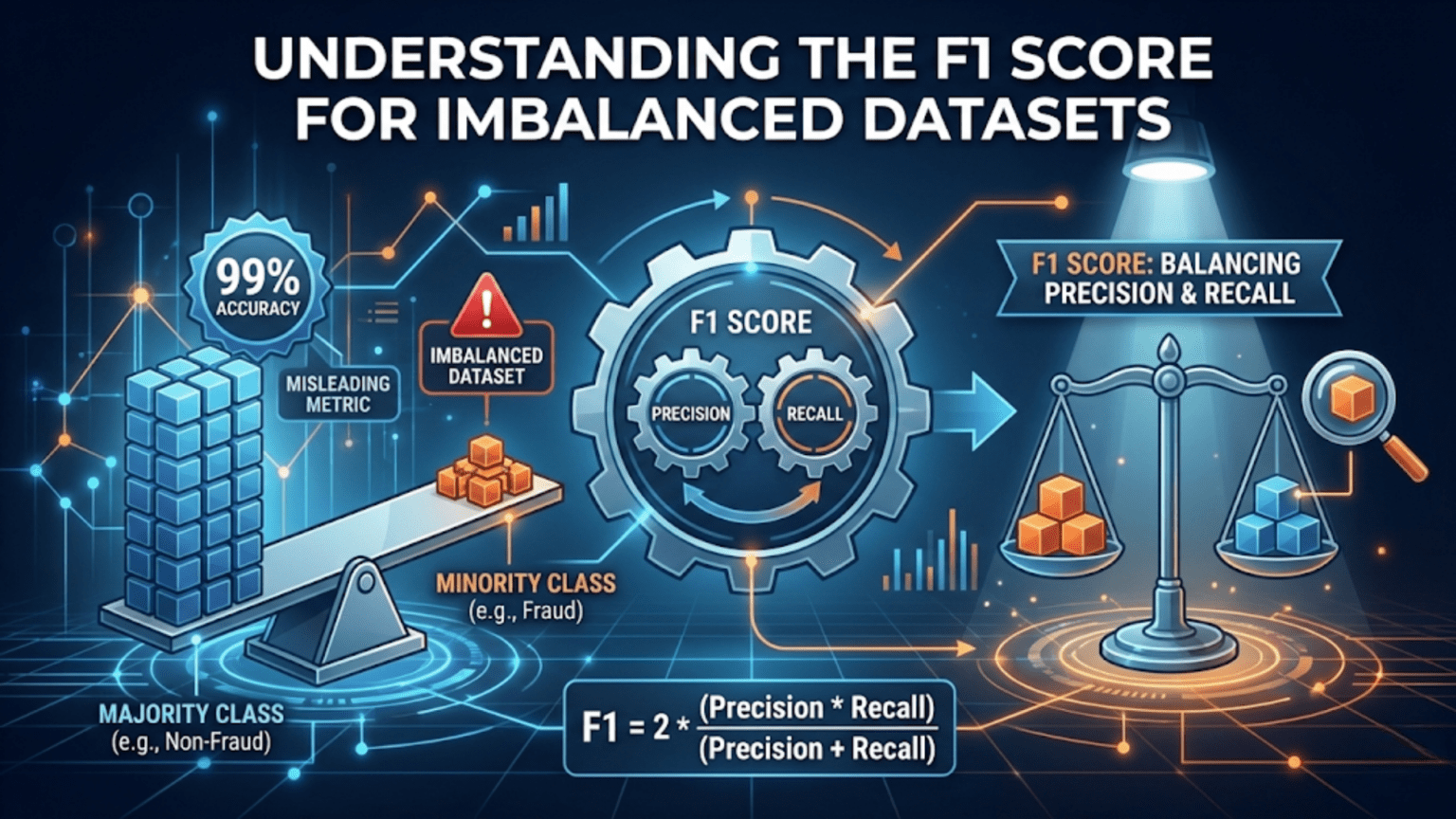
The F1 score is the harmonic mean of precision and recall, calculated as F1 = 2 × (Precision × Recall) / (Precision + Recall). It is the go-to evaluation metric for imbalanced datasets where one class significantly outnumbers another, because unlike accuracy it penalizes a model that simply predicts the majority class. A perfect F1 score is 1.0, and the worst possible is 0.0.
Introduction
In the previous article, we explored accuracy, precision, and recall as distinct metrics — each measuring a different aspect of a classifier’s behavior. We saw that accuracy can be deeply misleading when classes are imbalanced: a model that always predicts “not cancer” can score 99% accuracy on a dataset where only 1% of samples are cancer patients.
This article takes a deeper look at the F1 score: how it works, why it is specifically suited for imbalanced data, the mathematics behind the harmonic mean, and the variants you will encounter in multiclass and multi-label problems. We will also explore edge cases, common misunderstandings, and build a complete practical toolkit in Python.
By the end of this article, you will have the tools to confidently choose, compute, and interpret the F1 score — and its relatives — in any classification scenario you encounter.
What Is Class Imbalance and Why Does It Matter?
Before diving into the F1 score itself, let’s be precise about what “imbalanced” means and why it creates evaluation challenges.
Defining Class Imbalance
A dataset is class-imbalanced when one class (the majority class) has far more samples than another (the minority class). The severity of imbalance is typically expressed as a ratio:
- Mild imbalance: 70:30 or 80:20 ratio
- Moderate imbalance: 90:10 or 95:5 ratio
- Severe imbalance: 99:1 or greater
In practice, severe imbalance is common and often the norm in high-stakes applications:
| Domain | Typical Imbalance Ratio | Minority Class |
|---|---|---|
| Credit card fraud | 500:1 to 1000:1 | Fraudulent transactions |
| Medical diagnosis (rare disease) | 100:1 to 1000:1 | Positive diagnosis |
| Network intrusion detection | 100:1 to 10000:1 | Attack traffic |
| Manufacturing defect detection | 50:1 to 200:1 | Defective products |
| Email spam filtering | 10:1 to 50:1 | Spam emails |
| Cancer detection (screening) | 20:1 to 100:1 | Malignant cases |
In every one of these cases, the minority class is the one we care about most. A fraud detection system that catches zero fraudulent transactions is worse than useless — yet it could score 99.9% accuracy by predicting “not fraud” every single time.
