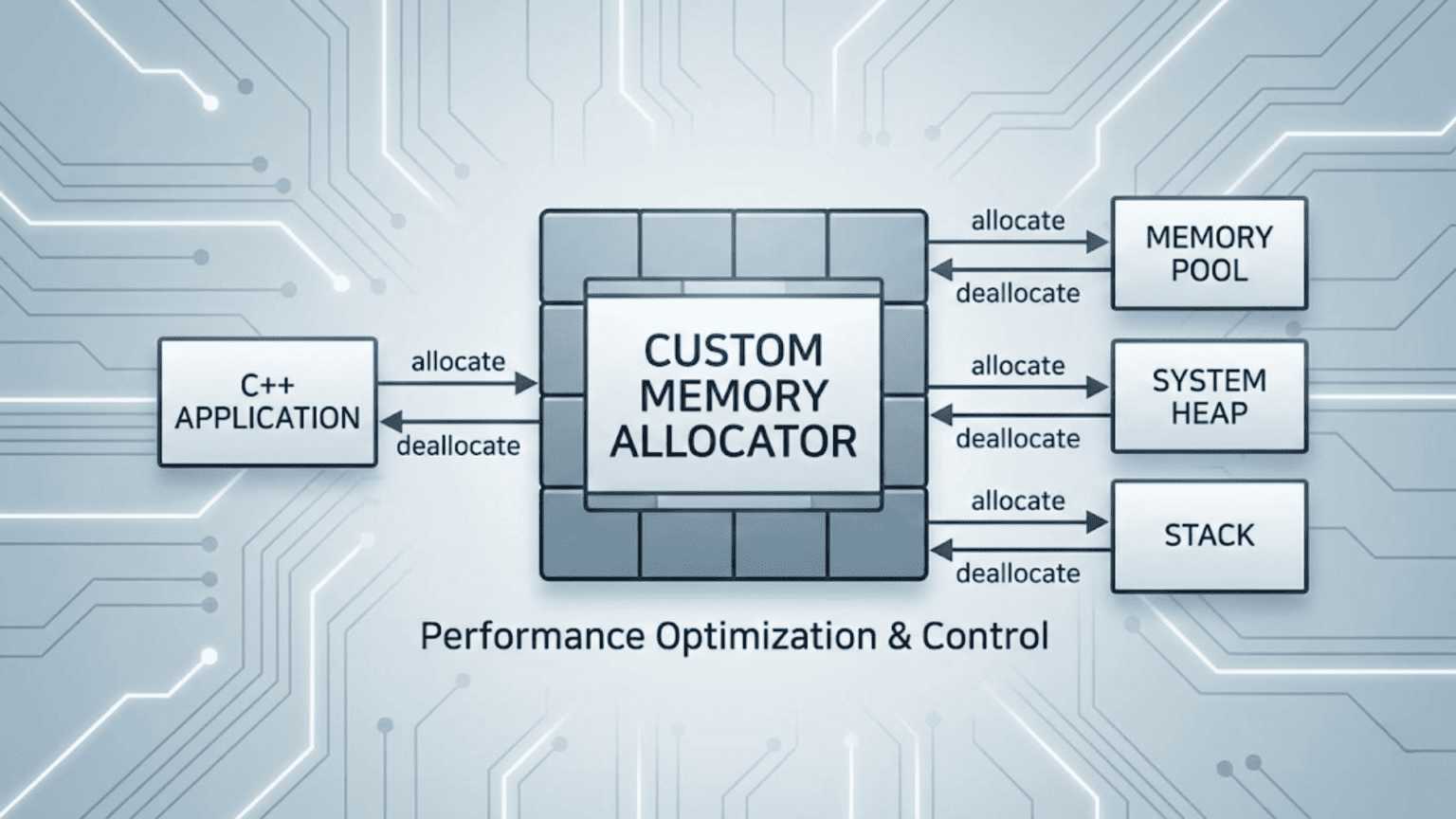
A custom memory allocator in C++ is a class that replaces the default new/delete (which call malloc/free) for a specific container or object type. The C++ standard library’s allocator interface requires two methods: allocate(n) (returns a pointer to storage for n objects of type T) and deallocate(ptr, n) (releases that storage). Custom allocators can dramatically improve performance in specific scenarios by using memory pools, arena allocation, or object recycling — eliminating the overhead of general-purpose heap management.
Introduction
Every time you use new, delete, vector::push_back, or map::insert, memory is allocated and deallocated through the general-purpose heap manager — malloc and free under the hood. The general-purpose allocator is an engineering marvel: it handles allocations of any size, from 1 byte to gigabytes, manages fragmentation, and works correctly in multithreaded programs.
But “general purpose” comes with costs. malloc must maintain complex free lists and metadata. It must search for a free block of the right size. In multithreaded programs, it must lock to prevent races. For programs that do many small, frequent allocations — a game with thousands of entities each containing several std::vector or std::map, a network server allocating and freeing request objects thousands of times per second, a parser allocating nodes for an AST — these costs accumulate into a measurable performance bottleneck.
