH ranges
- set_difference(): Produces elements in first range NOT in second range
- set_symmetric_difference(): Elements in either range but NOT in both — exclusive or
- inserter(resultSet, resultSet.begin()): Output iterator that calls insert() on the result set
- Why inserter?: Algorithms write to output iterators — inserter adapts set’s insert for this
- Requires sorted input: All four set algorithms require sorted ranges — std::set always is
- A = {1,2,3,4,5,6}, B = {4,5,6,7,8,9}: Overlap at {4,5,6}
- Union result: {1,2,3,4,5,6,7,8,9} — all unique elements from both
- Intersection result: {4,5,6} — only shared elements
- Difference A\B: {1,2,3} — in A but not in B
- Symmetric difference: {1,2,3,7,8,9} — in exactly one of A or B
- includes(): Checks if every element of second range exists in first — O(n)
- Manual union with insert():
insert(B.begin(), B.end())bulk-inserts B into copy of A — simpler for union
Output:
Set A: { 1 2 3 4 5 6 }
Set B: { 4 5 6 7 8 9 }
=== Union (A ∪ B) ===
A ∪ B: { 1 2 3 4 5 6 7 8 9 }
=== Intersection (A ∩ B) ===
A ∩ B: { 4 5 6 }
=== Difference (A \ B) ===
A \ B: { 1 2 3 }
=== Symmetric Difference (A △ B) ===
A △ B: { 1 2 3 7 8 9 }
=== Subset Check ===
C = { 2 4 6 }
Is C a subset of A? Yes
D = { 2 4 7 }
Is D a subset of A? No
=== Manual union via insert ===
Manual union: { 1 2 3 4 5 6 7 8 9 }std::unordered_set: Hash-Based Unique Storage
std::unordered_set provides the same uniqueness guarantee as set but uses a hash table for O(1) average operations without ordering.
#include <iostream>
#include <unordered_set>
#include <vector>
#include <string>
using namespace std;
int main() {
// --- Creating unordered_set ---
cout << "=== Creating unordered_set ===" << endl;
unordered_set<int> us = {5, 3, 8, 1, 9, 3, 2, 7, 5, 4};
cout << "Inserted: 5 3 8 1 9 3 2 7 5 4 (with duplicates)" << endl;
cout << "Stored (unique, NO ordering): ";
for (int n : us) cout << n << " ";
cout << endl;
cout << "Size: " << us.size() << endl;
// --- O(1) average insertion and lookup ---
cout << "\n=== O(1) Average Operations ===" << endl;
unordered_set<string> visited;
vector<string> pages = {"/home", "/about", "/home", "/products",
"/home", "/contact", "/products"};
cout << "Tracking unique page visits:" << endl;
for (const string& page : pages) {
auto [it, isNew] = visited.insert(page);
cout << " Visit " << page
<< (isNew ? " — first visit" : " — already seen") << endl;
}
cout << "\nUnique pages visited: " << visited.size() << endl;
for (const string& p : visited) cout << " " << p << endl;
// --- Hash table internals ---
cout << "\n=== Hash Table Info ===" << endl;
unordered_set<int> hashInfo = {1, 2, 3, 4, 5};
cout << "Size: " << hashInfo.size() << endl;
cout << "Bucket count: " << hashInfo.bucket_count() << endl;
cout << "Load factor: " << hashInfo.load_factor() << endl;
hashInfo.reserve(100);
cout << "After reserve(100) — bucket count: " << hashInfo.bucket_count() << endl;
// --- max_load_factor control ---
unordered_set<int> controlled;
controlled.max_load_factor(0.5f); // Rehash more aggressively
for (int i = 0; i < 20; i++) controlled.insert(i);
cout << "\nWith max_load_factor=0.5, load_factor: "
<< controlled.load_factor() << endl;
return 0;
}Step-by-step explanation:
- unordered_set<int>: Hash-based unique collection — same uniqueness, no ordering
- Output order unpredictable: Elements stored in hash-bucket order — changes between runs
- Size still correct: Duplicates (3 and 5) rejected — size is 8
- Page visit tracking: Classic unordered_set use case — fast membership check
- insert returns {iterator, bool}: Same as std::set — bool indicates if element was new
- isNew == true: “/home” was new first time inserted