The Accuracy Paradox
This failure of accuracy with imbalanced data has a name: the accuracy paradox. It occurs when a model achieves high accuracy not because it is genuinely good at classification, but because it has learned to exploit the class distribution by always predicting the majority class.
The accuracy paradox motivates the need for metrics that specifically account for how well the model performs on the minority class. The F1 score is the most widely used solution.
The F1 Score: Mathematics and Intuition
Revisiting Precision and Recall
The F1 score is built from two simpler metrics:
Precision answers: “Of everything I predicted as positive, how much was actually positive?”
Recall answers: “Of all the actual positives, how many did I find?”
Both metrics are needed because each can be trivially maximized at the expense of the other:
- A model that predicts “positive” for every single sample achieves perfect recall (1.0) but terrible precision.
- A model that predicts “positive” for only the single case it is absolutely certain about achieves perfect precision (1.0) but terrible recall.
The F1 score synthesizes both into a single number that requires a model to do well on both dimensions simultaneously.
The Harmonic Mean Formula
This can also be written directly from the confusion matrix components:
Notice what is absent from this formula: true negatives (TN). The F1 score completely ignores correct negative predictions. This is the key reason it is resistant to the accuracy paradox — a model that predicts “not fraud” for every transaction has TP = 0, making F1 = 0 regardless of how many true negatives it accumulates.
Why Harmonic Mean, Not Arithmetic Mean?
The choice of harmonic mean over arithmetic mean is deliberate and important. Let’s examine why with a concrete example.
Suppose two models produce the following results on a fraud detection task:
| Model | Precision | Recall | Arithmetic Mean | F1 (Harmonic Mean) |
|---|---|---|---|---|
| Model A | 0.90 | 0.90 | 0.90 | 0.90 |
| Model B | 1.00 | 0.50 | 0.75 | 0.67 |
| Model C | 0.01 | 1.00 | 0.505 | 0.020 |
Model B has perfect precision but catches only half of all fraud cases. Model C catches every fraud case but produces an overwhelming number of false alarms — predicting “fraud” for nearly everything.
The arithmetic mean rates Model C as nearly as good as Model A (0.505 vs 0.90), which misrepresents reality. The harmonic mean (F1) correctly reveals that Model C (F1 = 0.020) is essentially useless despite its perfect recall, because flooding the fraud team with 99 false positives for every real case of fraud is not a workable solution.
The harmonic mean punishes extreme imbalance between precision and recall. A high F1 score requires both to be reasonably good — it cannot be inflated by excelling at one while failing at the other.
Mathematical Properties
The harmonic mean has a special property: it is always less than or equal to the arithmetic mean, and the gap between them grows as the difference between precision and recall grows.
For equal precision and recall (P = R = x), the F1 score equals x. As the gap between P and R widens, F1 drops further below the arithmetic mean. The maximum F1 of 1.0 is achieved only when both precision and recall equal 1.0. The minimum F1 of 0.0 occurs when either precision or recall equals 0.0.
Computing F1: From Scratch and with Scikit-learn
Manual Implementation
def compute_f1(y_true, y_pred):
"""
Compute F1 score manually from true and predicted binary labels.
Shows the step-by-step calculation for educational transparency.
Args:
y_true: List or array of true labels (1=positive, 0=negative)
y_pred: List or array of predicted labels (1=positive, 0=negative)
Returns:
Dictionary with all intermediate values and F1 score
"""
# Step 1: Count confusion matrix values
TP = sum(1 for t, p in zip(y_true, y_pred) if t == 1 and p == 1)
FP = sum(1 for t, p in zip(y_true, y_pred) if t == 0 and p == 1)
FN = sum(1 for t, p in zip(y_true, y_pred) if t == 1 and p == 0)
TN = sum(1 for t, p in zip(y_true, y_pred) if t == 0 and p == 0)
# Step 2: Compute precision (guard against division by zero)
precision = TP / (TP + FP) if (TP + FP) > 0 else 0.0
# Step 3: Compute recall (guard against division by zero)
recall = TP / (TP + FN) if (TP + FN) > 0 else 0.0
# Step 4: Compute F1 as harmonic mean
f1 = (2 * precision * recall) / (precision + recall) if (precision + recall) > 0 else 0.0
# Alternative: direct formula from confusion matrix
f1_direct = (2 * TP) / (2 * TP + FP + FN) if (2 * TP + FP + FN) > 0 else 0.0
return {
"TP": TP, "FP": FP, "FN": FN, "TN": TN,
"precision": round(precision, 4),
"recall": round(recall, 4),
"f1": round(f1, 4),
"f1_direct": round(f1_direct, 4)
}
# Example 1: A balanced model
print("=== Balanced Model ===")
y_true = [1, 1, 1, 1, 1, 0, 0, 0, 0, 0]
y_pred = [1, 1, 1, 1, 0, 0, 0, 0, 0, 1] # 1 FP, 1 FN
result = compute_f1(y_true, y_pred)
print(f"Precision: {result['precision']}, Recall: {result['recall']}, F1: {result['f1']}")
# Example 2: The accuracy paradox — model always predicts majority class
print("\n=== Always-Negative Model (Accuracy Paradox) ===")
# 95 negatives, 5 positives (5% positive class)
y_true_imbalanced = [0]*95 + [1]*5
y_pred_all_negative = [0]*100 # Always predict negative
result_naive = compute_f1(y_true_imbalanced, y_pred_all_negative)
# Calculate accuracy manually for comparison
accuracy = sum(t == p for t, p in zip(y_true_imbalanced, y_pred_all_negative)) / len(y_true_imbalanced)
print(f"Accuracy: {accuracy:.4f} ← Looks great!")