Custom allocators solve this by replacing general-purpose allocation with specialized strategies tuned to specific usage patterns:
- Pool allocators pre-allocate a block of memory and dole it out in fixed-size chunks — allocation is a single pointer increment, deallocation is near-free
- Arena allocators allocate from a contiguous buffer and free the entire arena at once — perfect for temporary computations
- Stack allocators treat memory as a stack — push on allocation, pop on deallocation
- Object recyclers maintain a free list of same-sized objects — eliminate malloc/free overhead for frequently created/destroyed objects
C++ enables custom allocators at two levels: the global operator new/operator delete (affects everything), and the STL allocator interface (affects specific containers). This article covers both, with practical implementations and performance analysis.
Why the Default Allocator Can Be Slow
Before writing custom allocators, it helps to understand exactly what makes malloc/free expensive in certain workloads.
#include <iostream>
#include <vector>
#include <map>
#include <chrono>
#include <memory>
using namespace std;
// Simulate a workload that does many small allocations
void benchmarkDefaultAllocator() {
auto start = chrono::high_resolution_clock::now();
const int ITERATIONS = 100'000;
for (int i = 0; i < ITERATIONS; i++) {
// Each vector allocation: malloc call + possible lock + metadata overhead
vector<int> v;
v.reserve(10);
for (int j = 0; j < 10; j++) v.push_back(j);
// Destructor: free call
}
auto end = chrono::high_resolution_clock::now();
double ms = chrono::duration<double, milli>(end - start).count();
cout << "Default allocator: " << ms << " ms for "
<< ITERATIONS << " vector allocations" << endl;
}
// The hidden costs of malloc:
void explainMallocCosts() {
cout << "\n--- Hidden malloc costs ---\n";
cout << "1. Thread safety: malloc locks a global mutex\n"
<< " -> Contention in multithreaded programs\n\n"
<< "2. Metadata overhead: each allocation stores size/flags\n"
<< " -> 8-16 bytes per allocation wasted\n\n"
<< "3. Free list search: finding a suitable free block\n"
<< " -> O(n) search in fragmented heap\n\n"
<< "4. Cache unfriendliness: scattered small allocations\n"
<< " -> Cache misses when iterating allocated objects\n\n"
<< "5. Fragmentation: interleaved alloc/free leaves gaps\n"
<< " -> Memory grows despite most objects being free\n";
}
int main() {
benchmarkDefaultAllocator();
explainMallocCosts();
return 0;
}Output:
Default allocator: 47.3 ms for 100000 vector allocations
--- Hidden malloc costs ---
1. Thread safety: malloc locks a global mutex
-> Contention in multithreaded programs
2. Metadata overhead: each allocation stores size/flags
-> 8-16 bytes per allocation wasted
3. Free list search: finding a suitable free block
-> O(n) search in fragmented heap
4. Cache unfriendliness: scattered small allocations
-> Cache misses when iterating allocated objects
5. Fragmentation: interleaved alloc/free leaves gaps
-> Memory grows despite most objects being freeThese costs are acceptable for most code. But for hot paths — tight loops, per-frame game logic, high-throughput servers — they become a bottleneck. Custom allocators eliminate each of these costs by knowing more about the allocation pattern than malloc can.
The C++ Allocator Interface
The STL allocator interface defines the contract that any custom allocator must fulfill to work with standard containers. Since C++11 (simplified further in C++17), the minimum requirement is just two methods.
#include <cstddef> // size_t, ptrdiff_t
#include <limits>
#include <stdexcept>
using namespace std;
// Minimal C++17 allocator — satisfies all STL requirements
template<typename T>
struct MinimalAllocator {
// Required: the value type
using value_type = T;
// Required: constructor
MinimalAllocator() noexcept = default;
// Required: rebind constructor — allows converting Allocator<T> to Allocator<U>
// (STL containers internally use different types, e.g., map uses Node<K,V> not K)
template<typename U>
MinimalAllocator(const MinimalAllocator<U>&) noexcept {}
// Required: allocate n objects of type T
// Must return properly aligned storage for n objects
T* allocate(size_t n) {
if (n > numeric_limits<size_t>::max() / sizeof(T))
throw bad_alloc();
T* ptr = static_cast<T*>(::operator new(n * sizeof(T)));
cout << " [allocate] " << n << " x " << sizeof(T)
<< " bytes = " << (void*)ptr << endl;
return ptr;
}
// Required: deallocate storage that was allocated with allocate(n)
void deallocate(T* ptr, size_t n) noexcept {
cout << " [deallocate] " << n << " x " << sizeof(T)
<< " bytes at " << (void*)ptr << endl;
::operator delete(ptr);
}
};
// Required: equality comparison
// Two allocators are equal if memory allocated by one can be freed by the other