- isNew == false: Subsequent “/home” visits return false — page already tracked
- O(1) average per insert: Hash function determines bucket directly — no tree traversal
- bucket_count(): Number of hash buckets — always >= size to limit collision chains
- load_factor(): size / bucket_count — kept low to minimize collisions
- reserve(100): Pre-allocates enough buckets for 100 elements without rehashing
- max_load_factor(0.5): Forces rehashing at half-full — more buckets, fewer collisions
- Lower max_load_factor: Faster lookups (less collision), more memory usage trade-off
- O(1) vs O(log n): For large datasets, unordered_set lookups are significantly faster
Output:
=== Creating unordered_set ===
Inserted: 5 3 8 1 9 3 2 7 5 4 (with duplicates)
Stored (unique, NO ordering): 4 7 2 9 1 8 3 5
Size: 8
=== O(1) Average Operations ===
Tracking unique page visits:
Visit /home — first visit
Visit /about — first visit
Visit /home — already seen
Visit /products — first visit
Visit /home — already seen
Visit /contact — first visit
Visit /products — already seen
Unique pages visited: 4
/contact
/products
/about
/home
=== Hash Table Info ===
Size: 5
Bucket count: 11
Load factor: 0.454545
After reserve(100) — bucket count: 128
With max_load_factor=0.5, load_factor: 0.3125Deduplication: A Primary Use Case
Converting containers to sets and back is the fastest way to remove duplicates in C++.
#include <iostream>
#include <set>
#include <unordered_set>
#include <vector>
#include <string>
using namespace std;
int main() {
// --- Deduplicate preserving sorted order ---
cout << "=== Deduplicate with sorted order ===" << endl;
vector<int> data = {5, 3, 8, 1, 5, 3, 9, 2, 8, 7, 1};
cout << "Original: ";
for (int n : data) cout << n << " ";
cout << endl;
set<int> uniqueSorted(data.begin(), data.end());
vector<int> result(uniqueSorted.begin(), uniqueSorted.end());
cout << "Deduplicated (sorted): ";
for (int n : result) cout << n << " ";
cout << endl;
// --- Deduplicate preserving INSERTION order ---
cout << "\n=== Deduplicate preserving insertion order ===" << endl;
vector<string> words = {"apple", "banana", "apple", "cherry",
"banana", "date", "apple"};
cout << "Original: ";
for (const string& w : words) cout << w << " ";
cout << endl;
unordered_set<string> seen;
vector<string> ordered;
for (const string& w : words) {
if (seen.insert(w).second) { // insert returns {it, bool}
ordered.push_back(w); // Only add if truly new
}
}
cout << "Deduplicated (insertion order): ";
for (const string& w : ordered) cout << w << " ";
cout << endl;
// --- Count unique elements quickly ---
cout << "\n=== Count unique elements ===" << endl;
vector<int> votes = {3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5};
int uniqueCount = set<int>(votes.begin(), votes.end()).size();
cout << "Votes: ";
for (int v : votes) cout << v << " ";
cout << endl;
cout << "Unique candidates: " << uniqueCount << endl;
// --- Check if two collections share any element ---
cout << "\n=== Intersection check ===" << endl;
vector<string> listA = {"cat", "dog", "bird"};
vector<string> listB = {"fish", "dog", "hamster"};
unordered_set<string> setA(listA.begin(), listA.end());
bool hasCommon = false;
for (const string& elem : listB) {
if (setA.count(elem)) {
cout << "Common element found: " << elem << endl;
hasCommon = true;
break;
}
}
if (!hasCommon) cout << "No common elements" << endl;
return 0;
}Step-by-step explanation:
- set<int>(data.begin(), data.end()): Converts vector to set — automatic deduplication and sorting
- vector<int>(uniqueSorted.begin(), uniqueSorted.end()): Converts back to vector
- Round-trip pattern: vector → set → vector is the standard sort+deduplicate idiom
- Sorted result: Set imposes ordering — output is 1 2 3 5 7 8 9