print(f"F1 Score: {result_naive['f1']:.4f} ← Reveals the truth")
print(f"Precision: {result_naive['precision']}, Recall: {result_naive['recall']}")
# Example 3: A genuinely useful model on the same imbalanced data
print("\n=== Useful Model on Imbalanced Data ===")
y_pred_useful = [0]*90 + [1]*5 + [1]*4 + [0]*1 # Catches 4/5 positives, 5 false positives
# Rebuild with correct structure
y_true_imbalanced2 = [0]*95 + [1]*5
y_pred_useful2 = [0]*91 + [1]*4 + [1]*4 + [0]*1
# Simpler construction for clarity:
y_true3 = [0]*95 + [1]*5
y_pred3 = [0]*90 + [1]*5 + [1]*4 + [0]*1
result_useful = compute_f1(y_true3, y_pred3)
accuracy_useful = sum(t == p for t, p in zip(y_true3, y_pred3)) / len(y_true3)
print(f"Accuracy: {accuracy_useful:.4f} ← Slightly lower than naive!")
print(f"F1 Score: {result_useful['f1']:.4f} ← Much better than naive")
print(f"TP={result_useful['TP']}, FP={result_useful['FP']}, FN={result_useful['FN']}, TN={result_useful['TN']}")This example reveals the core insight: the naive model scores 95% accuracy but F1 of 0.0. The useful model scores slightly lower accuracy (because it generates some false positives) but a dramatically better F1 score because it actually catches real positive cases.
Using Scikit-learn
from sklearn.metrics import f1_score, classification_report, precision_recall_fscore_support
import numpy as np
# Imbalanced dataset: 95 negatives, 5 positives
y_true = np.array([0]*95 + [1]*5)
# Three different models
y_pred_naive = np.array([0]*100) # Always predicts negative
y_pred_overfit = np.array([1]*100) # Always predicts positive
y_pred_good = np.array([0]*91 + [1]*4 + [1]*4 + [0]*1) # Actually useful
models = {
"Always Negative (naive)": y_pred_naive,
"Always Positive (overfit)": y_pred_overfit,
"Reasonable Model": np.array([0]*93 + [1]*2 + [1]*4 + [0]*1)
}
print(f"{'Model':<30} | {'Accuracy':>9} | {'Precision':>10} | {'Recall':>7} | {'F1':>7}")
print("-" * 75)
for name, y_pred in models.items():
acc = np.mean(y_true == y_pred)
# zero_division=0 handles edge cases where denominator is zero
prec = f1_score(y_true, y_pred, pos_label=1, zero_division=0,
average=None)[1] if hasattr(f1_score(y_true, y_pred, average=None), '__len__') else 0
from sklearn.metrics import precision_score, recall_score
p = precision_score(y_true, y_pred, zero_division=0)
r = recall_score(y_true, y_pred, zero_division=0)
f = f1_score(y_true, y_pred, zero_division=0)
print(f"{name:<30} | {acc:>9.4f} | {p:>10.4f} | {r:>7.4f} | {f:>7.4f}")F1 Score Variants for Different Scenarios
The basic F1 score described so far applies to binary classification. Real-world problems often require extensions.
Binary F1 Score
The standard case: one positive class, one negative class. This is what we have discussed so far.
from sklearn.metrics import f1_score
y_true = [1, 0, 1, 1, 0, 1, 0, 0, 1, 0]
y_pred = [1, 0, 1, 0, 0, 1, 1, 0, 1, 0]
# Binary F1 — scores the positive class (label=1 by default)
binary_f1 = f1_score(y_true, y_pred)
print(f"Binary F1: {binary_f1:.4f}")Macro F1
Macro F1 calculates the F1 score independently for each class, then takes the simple (unweighted) arithmetic average.
Use macro F1 when you want to treat all classes equally, regardless of how many samples each has. This is appropriate when every class is equally important to the business, even rare ones.
Beware: macro F1 is heavily influenced by poor performance on small classes. A single rare class with F1 = 0 can drag down an otherwise excellent macro F1 score.
Weighted F1
Weighted F1 calculates F1 for each class, then takes a weighted average based on each class’s share of total samples (its support).
Use weighted F1 when class frequency should influence the overall score — essentially, larger classes count more. This is the most commonly reported single F1 metric in practice because it aligns with the distribution of the actual data.
Micro F1
Micro F1 aggregates all true positives, false positives, and false negatives globally across all classes, then computes a single F1 from those totals.
For multi-class single-label classification (each sample belongs to exactly one class), micro F1 equals accuracy. Use micro F1 when you care about per-sample correctness and want to reflect the performance on frequent classes most heavily.
Comparing All Variants
from sklearn.metrics import f1_score, classification_report
import numpy as np
# Multi-class example with class imbalance
# Class 0: 70 samples, Class 1: 20 samples, Class 2: 10 samples
np.random.seed(42)
y_true = np.array([0]*70 + [1]*20 + [2]*10)
# Simulate a model that performs well on class 0,
# moderately on class 1, and poorly on class 2
y_pred = np.array(
[0]*65 + [1]*5 + # class 0: 65 correct, 5 wrong (predicted 1)
[1]*15 + [0]*5 + # class 1: 15 correct, 5 wrong (predicted 0)
[2]*5 + [0]*5 # class 2: 5 correct, 5 wrong (predicted 0)
)
print("=== F1 Score Variants Comparison ===\n")
print(f"Macro F1 (equal class weight): {f1_score(y_true, y_pred, average='macro'):.4f}")
print(f"Weighted F1 (frequency-weighted): {f1_score(y_true, y_pred, average='weighted'):.4f}")
print(f"Micro F1 (global aggregation): {f1_score(y_true, y_pred, average='micro'):.4f}")
print("\n=== Per-Class F1 Scores ===")
per_class_f1 = f1_score(y_true, y_pred, average=None)
for i, score in enumerate(per_class_f1):
count = (y_true == i).sum()
print(f" Class {i} (n={count:3d}): F1 = {score:.4f}")
print("\n=== Full Classification Report ===")
print(classification_report(y_true, y_pred, target_names=["Class 0", "Class 1", "Class 2"]))Run this code and observe how the three averages differ. Class 2 has very poor F1 (0.5), but weighted F1 barely registers its poor performance because it has only 10 samples. Macro F1 is dragged down significantly. This is the tradeoff you’re choosing between when you select an averaging strategy.
The Fbeta Score: Adjusting the Precision-Recall Balance
The F1 score weights precision and recall equally. But in many real-world problems, one type of error is more costly than the other. The Fbeta score generalizes the F1 score by introducing a parameter beta (β) that controls the weighting.