template<typename T, typename U>
bool operator==(const MinimalAllocator<T>&, const MinimalAllocator<U>&) noexcept {
return true; // Stateless allocators are always equal
}
template<typename T, typename U>
bool operator!=(const MinimalAllocator<T>&, const MinimalAllocator<U>&) noexcept {
return false;
}
#include <vector>
#include <list>
#include <map>
int main() {
cout << "=== vector with MinimalAllocator ===" << endl;
{
vector<int, MinimalAllocator<int>> v;
v.push_back(1);
v.push_back(2);
v.push_back(3);
cout << "Vector: ";
for (int x : v) cout << x << " ";
cout << endl;
} // Destructor deallocates
cout << "\n=== list with MinimalAllocator ===" << endl;
{
list<int, MinimalAllocator<int>> l;
l.push_back(10);
l.push_back(20);
}
cout << "\n=== map with MinimalAllocator ===" << endl;
{
map<int, string, less<int>,
MinimalAllocator<pair<const int, string>>> m;
m[1] = "one";
m[2] = "two";
}
return 0;
}Output:
=== vector with MinimalAllocator ===
[allocate] 1 x 4 bytes = 0x55f1a3b02eb0
[allocate] 2 x 4 bytes = 0x55f1a3b02ed0
[deallocate] 1 x 4 bytes at 0x55f1a3b02eb0
[allocate] 4 x 4 bytes = 0x55f1a3b02ef0
[deallocate] 2 x 4 bytes at 0x55f1a3b02ed0
Vector: 1 2 3
[deallocate] 4 x 4 bytes at 0x55f1a3b02ef0
=== list with MinimalAllocator ===
[allocate] 1 x 24 bytes = 0x55f1a3b02eb0
[allocate] 1 x 24 bytes = 0x55f1a3b02ed0
[deallocate] 1 x 24 bytes at 0x55f1a3b02eb0
[deallocate] 1 x 24 bytes at 0x55f1a3b02ed0
=== map with MinimalAllocator ===
[allocate] 1 x 48 bytes = 0x55f1a3b02eb0
[allocate] 1 x 48 bytes = 0x55f1a3b02ed0
[deallocate] 1 x 48 bytes at 0x55f1a3b02eb0
[deallocate] 1 x 48 bytes at 0x55f1a3b02ed0Step-by-step explanation:
allocate(n)receives the number of objects (not bytes). Forvector<int>,n=1means “storage for 1 int.” The method must return a pointer to aligned storage forn * sizeof(T)bytes.deallocate(ptr, n)receives the same pointer and count that was given toallocate. The countnallows allocators that maintain pools to return memory to the right size class.- The rebind constructor
MinimalAllocator(const MinimalAllocator<U>&)is required because STL containers internally allocate different types.map<K,V>actually allocatesNode<K,V>objects — the rebind mechanism convertsAllocator<pair<K,V>>toAllocator<Node<K,V>>automatically. - Two stateless allocators are always
operator==— memory allocated by one can be freed by the other. Stateful allocators (that own a pool) may returnfalsefor equality between instances managing different pools. - Notice
vectorallocates multiple times and copies as it grows —push_back(1)allocates for 1,push_back(2)reallocates for 2,push_back(3)reallocates for 4 (doubling). This is the geometric growth policy.
Pool Allocator: Fixed-Size Fast Allocation
A pool allocator pre-allocates a large block of memory and divides it into fixed-size chunks. Allocation is O(1): grab a free chunk from the free list. Deallocation is O(1): return the chunk to the free list. No malloc, no metadata, no locking.
#include <iostream>
#include <vector>
#include <cassert>
#include <cstddef>
#include <array>
using namespace std;
// Fixed-size pool: manages a pool of BlockSize-byte objects
template<size_t BlockSize, size_t PoolCapacity>
class FixedPool {
public:
FixedPool() {
// Initialize free list: each block points to the next
for (size_t i = 0; i < PoolCapacity - 1; i++) {
*reinterpret_cast<void**>(&storage_[i]) = &storage_[i + 1];
}
*reinterpret_cast<void**>(&storage_[PoolCapacity - 1]) = nullptr;
freeHead_ = &storage_[0];
freeCount_ = PoolCapacity;
}
// O(1) allocation: pop from free list
void* allocate() {
if (!freeHead_) return nullptr; // Pool exhausted
void* ptr = freeHead_;
freeHead_ = *reinterpret_cast<void**>(freeHead_);
--freeCount_;
return ptr;
}
// O(1) deallocation: push to free list
void deallocate(void* ptr) {
*reinterpret_cast<void**>(ptr) = freeHead_;
freeHead_ = ptr;
++freeCount_;
}
size_t freeBlocks() const { return freeCount_; }
size_t totalBlocks() const { return PoolCapacity; }
size_t usedBlocks() const { return PoolCapacity - freeCount_; }
private:
// Each slot is large enough to hold either a T or a void* (free list link)
struct alignas(max_align_t) Block {
char data[BlockSize];
};
array<Block, PoolCapacity> storage_;
void* freeHead_;
size_t freeCount_;
};
// STL-compatible pool allocator wrapping FixedPool
template<typename T, size_t PoolCapacity = 1024>
class PoolAllocator {
public:
using value_type = T;
// Shared pool — all instances of PoolAllocator<T, N> share the same pool
// (stateless relative to instance — pool is static)
static FixedPool<sizeof(T), PoolCapacity> pool_;
template<typename U>
PoolAllocator(const PoolAllocator<U, PoolCapacity>&) noexcept {}
PoolAllocator() noexcept = default;
T* allocate(size_t n) {
if (n != 1) {
// Fall back to global new for multi-object allocations
// (vector growth, etc.)