- Preserving insertion order: std::set sorts — need different approach for original order
- seen.insert(w).second: Accesses bool part of insert’s return pair — true if new
- if (seen.insert(w).second): Only add to
orderedwhen element is genuinely new - unordered_set for tracking: Fast O(1) membership check during iteration
- First “apple” inserted: seen.insert returns true → added to ordered
- Second “apple”: seen.insert returns false → NOT added to ordered
- Count unique in one line:
set<int>(votes.begin(), votes.end()).size()— construct temporary set - Temporary set: Created just to count unique elements — discarded immediately
- Intersection check pattern: Load A into set, iterate B checking membership
- O(n + m) total: O(n) to build set, O(m) to check each element of B
Output:
=== Deduplicate with sorted order ===
Original: 5 3 8 1 5 3 9 2 8 7 1
Deduplicated (sorted): 1 2 3 5 7 8 9
=== Deduplicate preserving insertion order ===
Original: apple banana apple cherry banana date apple
Deduplicated (insertion order): apple banana cherry date
=== Count unique elements ===
Votes: 3 1 4 1 5 9 2 6 5 3 5
Unique candidates: 8
=== Intersection check ===
Common element found: dogCustom Element Types in Sets
Using custom types as set elements requires providing a comparison or hash function.
#include <iostream>
#include <set>
#include <unordered_set>
#include <string>
using namespace std;
struct Student {
string name;
int id;
// Required for std::set: defines element ordering
bool operator<(const Student& other) const {
return id < other.id; // Order by student ID
}
// Required for unordered_set: equality check after hash
bool operator==(const Student& other) const {
return id == other.id;
}
};
// Custom hash for unordered_set<Student>
struct StudentHash {
size_t operator()(const Student& s) const {
return hash<int>()(s.id); // Hash by ID
}
};
int main() {
// --- std::set with custom type ---
cout << "=== std::set<Student> ===" << endl;
set<Student> studentSet;
studentSet.insert({"Alice", 103});
studentSet.insert({"Bob", 101});
studentSet.insert({"Charlie", 102});
studentSet.insert({"Alice", 103}); // Duplicate ID — rejected
cout << "Students (sorted by ID):" << endl;
for (const auto& s : studentSet) {
cout << " ID " << s.id << ": " << s.name << endl;
}
// --- std::unordered_set with custom type and hash ---
cout << "\n=== std::unordered_set<Student> ===" << endl;
unordered_set<Student, StudentHash> hashStudents;
hashStudents.insert({"Diana", 201});
hashStudents.insert({"Eve", 202});
hashStudents.insert({"Frank", 203});
hashStudents.insert({"Diana", 201}); // Duplicate — rejected
cout << "Students (unordered):" << endl;
for (const auto& s : hashStudents) {
cout << " ID " << s.id << ": " << s.name << endl;
}
// --- Lookup by custom type ---
cout << "\n=== Lookup ===" << endl;
Student lookup = {"Unknown", 102}; // Only ID matters for comparison
auto it = studentSet.find(lookup);
if (it != studentSet.end()) {
cout << "Found ID 102: " << it->name << endl;
}
return 0;
}Step-by-step explanation:
- operator< for set: Required — set uses
<to maintain sorted order - Sort by id: Students ordered by ID, not name
- operator== for unordered_set: Required — equality check after hash match
- StudentHash functor: struct with operator() returning size_t
- hash<int>()(s.id): Uses standard int hash on the student’s ID field
- Three template args for unordered_set: Element type, Hash type, Equality type
- Equality type defaults to operator==: Only need to specify Hash explicitly
- Duplicate insert with same ID: Both set and unordered_set reject {Alice, 103} second time
- set ordered by ID: 101, 102, 103 — insertion order irrelevant