Formula
Interpreting Beta
- β = 1: Equal weight to precision and recall. This is the standard F1 score.
- β > 1: Recall is weighted more heavily than precision (β² times more). Used when missing a real positive (false negative) is more costly.
- β < 1: Precision is weighted more heavily than recall. Used when a false alarm (false positive) is more costly.
Common values you will encounter in practice:
| Beta Value | Interpretation | Typical Use Case |
|---|---|---|
| β = 0.5 | Precision weighted 4× more than recall | Spam filtering, recommendation systems |
| β = 1.0 | Equal weight (standard F1) | General imbalanced classification |
| β = 2.0 | Recall weighted 4× more than precision | Disease screening, fraud detection |
| β = 3.0 | Recall weighted 9× more than precision | Critical safety systems |
Python Implementation
from sklearn.metrics import fbeta_score
import numpy as np
# Simulate a fraud detection scenario
# 1000 transactions: 990 legitimate (0), 10 fraudulent (1)
np.random.seed(42)
y_true = np.array([0]*990 + [1]*10)
# Model predictions: catches 8 of 10 frauds, 15 false positives
y_pred = np.array([0]*975 + [1]*15 + [1]*8 + [0]*2)
print("=== Fbeta Score Comparison ===\n")
print(f"{'Metric':<20} | {'Score':>8} | Description")
print("-" * 60)
metrics = [
("F0.5 (precision++)", fbeta_score(y_true, y_pred, beta=0.5, zero_division=0)),
("F1.0 (balanced)", fbeta_score(y_true, y_pred, beta=1.0, zero_division=0)),
("F2.0 (recall++)", fbeta_score(y_true, y_pred, beta=2.0, zero_division=0)),
("F3.0 (recall+++)", fbeta_score(y_true, y_pred, beta=3.0, zero_division=0)),
]
descriptions = [
"Penalizes false alarms heavily",
"Equally penalizes both error types",
"Penalizes missed fraud heavily",
"Extreme penalty for missed fraud"
]
for (name, score), desc in zip(metrics, descriptions):
print(f"{name:<20} | {score:>8.4f} | {desc}")
print("\n=== When Each Beta Makes Sense ===")
print("Fraud detection: F2 or F3 (missing fraud is expensive)")
print("Spam filtering: F0.5 (blocking real emails is annoying)")
print("Disease screening: F2 or F3 (missing disease is dangerous)")
print("Search ranking: F0.5 (irrelevant results frustrate users)")How to Choose Beta
The most principled way to choose beta is through cost-benefit analysis:
- Estimate the cost of a false negative (C_FN) — the harm of missing a real positive
- Estimate the cost of a false positive (C_FP) — the harm of raising a false alarm
- Set beta = sqrt(C_FN / C_FP)
For example, if missing a fraud case costs your company $500 on average, and a false positive costs $5 in customer service time, then beta = sqrt(500/5) = sqrt(100) = 10. Use F10 as your metric.
Handling Imbalanced Data: Strategies That Work With F1
Choosing the F1 score as your metric is the first step. But you also want to build a model that actually achieves a good F1 score on imbalanced data. Here are the most effective strategies.
Strategy 1: Threshold Adjustment
The simplest approach. Instead of using the default 0.5 threshold, find the threshold that maximizes F1 on your validation set.
from sklearn.metrics import f1_score, precision_recall_curve
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
import numpy as np
# Create imbalanced dataset
X, y = make_classification(
n_samples=5000,
n_features=20,
n_informative=10,
weights=[0.95, 0.05], # 95% negative, 5% positive
random_state=42
)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=42, stratify=y
)
# Train model
model = LogisticRegression(random_state=42, max_iter=1000)
model.fit(X_train, y_train)
# Get predicted probabilities
y_proba = model.predict_proba(X_test)[:, 1]
# Find the optimal threshold for F1
precisions, recalls, thresholds = precision_recall_curve(y_test, y_proba)
# Calculate F1 at each threshold
f1_scores = 2 * precisions[:-1] * recalls[:-1] / (precisions[:-1] + recalls[:-1] + 1e-10)
best_idx = np.argmax(f1_scores)
best_threshold = thresholds[best_idx]
best_f1 = f1_scores[best_idx]
print("=== Threshold Optimization for F1 ===\n")
print(f"Default threshold (0.5):")
y_pred_default = (y_proba >= 0.5).astype(int)
print(f" F1 Score: {f1_score(y_test, y_pred_default, zero_division=0):.4f}")
print(f"\nOptimal threshold ({best_threshold:.3f}):")
y_pred_optimal = (y_proba >= best_threshold).astype(int)
print(f" F1 Score: {f1_score(y_test, y_pred_optimal, zero_division=0):.4f}")
print(f" Improvement: +{(f1_score(y_test, y_pred_optimal, zero_division=0) - f1_score(y_test, y_pred_default, zero_division=0)):.4f}")
# Show the F1-maximizing threshold visually
import matplotlib.pyplot as plt
plt.figure(figsize=(10, 4))
plt.plot(thresholds, f1_scores, 'b-', linewidth=2, label='F1 Score')
plt.axvline(x=best_threshold, color='r', linestyle='--',
label=f'Optimal threshold: {best_threshold:.3f}')
plt.axvline(x=0.5, color='gray', linestyle=':', alpha=0.7, label='Default threshold: 0.5')
plt.xlabel("Decision Threshold")
plt.ylabel("F1 Score")
plt.title("F1 Score vs Decision Threshold")
plt.legend()
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.savefig("f1_threshold_optimization.png", dpi=150)
plt.show()
print("\nPlot saved as 'f1_threshold_optimization.png'")Strategy 2: Class Weights
Most scikit-learn classifiers accept a class_weight parameter. Setting this to 'balanced' automatically adjusts the weight of each class inversely proportional to its frequency, causing the model to pay more attention to the minority class during training.