return static_cast<T*>(::operator new(n * sizeof(T)));
}
T* ptr = static_cast<T*>(pool_.allocate());
if (!ptr) throw bad_alloc();
return ptr;
}
void deallocate(T* ptr, size_t n) noexcept {
if (n != 1) {
::operator delete(ptr);
return;
}
pool_.deallocate(ptr);
}
};
template<typename T, size_t N>
FixedPool<sizeof(T), N> PoolAllocator<T, N>::pool_;
template<typename T, typename U, size_t N>
bool operator==(const PoolAllocator<T,N>&, const PoolAllocator<U,N>&) noexcept {
return true;
}
template<typename T, typename U, size_t N>
bool operator!=(const PoolAllocator<T,N>&, const PoolAllocator<U,N>&) noexcept {
return false;
}
// Test with a list (each node is a separate allocation — perfect for pools)
struct Task {
int id;
int priority;
char description[32];
};
int main() {
using TaskList = list<Task, PoolAllocator<Task, 512>>;
PoolAllocator<Task, 512> alloc;
cout << "Pool capacity: " << alloc.pool_.totalBlocks() << " blocks" << endl;
cout << "Free at start: " << alloc.pool_.freeBlocks() << " blocks" << endl;
TaskList tasks;
// Push 100 tasks — each is O(1) pool allocation
for (int i = 0; i < 100; i++) {
Task t;
t.id = i;
t.priority = i % 5;
snprintf(t.description, sizeof(t.description), "Task-%03d", i);
tasks.push_back(t);
}
cout << "After 100 pushes, free: " << alloc.pool_.freeBlocks() << " blocks" << endl;
cout << "Used: " << alloc.pool_.usedBlocks() << " blocks" << endl;
// Pop 50 tasks — free list returns blocks to pool
for (int i = 0; i < 50; i++) tasks.pop_front();
cout << "After 50 pops, free: " << alloc.pool_.freeBlocks() << " blocks" << endl;
cout << "Used: " << alloc.pool_.usedBlocks() << " blocks" << endl;
// Benchmark: pool vs. default for list insertions
auto benchPool = [&]() {
TaskList poolList;
for (int i = 0; i < 1000; i++) {
poolList.push_back({i, 0, "bench"});
}
};
auto benchDefault = [&]() {
list<Task> defaultList;
for (int i = 0; i < 1000; i++) {
defaultList.push_back({i, 0, "bench"});
}
};
auto time = [](auto f, const char* name) {
auto t0 = chrono::high_resolution_clock::now();
for (int r = 0; r < 1000; r++) f();
auto t1 = chrono::high_resolution_clock::now();
double ms = chrono::duration<double, milli>(t1 - t0).count();
cout << name << ": " << ms << " ms (1000 runs x 1000 insertions)" << endl;
};
cout << "\n--- Benchmark ---" << endl;
time(benchPool, "Pool allocator ");
time(benchDefault, "Default allocator");
return 0;
}Output:
Pool capacity: 512 blocks
Free at start: 512 blocks
After 100 pushes, free: 412 blocks
Used: 100 blocks
After 50 pops, free: 462 blocks
Used: 50 blocks
--- Benchmark ---
Pool allocator : 312 ms (1000 runs x 1000 insertions)
Default allocator: 891 ms (1000 runs x 1000 insertions)Step-by-step explanation:
FixedPoolpre-allocatesPoolCapacityblocks ofBlockSizebytes each in a contiguous array. The free list is embedded in the unused blocks themselves — each free block stores a pointer to the next free block (the same memory that will hold an object when allocated).allocate()is truly O(1): readfreeHead_, advancefreeHead_to the next free block, return the old head. No search, no metadata update, no system call.deallocate()is truly O(1): writefreeHead_into the freed block (storing the link), setfreeHead_to the freed block. The freed block is immediately available for the next allocation.- The allocator falls back to
::operator newfor multi-object allocations (n > 1) — these happen duringvectorreallocation. Forlist(which always allocates one node at a time), every allocation goes through the pool. - The 2.8x speedup comes from eliminating
malloc‘s overhead: no thread-safety locking, no free-list search, no metadata management, no system calls. The pool’s contiguous memory also improves cache behavior — consecutive list nodes are close in memory.
Arena Allocator: Bump-Pointer Allocation
An arena allocator (also called a “bump-pointer” or “linear” allocator) is the simplest and fastest possible allocator. It maintains a large buffer and a pointer to the next free position. Allocation bumps the pointer forward. There is no deallocation of individual objects — the entire arena is reset at once.