- unordered_set no ordering: Hash buckets determine output order
- Lookup with partial match:
Student{"Unknown", 102}— only ID used for comparison - find() uses operator< tree traversal: Finds Charlie by ID 102, not by name
- it->name: Access the stored element’s name through the iterator
- Design principle: When IDs uniquely identify entities, use ID for hash and comparison
Output:
=== std::set<Student> ===
Students (sorted by ID):
ID 101: Bob
ID 102: Charlie
ID 103: Alice
=== std::unordered_set<Student> ===
Students (unordered):
ID 203: Frank
ID 201: Diana
ID 202: Eve
=== Lookup ===
Found ID 102: Charlieset vs unordered_set Comparison Table
| Feature | std::set | std::unordered_set |
|---|---|---|
| Internal structure | Red-black tree | Hash table |
| Element ordering | Sorted (ascending) | No ordering |
| Lookup | O(log n) | O(1) average |
| Insert | O(log n) | O(1) average |
| Erase | O(log n) | O(1) average |
| Iteration order | Sorted | Arbitrary |
| Range queries | Yes (lower/upper_bound) | No |
| Set algorithms | Yes (set_union etc.) | No |
| Memory | Node-per-element | Hash table overhead |
| Key requirement | operator< | hash + operator== |
| Worst-case | O(log n) guaranteed | O(n) on collision |
| Use when | Sorted iteration, range queries | Maximum lookup speed |
When to Choose Which
// Use std::set when:
// 1. You need sorted output
set<string> alphabeticalNames; // Iterate names A to Z
// 2. You need range queries
set<int> timestamps; // Find all events in a time range
// 3. You use set algorithms (union, intersection, difference)
set<int> A, B, C;
set_intersection(A.begin(), A.end(), B.begin(), B.end(),
inserter(C, C.begin()));
// 4. You need min/max fast
set<int> values;
int minimum = *values.begin();
int maximum = *values.rbegin();
// Use std::unordered_set when:
// 1. You need maximum lookup speed
unordered_set<string> blacklist; // High-frequency membership checks
// 2. Order doesn't matter
unordered_set<int> visitedNodes; // Graph traversal visited tracking
// 3. Large datasets where O(log n) vs O(1) matters
unordered_set<long long> seenIDs; // Millions of unique ID lookups
// 4. You're deduplicating without caring about order
unordered_set<string> unique(raw.begin(), raw.end());Conclusion: Mastering Unique-Element Containers
std::set and std::unordered_set are essential tools for any C++ programmer working with collections where uniqueness matters. They automate duplicate prevention, enable O(log n) or O(1) membership testing, and integrate seamlessly with the STL algorithm library for powerful mathematical set operations.
Key takeaways:
- Both containers guarantee element uniqueness — duplicates silently rejected on insertion
insert()returns{iterator, bool}— the bool tells you if the element was new or already existedstd::setsorts elements automatically, enabling ordered iteration, range queries, and set algorithmsstd::unordered_setuses a hash table for O(1) average lookup at the cost of orderingcount()andfind()are your primary membership-testing tools —count()for simple yes/no,find()when you need the iteratorlower_bound()andupper_bound()onstd::setenable powerful range queries- Set algorithms (
set_union,set_intersection,set_difference) work on any sorted ranges - Converting vector to set is the fastest way to deduplicate — and back to vector if you need random access
- Custom types need
operator<for set, and a hash functor +operator==for unordered_set - Use
reserve()on unordered_set to pre-allocate bucket capacity and avoid rehashing
Choose std::set when order and range queries matter. Choose std::unordered_set for maximum speed on pure membership tests. Either way, you’ll write cleaner, more correct code than manually managing uniqueness with vectors.