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import f1_score
# Compare models with and without class weighting
models_to_compare = {
"Logistic Regression (default)": LogisticRegression(random_state=42, max_iter=1000),
"Logistic Regression (balanced)": LogisticRegression(class_weight='balanced', random_state=42, max_iter=1000),
"Random Forest (default)": RandomForestClassifier(n_estimators=100, random_state=42),
"Random Forest (balanced)": RandomForestClassifier(n_estimators=100, class_weight='balanced', random_state=42),
}
print(f"{'Model':<40} | {'F1 Score':>10}")
print("-" * 55)
for name, clf in models_to_compare.items():
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
f1 = f1_score(y_test, y_pred, zero_division=0)
print(f"{name:<40} | {f1:>10.4f}")Strategy 3: Resampling Techniques
Resampling modifies the training data itself to create a more balanced distribution before training.
Oversampling creates additional examples of the minority class. The most sophisticated version is SMOTE (Synthetic Minority Over-sampling Technique), which generates new synthetic samples along the line segments between existing minority class samples.
Undersampling removes examples from the majority class to reduce imbalance.
# Install imbalanced-learn if needed: pip install imbalanced-learn
from imblearn.over_sampling import SMOTE
from imblearn.under_sampling import RandomUnderSampler
from imblearn.pipeline import Pipeline as ImbPipeline
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import f1_score, classification_report
# Check class distribution before resampling
print(f"Before resampling:")
print(f" Class 0 (negative): {(y_train == 0).sum()}")
print(f" Class 1 (positive): {(y_train == 1).sum()}")
print(f" Ratio: {(y_train == 0).sum() / (y_train == 1).sum():.1f}:1")
# SMOTE oversampling
smote = SMOTE(random_state=42)
X_resampled, y_resampled = smote.fit_resample(X_train, y_train)
print(f"\nAfter SMOTE oversampling:")
print(f" Class 0 (negative): {(y_resampled == 0).sum()}")
print(f" Class 1 (positive): {(y_resampled == 1).sum()}")
# Train on resampled data
model_smote = LogisticRegression(random_state=42, max_iter=1000)
model_smote.fit(X_resampled, y_resampled)
y_pred_smote = model_smote.predict(X_test)
# Train on original data
model_original = LogisticRegression(random_state=42, max_iter=1000)
model_original.fit(X_train, y_train)
y_pred_original = model_original.predict(X_test)
print(f"\n=== F1 Score Comparison ===")
print(f"Without SMOTE: {f1_score(y_test, y_pred_original, zero_division=0):.4f}")
print(f"With SMOTE: {f1_score(y_test, y_pred_smote, zero_division=0):.4f}")
# Using imbalanced-learn pipeline for clean integration
pipeline = ImbPipeline([
('smote', SMOTE(random_state=42)),
('classifier', LogisticRegression(random_state=42, max_iter=1000))
])
pipeline.fit(X_train, y_train)
y_pred_pipeline = pipeline.predict(X_test)
print(f"With SMOTE Pipeline: {f1_score(y_test, y_pred_pipeline, zero_division=0):.4f}")Strategy 4: Algorithm Selection
Some algorithms are more naturally robust to class imbalance than others. Ensemble methods like Random Forest, XGBoost, and LightGBM often handle imbalance better than logistic regression out of the box, especially with the scale_pos_weight parameter available in gradient boosting libraries.
from xgboost import XGBClassifier
from sklearn.metrics import f1_score
# Calculate the ratio of negative to positive samples
neg_to_pos_ratio = (y_train == 0).sum() / (y_train == 1).sum()
print(f"Negative to positive ratio: {neg_to_pos_ratio:.1f}")
# XGBoost with scale_pos_weight handles imbalance internally
xgb_model = XGBClassifier(
scale_pos_weight=neg_to_pos_ratio, # Tells XGBoost to weight positives more
random_state=42,
eval_metric='logloss',
verbosity=0
)
xgb_model.fit(X_train, y_train)
y_pred_xgb = xgb_model.predict(X_test)
print(f"XGBoost F1 Score: {f1_score(y_test, y_pred_xgb, zero_division=0):.4f}")Cross-Validating F1 Score for Reliable Estimates
A single train-test split can give misleading results, especially on small or imbalanced datasets. Cross-validation with stratified folds gives a more reliable estimate of your model’s true F1 performance.
Stratified k-fold is critical for imbalanced data: it ensures each fold maintains the same class ratio as the full dataset, preventing folds where the minority class has no representation.
from sklearn.model_selection import StratifiedKFold, cross_val_score
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import make_scorer, f1_score
import numpy as np
# Create F1 scorer
f1_scorer = make_scorer(f1_score, zero_division=0)
# Stratified K-Fold cross-validation
skf = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)
model = LogisticRegression(class_weight='balanced', random_state=42, max_iter=1000)
# Cross-validate with F1 scoring
cv_scores = cross_val_score(model, X, y, cv=skf, scoring=f1_scorer)
print("=== Stratified 5-Fold Cross-Validation (F1 Score) ===\n")
for i, score in enumerate(cv_scores, 1):
print(f" Fold {i}: {score:.4f}")
print(f"\n Mean F1: {cv_scores.mean():.4f}")
print(f" Std Dev: {cv_scores.std():.4f}")
print(f" 95% CI: [{cv_scores.mean() - 2*cv_scores.std():.4f}, "
f"{cv_scores.mean() + 2*cv_scores.std():.4f}]")
# Compare multiple models with cross-validated F1
models = {
"Logistic Regression": LogisticRegression(random_state=42, max_iter=1000),
"LR (class_weight=balanced)": LogisticRegression(class_weight='balanced',
random_state=42, max_iter=1000),
"Random Forest": RandomForestClassifier(n_estimators=100, random_state=42),
"RF (class_weight=balanced)": RandomForestClassifier(n_estimators=100,
class_weight='balanced',
random_state=42),
}
print("\n=== Model Comparison via Cross-Validated F1 ===\n")
print(f"{'Model':<35} | {'Mean F1':>8} | {'Std Dev':>8}")
print("-" * 58)
for name, clf in models.items():
scores = cross_val_score(clf, X, y, cv=skf, scoring=f1_scorer)
print(f"{name:<35} | {scores.mean():>8.4f} | {scores.std():>8.4f}")Stratified cross-validation is the gold standard for evaluating models on imbalanced data. The mean F1 across folds is a far more trustworthy estimate than a single F1 on one held-out set.