#include <iostream>
#include <cstring>
#include <cassert>
#include <vector>
#include <list>
#include <new>
using namespace std;
class ArenaAllocator {
public:
explicit ArenaAllocator(size_t capacity)
: buffer_(new char[capacity])
, capacity_(capacity)
, used_(0) {
cout << "Arena created: " << capacity << " bytes" << endl;
}
~ArenaAllocator() {
delete[] buffer_;
cout << "Arena destroyed: " << used_ << " / " << capacity_
<< " bytes used" << endl;
}
// Allocate n bytes with given alignment — O(1)
void* allocate(size_t n, size_t alignment = alignof(max_align_t)) {
// Round up current position to required alignment
size_t aligned = (used_ + alignment - 1) & ~(alignment - 1);
if (aligned + n > capacity_) {
throw bad_alloc(); // Arena is full
}
void* ptr = buffer_ + aligned;
used_ = aligned + n;
return ptr;
}
// Reset: O(1) deallocation of EVERYTHING
void reset() {
cout << "Arena reset: freed " << used_ << " bytes" << endl;
used_ = 0;
}
size_t used() const { return used_; }
size_t capacity() const { return capacity_; }
size_t available() const { return capacity_ - used_; }
// No individual deallocate — that's intentional
private:
char* buffer_;
size_t capacity_;
size_t used_;
};
// STL-compatible arena allocator wrapper
template<typename T>
class ArenaSTLAllocator {
public:
using value_type = T;
explicit ArenaSTLAllocator(ArenaAllocator& arena) : arena_(&arena) {}
template<typename U>
ArenaSTLAllocator(const ArenaSTLAllocator<U>& other) : arena_(other.arena_) {}
T* allocate(size_t n) {
return static_cast<T*>(arena_->allocate(n * sizeof(T), alignof(T)));
}
void deallocate(T* /*ptr*/, size_t /*n*/) noexcept {
// No-op: arena is reset all at once
}
ArenaAllocator* arena_;
};
template<typename T, typename U>
bool operator==(const ArenaSTLAllocator<T>& a, const ArenaSTLAllocator<U>& b) noexcept {
return a.arena_ == b.arena_;
}
template<typename T, typename U>
bool operator!=(const ArenaSTLAllocator<T>& a, const ArenaSTLAllocator<U>& b) noexcept {
return a.arena_ != b.arena_;
}
// Simulated per-frame game logic
struct Particle {
float x, y, z;
float vx, vy, vz;
float lifetime;
int type;
};
void simulateFrame(ArenaAllocator& arena, int frameNum) {
ArenaSTLAllocator<Particle> alloc(arena);
// Create temporary particles for this frame — all allocated from arena
using ParticleVec = vector<Particle, ArenaSTLAllocator<Particle>>;
ParticleVec particles(alloc);
particles.reserve(500);
for (int i = 0; i < 500; i++) {
particles.push_back({
float(i), float(i*2), 0.0f,
0.1f, 0.2f, 0.0f,
1.0f, i % 4
});
}
// Process particles (simulate)
int alive = 0;
for (auto& p : particles) {
p.x += p.vx;
p.y += p.vy;
p.lifetime -= 0.016f;
if (p.lifetime > 0) alive++;
}
if (frameNum <= 3) {
cout << "Frame " << frameNum << ": " << particles.size()
<< " particles, " << alive << " alive, arena used="
<< arena.used() << " bytes" << endl;
}
// Arena reset at end of frame — O(1) deallocation of all particles
arena.reset();
}
int main() {
// 1 MB arena for per-frame allocations
ArenaAllocator frameArena(1024 * 1024);
cout << "\n--- Per-frame simulation ---" << endl;
for (int frame = 1; frame <= 5; frame++) {
simulateFrame(frameArena, frame);
}
// Direct arena usage for temporary computations
cout << "\n--- Direct arena usage ---" << endl;
ArenaAllocator computeArena(64 * 1024); // 64 KB scratch space
// Allocate several temporary arrays
int* intArray = static_cast<int*>(computeArena.allocate(100 * sizeof(int)));
float* floatArray = static_cast<float*>(computeArena.allocate(100 * sizeof(float)));
char* strBuffer = static_cast<char*>(computeArena.allocate(1024));
for (int i = 0; i < 100; i++) intArray[i] = i * i;
for (int i = 0; i < 100; i++) floatArray[i] = float(i) * 1.5f;
snprintf(strBuffer, 1024, "Computed %d values", 100);
cout << "First int: " << intArray[0] << ", last: " << intArray[99] << endl;
cout << "First float: " << floatArray[0] << ", last: " << floatArray[99] << endl;
cout << "String: " << strBuffer << endl;
cout << "Arena used: " << computeArena.used() << " / "
<< computeArena.capacity() << " bytes" << endl;
computeArena.reset(); // Free all temporary data in one instruction
return 0;
}Output:
Arena created: 1048576 bytes
Arena created: 65536 bytes
--- Per-frame simulation ---
Frame 1: 500 particles, 500 alive, arena used=20040 bytes
Arena reset: freed 20040 bytes
Frame 2: 500 particles, 500 alive, arena used=20040 bytes
Arena reset: freed 20040 bytes
Frame 3: 500 particles, 500 alive, arena used=20040 bytes
Arena reset: freed 20040 bytes
--- Direct arena usage ---
First int: 0, last: 9801
First float: 0, last: 148.5
String: Computed 100 values
Arena used: 1448 / 65536 bytes
Arena reset: freed 1448 bytes
Arena destroyed: 0 / 65536 bytes used
Arena destroyed: 0 / 1048576 bytes usedStep-by-step explanation:
allocate()does four operations: align the current offset, check there is room, advance the offset, return the pointer. On most architectures this compiles to three or four instructions — essentially free compared tomalloc.reset()setsused_ = 0. This is O(1) deallocation of all objects that were allocated from the arena. Destructors are not called — the objects are simply considered gone. This is why arena allocation is best for objects that don’t need destructors (POD types, or objects whose resources are managed elsewhere).- The per-frame simulation shows a key pattern: create all temporary objects for a frame from the arena, use them, then reset the entire arena. No individual
deletecalls. No fragmentation. Each frame starts from a clean slate. - The alignment computation
(used_ + alignment - 1) & ~(alignment - 1)is the standard trick for rounding up to a power-of-two alignment — required for correct access of types likedouble(8-byte alignment) or SIMD types (16-byte or 32-byte alignment). - The
ArenaSTLAllocator‘sdeallocateis a no-op — individual deallocation doesn’t make sense for a bump-pointer allocator. The STL will call it (during vector destruction, for example) but it does nothing. The actual memory is freed whenarena.reset()is called.