Visualizing F1 Performance
Visual tools help communicate model performance to both technical and non-technical stakeholders.
import matplotlib.pyplot as plt
import matplotlib.gridspec as gridspec
import numpy as np
from sklearn.metrics import (
precision_recall_curve, f1_score,
precision_score, recall_score, confusion_matrix
)
import seaborn as sns
def plot_complete_f1_analysis(y_true, y_proba, model_name="Model"):
"""
Create a comprehensive 4-panel visualization of F1 performance.
Panels:
1. Precision-Recall curve with F1 contours
2. F1 score vs threshold
3. Confusion matrix at optimal threshold
4. Precision, Recall, F1 bar chart at different thresholds
"""
# Calculate precision-recall curve
precisions, recalls, thresholds = precision_recall_curve(y_true, y_proba)
f1_scores = (2 * precisions[:-1] * recalls[:-1] /
(precisions[:-1] + recalls[:-1] + 1e-10))
best_idx = np.argmax(f1_scores)
best_threshold = thresholds[best_idx]
y_pred_optimal = (y_proba >= best_threshold).astype(int)
y_pred_default = (y_proba >= 0.5).astype(int)
fig = plt.figure(figsize=(16, 12))
gs = gridspec.GridSpec(2, 2, figure=fig, hspace=0.4, wspace=0.35)
# Panel 1: Precision-Recall Curve
ax1 = fig.add_subplot(gs[0, 0])
ax1.plot(recalls, precisions, 'b-', linewidth=2.5, label='PR Curve')
ax1.scatter(recalls[best_idx], precisions[best_idx],
color='red', s=150, zorder=5, label=f'Best F1 ({f1_scores[best_idx]:.3f})')
ax1.set_xlabel("Recall", fontsize=12)
ax1.set_ylabel("Precision", fontsize=12)
ax1.set_title("Precision-Recall Curve", fontsize=13, fontweight='bold')
ax1.legend(fontsize=10)
ax1.grid(True, alpha=0.3)
ax1.set_xlim([0, 1])
ax1.set_ylim([0, 1.05])
# Panel 2: F1 vs Threshold
ax2 = fig.add_subplot(gs[0, 1])
ax2.plot(thresholds, f1_scores, 'g-', linewidth=2.5, label='F1 Score')
ax2.axvline(x=best_threshold, color='red', linestyle='--',
label=f'Optimal: {best_threshold:.3f}')
ax2.axvline(x=0.5, color='gray', linestyle=':', alpha=0.7,
label='Default: 0.5')
ax2.set_xlabel("Decision Threshold", fontsize=12)
ax2.set_ylabel("F1 Score", fontsize=12)
ax2.set_title("F1 Score vs Threshold", fontsize=13, fontweight='bold')
ax2.legend(fontsize=10)
ax2.grid(True, alpha=0.3)
# Panel 3: Confusion Matrix at Optimal Threshold
ax3 = fig.add_subplot(gs[1, 0])
cm = confusion_matrix(y_true, y_pred_optimal)
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues', ax=ax3,
xticklabels=['Pred Neg', 'Pred Pos'],
yticklabels=['True Neg', 'True Pos'])
ax3.set_title(f"Confusion Matrix\n(threshold={best_threshold:.3f})",
fontsize=13, fontweight='bold')
# Panel 4: Metrics at Different Thresholds
ax4 = fig.add_subplot(gs[1, 1])
threshold_points = [0.2, 0.3, 0.4, 0.5, best_threshold, 0.6, 0.7, 0.8]
threshold_points = sorted(set(threshold_points))
t_prec, t_rec, t_f1 = [], [], []
for t in threshold_points:
yp = (y_proba >= t).astype(int)
t_prec.append(precision_score(y_true, yp, zero_division=0))
t_rec.append(recall_score(y_true, yp, zero_division=0))
t_f1.append(f1_score(y_true, yp, zero_division=0))
x_pos = range(len(threshold_points))
width = 0.25
ax4.bar([x - width for x in x_pos], t_prec, width, label='Precision', color='steelblue', alpha=0.8)
ax4.bar(list(x_pos), t_rec, width, label='Recall', color='coral', alpha=0.8)
ax4.bar([x + width for x in x_pos], t_f1, width, label='F1', color='mediumseagreen', alpha=0.8)
ax4.set_xticks(list(x_pos))
ax4.set_xticklabels([f"{t:.2f}" for t in threshold_points], rotation=45)
ax4.set_xlabel("Threshold", fontsize=12)
ax4.set_ylabel("Score", fontsize=12)
ax4.set_title("Metrics at Different Thresholds", fontsize=13, fontweight='bold')
ax4.legend(fontsize=10)
ax4.grid(True, alpha=0.3, axis='y')
ax4.set_ylim([0, 1.1])
fig.suptitle(f"F1 Score Analysis: {model_name}", fontsize=15, fontweight='bold', y=1.01)
plt.savefig("f1_complete_analysis.png", dpi=150, bbox_inches='tight')
plt.show()
print(f"\nSaved: 'f1_complete_analysis.png'")
# Print summary
print(f"\n{'='*45}")
print(f" Summary: {model_name}")
print(f"{'='*45}")
print(f" Optimal threshold: {best_threshold:.4f}")
print(f" Best F1: {f1_scores[best_idx]:.4f}")
print(f" At default (0.5):")
print(f" F1: {f1_score(y_true, y_pred_default, zero_division=0):.4f}")
print(f" Precision: {precision_score(y_true, y_pred_default, zero_division=0):.4f}")
print(f" Recall: {recall_score(y_true, y_pred_default, zero_division=0):.4f}")
# Apply our visualization
from sklearn.linear_model import LogisticRegression
model = LogisticRegression(class_weight='balanced', random_state=42, max_iter=1000)
model.fit(X_train, y_train)
y_proba_test = model.predict_proba(X_test)[:, 1]
plot_complete_f1_analysis(y_test, y_proba_test, "Logistic Regression (class_weight=balanced)")This four-panel visualization gives a complete picture of model behavior: where it sits on the precision-recall curve, how F1 changes with the threshold, what the optimal confusion matrix looks like, and how all three metrics respond across a range of thresholds.
Common Mistakes and How to Avoid Them
Mistake 1: Using F1 on balanced datasets without checking F1 is designed for imbalanced data. On a perfectly balanced dataset, F1 and accuracy tell a very similar story. Routinely using F1 everywhere is not harmful, but it adds complexity without benefit when classes are balanced.