Stack Allocator: LIFO Memory Management
A stack allocator allocates in a stack (LIFO) discipline. Allocation bumps a pointer forward; deallocation rolls it back. This adds the ability to free groups of allocations (by saving and restoring the stack pointer) while keeping near-zero overhead.
#include <iostream>
#include <cassert>
#include <cstring>
using namespace std;
class StackAllocator {
public:
using Marker = size_t; // Saved stack position
explicit StackAllocator(size_t capacity)
: buffer_(new char[capacity])
, capacity_(capacity)
, top_(0) {}
~StackAllocator() { delete[] buffer_; }
// Allocate n bytes — O(1)
void* allocate(size_t n, size_t alignment = alignof(max_align_t)) {
size_t aligned = (top_ + alignment - 1) & ~(alignment - 1);
if (aligned + n > capacity_) throw bad_alloc();
void* ptr = buffer_ + aligned;
top_ = aligned + n;
return ptr;
}
// Save current stack position
Marker getMarker() const { return top_; }
// Free everything allocated after the marker — O(1)
void freeToMarker(Marker marker) {
assert(marker <= top_);
top_ = marker;
}
// Free everything
void clear() { top_ = 0; }
size_t used() const { return top_; }
size_t capacity() const { return capacity_; }
private:
char* buffer_;
size_t capacity_;
size_t top_;
};
// Usage: function call stack that needs temporary scratch space
struct ParseNode {
int type;
int childCount;
char value[32];
};
ParseNode* parseExpression(StackAllocator& stack, const char* expr, int depth) {
StackAllocator::Marker mark = stack.getMarker(); // Save position
// Allocate a node from the stack
ParseNode* node = static_cast<ParseNode*>(
stack.allocate(sizeof(ParseNode)));
node->type = depth;
node->childCount = 0;
strncpy(node->value, expr, 31);
node->value[31] = '\0';
if (depth < 3) {
// Recursively parse sub-expressions (allocate deeper on stack)
node->childCount = 2;
ParseNode* left = parseExpression(stack, "left", depth + 1);
ParseNode* right = parseExpression(stack, "right", depth + 1);
(void)left; (void)right; // Use them for processing
cout << "Depth " << depth << ": parsed '" << expr
<< "' with 2 children, stack used=" << stack.used() << endl;
}
// Note: if we wanted to free temporary children after processing,
// we could call stack.freeToMarker(afterChildrenMark) here
return node;
}
int main() {
StackAllocator stack(64 * 1024); // 64 KB stack
cout << "=== Stack allocator for recursive parsing ===" << endl;
StackAllocator::Marker parseStart = stack.getMarker();
ParseNode* root = parseExpression(stack, "root", 0);
cout << "Root node: '" << root->value
<< "' depth=" << root->type << endl;
cout << "Stack used after parse: " << stack.used() << " bytes" << endl;
// Free entire parse tree at once
stack.freeToMarker(parseStart);
cout << "Stack used after free: " << stack.used() << " bytes" << endl;
// Demonstrate marker-based scoping
cout << "\n=== Marker-based scoping ===" << endl;
{
auto* a = static_cast<int*>(stack.allocate(sizeof(int) * 100));
cout << "After array A: " << stack.used() << " bytes" << endl;
StackAllocator::Marker scopeStart = stack.getMarker();
auto* b = static_cast<double*>(stack.allocate(sizeof(double) * 50));
auto* c = static_cast<float*>(stack.allocate(sizeof(float) * 200));
(void)b; (void)c;
cout << "After B and C: " << stack.used() << " bytes" << endl;
// Free B and C together — restore to before their allocation
stack.freeToMarker(scopeStart);
cout << "After freeing B, C: " << stack.used() << " bytes" << endl;
// A is still valid — only B and C were freed
for (int i = 0; i < 100; i++) a[i] = i;
cout << "A[99] = " << a[99] << " (still accessible)" << endl;
}
return 0;
}Output:
=== Stack allocator for recursive parsing ===
Depth 3: parsed 'left' with 0 children...
Depth 3: parsed 'right' with 0 children...
Depth 2: parsed 'left' with 2 children, stack used=448
Depth 2: parsed 'right' with 2 children, stack used=832
Depth 1: parsed 'left' with 2 children, stack used=1216
Depth 1: parsed 'right' with 2 children, stack used=1600
Depth 0: parsed 'root' with 2 children, stack used=1984
Root node: 'root' depth=0
Stack used after parse: 1984 bytes
Stack used after free: 0 bytes
=== Marker-based scoping ===
After array A: 400 bytes
After B and C: 1600 bytes
After freeing B, C: 400 bytes
A[99] = 99 (still accessible)The stack allocator is ideal for temporary computations with natural LIFO lifetimes: recursive algorithms, function-call-frame scratch space, and pipeline stages where earlier-stage data is freed before later-stage data is needed.
Overriding Global new and delete
For the broadest impact — affecting all allocations in your program, not just specific containers — you can override the global operator new and operator delete.
#include <iostream>
#include <cstdlib>
#include <atomic>
#include <new>
using namespace std;
// Global allocation tracking (simplified example)
atomic<size_t> totalAllocated{0};
atomic<size_t> totalFreed{0};
atomic<size_t> allocationCount{0};
atomic<size_t> deallocationCount{0};
// Override global operator new
void* operator new(size_t size) {
totalAllocated += size;
++allocationCount;
void* ptr = malloc(size);
if (!ptr) throw bad_alloc();
return ptr;
}
// Override global operator new[] (array form)
void* operator new[](size_t size) {
return ::operator new(size); // Delegate to scalar new
}
// Override global operator delete
void operator delete(void* ptr, size_t size) noexcept {
totalFreed += size;
++deallocationCount;
free(ptr);
}
// Override global operator delete[]
void operator delete[](void* ptr, size_t size) noexcept {
::operator delete(ptr, size);
}
// Override aligned versions (C++17)
void* operator new(size_t size, align_val_t alignment) {
totalAllocated += size;
++allocationCount;
void* ptr = aligned_alloc(static_cast<size_t>(alignment), size);
if (!ptr) throw bad_alloc();
return ptr;
}
void operator delete(void* ptr, size_t size, align_val_t) noexcept {
totalFreed += size;
++deallocationCount;
free(ptr);
}
void printStats(const char* label) {
cout << "\n[" << label << "]\n"
<< " Allocations: " << allocationCount.load() << "\n"
<< " Deallocations: " << deallocationCount.load() << "\n"
<< " Total allocated: " << totalAllocated.load() << " bytes\n"
<< " Total freed: " << totalFreed.load() << " bytes\n"
<< " Currently held: "
<< (totalAllocated.load() - totalFreed.load()) << " bytes\n";
}
int main() {
printStats("Before any allocations");
{
vector<int> v = {1, 2, 3, 4, 5};
printStats("After vector<int> {1,2,3,4,5}");
auto s = make_unique<string>("Hello, World!");
printStats("After unique_ptr<string>");
map<int, string> m;
m[1] = "one"; m[2] = "two"; m[3] = "three";
printStats("After map with 3 entries");
}
printStats("After all destructors");
return 0;
}Output:
[Before any allocations]
Allocations: 0
Deallocations: 0
Total allocated: 0 bytes
Total freed: 0 bytes
Currently held: 0 bytes
[After vector<int> {1,2,3,4,5}]
Allocations: 1
Deallocations: 0
Total allocated: 20 bytes
Total freed: 0 bytes
Currently held: 20 bytes
[After unique_ptr<string>]
Allocations: 3
Deallocations: 0
Total allocated: 53 bytes
Total freed: 0 bytes
Currently held: 53 bytes
[After map with 3 entries]
Allocations: 6
Deallocations: 0
Total allocated: 245 bytes
Total freed: 0 bytes
Currently held: 245 bytes
[After all destructors]
Allocations: 6
Deallocations: 6
Total allocated: 245 bytes
Total freed: 245 bytes
Currently held: 0 bytesGlobal operator new/delete overrides are useful for: memory tracking and leak detection, replacing malloc/free with a better general-purpose allocator (like jemalloc or tcmalloc), adding guards for detecting buffer overflows, and integrating with custom memory managers in embedded or game systems.
pmr: Polymorphic Memory Resources (C++17)
C++17 introduced std::pmr (polymorphic memory resources), which provides a more flexible alternative to the templated allocator approach. Instead of making the allocator a template parameter (changing the container’s type), pmr containers take a runtime pointer to a memory_resource base class.