Fix: Always check class distribution first. If the minority class represents less than 30% of samples, lean toward F1. If classes are roughly balanced, accuracy is intuitive and sufficient.
Mistake 2: Forgetting to specify zero_division in scikit-learn When a model predicts no positive samples (TP + FP = 0), precision is undefined. Scikit-learn defaults to issuing a warning and returning 0. In automated pipelines, these warnings can pile up silently.
Fix: Always explicitly set zero_division=0 (or zero_division=1 in cases where you want a different behavior) in all sklearn metric calls.
Mistake 3: Choosing the wrong averaging strategy Using macro F1 on a highly imbalanced multiclass problem treats a 5-sample class identically to a 5,000-sample class. Using weighted F1 on a problem where all classes are equally important ignores rare-but-important classes.
Fix: Match averaging to business intent. Equal importance across all classes → macro. Frequency-weighted importance → weighted. Per-sample correctness → micro. When in doubt, report all three alongside per-class scores.
Mistake 4: Not using stratified cross-validation Regular k-fold cross-validation can create folds with zero or very few minority class examples, causing wildly variable F1 scores across folds.
Fix: Always use StratifiedKFold when your dataset is imbalanced. This is so important that scikit-learn’s cross_val_score actually applies stratification automatically for classifiers, but it’s good practice to set it explicitly.
Mistake 5: Optimizing threshold on the test set Finding the threshold that maximizes F1 on the test set and then reporting that F1 leads to overly optimistic estimates. The test set should be touched only once, for final evaluation.
Fix: Find the optimal threshold on the validation set (or via cross-validation), then apply that threshold when evaluating on the held-out test set.
Mistake 6: Treating F1 as the only possible metric for imbalanced data F1 is excellent, but it’s not the only option. For some problems, AUC-PR (area under the precision-recall curve) or the Matthews Correlation Coefficient (MCC) may be better suited.
Fix: Consider AUC-PR when you want a threshold-independent metric. Consider MCC when you want a metric that considers all four confusion matrix cells (including true negatives), which F1 ignores.
F1 Score vs Other Metrics for Imbalanced Data
It helps to understand how F1 compares to other metrics used in imbalanced settings.
| Metric | Considers TN? | Threshold-Free? | Best For |
|---|---|---|---|
| Accuracy | Yes | Yes (binary labels) | Balanced datasets only |
| F1 Score | No | No (needs threshold) | Standard imbalanced classification |
| AUC-ROC | Yes (via FPR) | Yes | Comparing models, balanced-ish data |
| AUC-PR | No | Yes | Comparing models, heavily imbalanced data |
| MCC | Yes | No | Comprehensive single metric |
| Balanced Accuracy | Yes | No | Multiclass imbalanced, when TN matters |
The Matthews Correlation Coefficient (MCC) is worth special mention. It is calculated as:
MCC ranges from -1 (perfectly wrong) to +1 (perfectly correct), with 0 representing a random classifier. Unlike F1, it considers all four cells of the confusion matrix and is considered more informative for binary classification on imbalanced data by some researchers.
from sklearn.metrics import matthews_corrcoef, balanced_accuracy_score
# Compare F1 and MCC on our imbalanced dataset
model_balanced = LogisticRegression(class_weight='balanced', random_state=42, max_iter=1000)
model_balanced.fit(X_train, y_train)
y_pred_bal = model_balanced.predict(X_test)
print("=== F1 vs MCC vs Balanced Accuracy ===\n")
print(f"F1 Score: {f1_score(y_test, y_pred_bal, zero_division=0):.4f}")
print(f"MCC: {matthews_corrcoef(y_test, y_pred_bal):.4f}")
print(f"Balanced Accuracy: {balanced_accuracy_score(y_test, y_pred_bal):.4f}")
print(f"Regular Accuracy: {np.mean(y_test == y_pred_bal):.4f}")Interpreting F1 Scores in Context
A common beginner question is: “Is my F1 score good?” The answer, frustratingly, is: it depends entirely on the problem.
There is no universal threshold for “good” F1. Instead, you should interpret F1 scores relative to three baselines:
Baseline 1: The trivial classifier What F1 does a model get that always predicts the majority class? For imbalanced data, this is always 0.0. If your model achieves F1 = 0.05, it is at least better than doing nothing.
Baseline 2: A simple heuristic What would a simple rule-based system achieve? For spam detection, a keyword filter might achieve F1 = 0.6. Your machine learning model should meaningfully exceed this.
Baseline 3: Prior work or domain benchmarks What have published papers or previous models in your domain achieved? If fraud detection systems typically achieve F1 = 0.85 on similar datasets, an F1 of 0.60 should prompt investigation.
General rough guidelines (not universal rules):
| F1 Range | General Interpretation |
|---|---|
| 0.0 – 0.4 | Poor. Similar to naive baselines or barely better |
| 0.4 – 0.6 | Moderate. Better than trivial but room for improvement |
| 0.6 – 0.8 | Good. Useful for many real-world applications |
| 0.8 – 0.9 | Very good. Solid production-quality performance |
| 0.9 – 1.0 | Excellent. Approach with suspicion — check for data leakage |
An F1 of 0.99 sounds amazing, but on imbalanced data with 99% negative class, even a near-random model might accidentally achieve this. Always sanity-check very high scores.
Complete End-to-End Example: Fraud Detection
Let’s tie everything together with a realistic fraud detection pipeline that applies all the concepts from this article.
import numpy as np
import pandas as pd
from sklearn.datasets import make_classification
from sklearn.model_selection import StratifiedKFold, train_test_split, cross_val_score
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import (
f1_score, precision_score, recall_score,
accuracy_score, classification_report,
precision_recall_curve, average_precision_score
)
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import Pipeline
from sklearn.metrics import make_scorer
import warnings
warnings.filterwarnings('ignore')
# -------------------------------------------------------
# 1. Generate Realistic Fraud Detection Dataset
# -------------------------------------------------------
print("Step 1: Generating fraud detection dataset...")