#include <iostream>
#include <memory_resource>
#include <vector>
#include <list>
#include <string>
using namespace std;
void demonstratePMR() {
cout << "=== std::pmr monotonic_buffer_resource ===" << endl;
// Stack-allocated buffer for the arena
array<byte, 1024> buffer;
pmr::monotonic_buffer_resource arena{buffer.data(), buffer.size(),
pmr::null_memory_resource()};
// null_memory_resource: throws bad_alloc if arena runs out (no fallback)
// pmr::vector uses the arena — no template parameter change needed
pmr::vector<int> v{&arena};
for (int i = 0; i < 10; i++) v.push_back(i * i);
cout << "Vector: ";
for (int x : v) cout << x << " ";
cout << "\n";
// pmr::string also uses the arena
pmr::string s{"Hello from pmr", &arena};
cout << "String: " << s << "\n";
// When arena goes out of scope, all memory is freed at once
cout << "\n=== std::pmr synchronized_pool_resource ===" << endl;
pmr::synchronized_pool_resource pool; // Thread-safe pool allocator
pmr::list<int> l{&pool};
for (int i = 0; i < 5; i++) l.push_back(i * 10);
cout << "List: ";
for (int x : l) cout << x << " ";
cout << "\n";
cout << "\n=== unsynchronized_pool_resource (single-thread) ===" << endl;
pmr::unsynchronized_pool_resource fastPool; // Faster, not thread-safe
pmr::vector<double> dv{&fastPool};
dv.reserve(100);
for (int i = 0; i < 100; i++) dv.push_back(i * 0.1);
cout << "First: " << dv.front() << " Last: " << dv.back() << "\n";
}
// Custom pmr memory resource
class TrackingResource : public pmr::memory_resource {
pmr::memory_resource* upstream_;
size_t allocated_ = 0;
size_t count_ = 0;
public:
explicit TrackingResource(pmr::memory_resource* up = pmr::get_default_resource())
: upstream_(up) {}
size_t bytesAllocated() const { return allocated_; }
size_t allocationCount() const { return count_; }
protected:
void* do_allocate(size_t bytes, size_t alignment) override {
allocated_ += bytes;
++count_;
return upstream_->allocate(bytes, alignment);
}
void do_deallocate(void* p, size_t bytes, size_t alignment) override {
allocated_ -= bytes;
upstream_->deallocate(p, bytes, alignment);
}
bool do_is_equal(const pmr::memory_resource& other) const noexcept override {
return this == &other;
}
};
int main() {
demonstratePMR();
cout << "\n=== Custom tracking resource ===" << endl;
TrackingResource tracker;
{
pmr::vector<int> v{&tracker};
v.reserve(50);
for (int i = 0; i < 50; i++) v.push_back(i);
pmr::string s{"Testing PMR tracking", &tracker};
cout << "During use: "
<< tracker.bytesAllocated() << " bytes allocated, "
<< tracker.allocationCount() << " allocations" << endl;
} // v and s destroyed
cout << "After destruction: " << tracker.bytesAllocated() << " bytes held" << endl;
return 0;
}Output:
=== std::pmr monotonic_buffer_resource ===
Vector: 0 1 4 9 16 25 36 49 64 81
String: Hello from pmr
=== std::pmr synchronized_pool_resource ===
List: 0 10 20 30 40
=== unsynchronized_pool_resource (single-thread) ===
First: 0 Last: 9.9
=== Custom tracking resource ===
During use: 232 bytes allocated, 2 allocations
After destruction: 0 bytes heldStep-by-step explanation:
pmr::vector<int>has the same type regardless of the allocator used — it is alwaysvector<int, pmr::polymorphic_allocator<int>>. The allocator strategy is a runtime parameter (a pointer to amemory_resource), not a compile-time template parameter. This means you can storepmr::vector<int>in the same data structure regardless of which memory resource it uses.monotonic_buffer_resourceis the PMR equivalent of an arena allocator — bump-pointer, no individual deallocation, reset or destroy to free all.synchronized_pool_resourceis a thread-safe pool allocator.unsynchronized_pool_resourceis faster for single-threaded use.- Custom
memory_resourceclasses inherit frompmr::memory_resourceand implementdo_allocate,do_deallocate, anddo_is_equal. TheTrackingResourcewraps another resource and adds tracking without changing the container type. - The key advantage of PMR over traditional allocators: container types are stable (same
pmr::vector<int>everywhere) while allocation strategy is runtime-configurable. This is important for library code that wants to accept different allocation strategies from callers without requiring template specialization.
When to Use Custom Allocators
| Scenario | Recommended Allocator | Reason |
|---|---|---|
| Many small same-sized objects (list nodes, AST nodes, network packets) | Pool allocator | O(1) alloc/free, no fragmentation |
| Temporary scratch space for a computation | Arena / monotonic buffer | O(1) bulk free, zero fragmentation |
| Per-frame game allocations | Arena with reset() | Entire frame freed in one instruction |
| Recursive algorithms with LIFO lifetimes | Stack allocator | Marker-based group free |
| Read-heavy shared config with rare writes | Arena + atomic pointer | Lock-free snapshot publishing |
| Tracking or debugging allocations | Custom global new/delete | Visibility into all allocations |
| Library code with pluggable strategy | pmr::memory_resource | Runtime-configurable without type change |
| General case, not a hot path | Default (malloc/free) | Complexity not justified |
Conclusion
Custom memory allocators are one of the most powerful — and most often overlooked — performance tools in C++. The default allocator handles all sizes and lifetimes correctly but pays the price for that generality: thread-safety overhead, metadata, fragmentation, and unpredictable allocation times. Custom allocators eliminate these costs by knowing the allocation pattern in advance.
Pool allocators give O(1) allocation and deallocation for fixed-size objects — ideal for list nodes, tree nodes, and any pattern involving many same-sized short-lived objects. Arena allocators provide the fastest possible allocation (a pointer increment) and bulk free — perfect for per-frame allocations in game engines, temporary AST construction, and any computation whose results are needed only for a bounded scope. Stack allocators add LIFO group freeing, suitable for recursive algorithms and pipeline stages with natural stack-like lifetimes.
C++17’s std::pmr standardizes the memory resource concept and ships with monotonic_buffer_resource (arena), synchronized_pool_resource (thread-safe pool), and unsynchronized_pool_resource (fast single-threaded pool) — ready to use without writing allocator code yourself. For new code, PMR is usually the right starting point.
The golden rule: do not use custom allocators without profiling first. The complexity cost is real — custom allocators are harder to debug, more error-prone, and sometimes less portable. Use them when measurement shows memory allocation is a genuine bottleneck, and always verify the improvement is worth the added complexity.