X, y = make_classification(
n_samples=10000,
n_features=25,
n_informative=12,
n_redundant=5,
weights=[0.98, 0.02], # 2% fraud rate — realistic
random_state=42,
flip_y=0.01 # Some label noise
)
print(f" Total samples: {len(y)}")
print(f" Legitimate transactions: {(y == 0).sum()} ({(y == 0).mean()*100:.1f}%)")
print(f" Fraudulent transactions: {(y == 1).sum()} ({(y == 1).mean()*100:.1f}%)")
print(f" Class ratio: {(y == 0).sum() / (y == 1).sum():.0f}:1")
# -------------------------------------------------------
# 2. Split Data (Stratified)
# -------------------------------------------------------
print("\nStep 2: Splitting data with stratification...")
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42, stratify=y
)
print(f" Training positives: {y_train.sum()}")
print(f" Test positives: {y_test.sum()}")
# -------------------------------------------------------
# 3. Build Pipelines
# -------------------------------------------------------
print("\nStep 3: Building model pipelines...")
pipelines = {
"LR (no adjustment)": Pipeline([
('scaler', StandardScaler()),
('clf', LogisticRegression(random_state=42, max_iter=1000))
]),
"LR (class_weight=balanced)": Pipeline([
('scaler', StandardScaler()),
('clf', LogisticRegression(class_weight='balanced', random_state=42, max_iter=1000))
]),
"RF (no adjustment)": Pipeline([
('clf', RandomForestClassifier(n_estimators=200, random_state=42, n_jobs=-1))
]),
"RF (class_weight=balanced)": Pipeline([
('clf', RandomForestClassifier(n_estimators=200, class_weight='balanced',
random_state=42, n_jobs=-1))
]),
}
# -------------------------------------------------------
# 4. Cross-Validate with Stratified K-Fold
# -------------------------------------------------------
print("\nStep 4: Stratified 5-fold cross-validation (scoring: F1)...")
f1_scorer = make_scorer(f1_score, zero_division=0)
skf = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)
cv_results = {}
print(f"\n{'Model':<35} | {'Mean F1':>8} | {'Std':>6}")
print("-" * 57)
for name, pipeline in pipelines.items():
scores = cross_val_score(pipeline, X_train, y_train, cv=skf, scoring=f1_scorer)
cv_results[name] = scores
print(f"{name:<35} | {scores.mean():>8.4f} | {scores.std():>6.4f}")
# -------------------------------------------------------
# 5. Select Best Model and Evaluate on Test Set
# -------------------------------------------------------
best_model_name = max(cv_results, key=lambda k: cv_results[k].mean())
print(f"\nBest model: {best_model_name}")
best_pipeline = pipelines[best_model_name]
best_pipeline.fit(X_train, y_train)
# -------------------------------------------------------
# 6. Threshold Optimization on Validation Subset
# -------------------------------------------------------
# Carve out a small validation set from training data for threshold tuning
X_tr, X_val, y_tr, y_val = train_test_split(
X_train, y_train, test_size=0.2, random_state=42, stratify=y_train
)
best_pipeline.fit(X_tr, y_tr)
y_val_proba = best_pipeline.predict_proba(X_val)[:, 1]
precisions, recalls, thresholds = precision_recall_curve(y_val, y_val_proba)
val_f1_scores = (2 * precisions[:-1] * recalls[:-1] /
(precisions[:-1] + recalls[:-1] + 1e-10))
optimal_threshold = thresholds[np.argmax(val_f1_scores)]
print(f"\nStep 5: Threshold optimization on validation set...")
print(f" Default threshold (0.5) Val F1: "
f"{f1_score(y_val, (y_val_proba >= 0.5).astype(int), zero_division=0):.4f}")
print(f" Optimal threshold ({optimal_threshold:.3f}) Val F1: "
f"{val_f1_scores.max():.4f}")
# -------------------------------------------------------
# 7. Final Evaluation on Test Set
# -------------------------------------------------------
print("\nStep 6: Final evaluation on held-out test set...")
# Retrain on full training data
best_pipeline.fit(X_train, y_train)
y_test_proba = best_pipeline.predict_proba(X_test)[:, 1]
y_pred_default = (y_test_proba >= 0.5).astype(int)
y_pred_optimal = (y_test_proba >= optimal_threshold).astype(int)
print(f"\n{'Metric':<20} | {'Default (0.5)':>13} | {'Optimal ({:.3f})'.format(optimal_threshold):>16}")
print("-" * 55)
for metric_name, fn in [
("Accuracy", accuracy_score),
("Precision", lambda a, b: precision_score(a, b, zero_division=0)),
("Recall", lambda a, b: recall_score(a, b, zero_division=0)),
("F1 Score", lambda a, b: f1_score(a, b, zero_division=0)),
]:
default_val = fn(y_test, y_pred_default)
optimal_val = fn(y_test, y_pred_optimal)
print(f"{metric_name:<20} | {default_val:>13.4f} | {optimal_val:>16.4f}")
print(f"\n=== Classification Report (Optimal Threshold) ===")
print(classification_report(
y_test, y_pred_optimal,
target_names=["Legitimate", "Fraudulent"],
zero_division=0
))This complete pipeline demonstrates every best practice for F1-based model development on imbalanced data: stratified splitting, cross-validation with the correct scorer, threshold optimization on the validation set, and clean final evaluation on the held-out test set.
Summary
The F1 score is the single most important metric to understand for imbalanced classification problems, which describes the vast majority of high-stakes real-world applications: fraud detection, medical diagnosis, anomaly detection, and more.
The harmonic mean formula is not arbitrary — it is specifically designed to penalize extreme imbalance between precision and recall, making it impossible to achieve a high F1 score by excelling at one while failing at the other. Most importantly, because F1 completely ignores true negatives, it is immune to the accuracy paradox that plagues imbalanced datasets.
The binary F1 score generalizes to multiclass problems through macro, weighted, and micro averaging — each appropriate for different business contexts. The Fbeta score generalizes the equal weighting assumption, allowing you to explicitly encode your organization’s cost structure into the metric itself.
A good F1-based workflow for imbalanced data always starts with stratified splitting and cross-validation to get reliable estimates, considers threshold optimization to move beyond the arbitrary 0.5 default, and uses complementary strategies like class weighting or resampling to help the model learn the minority class effectively.