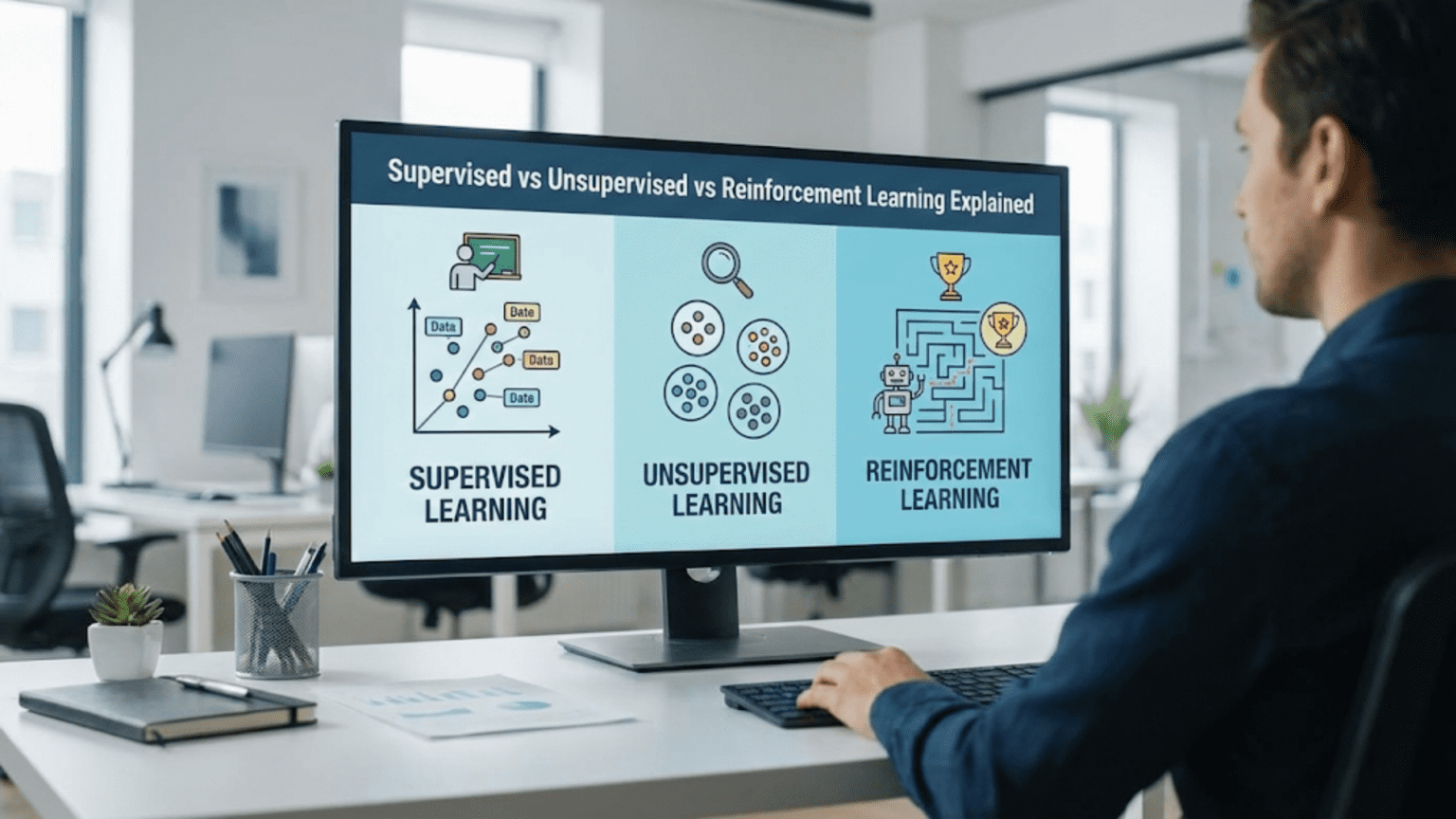
The three main types of machine learning are supervised learning (learning from labeled data with known answers), unsupervised learning (finding patterns in unlabeled data without predefined answers), and reinforcement learning (learning through trial and error by receiving rewards or penalties). Each approach solves different types of problems and requires different data and training methods.
Introduction: Understanding the Learning Landscape
Imagine three different scenarios for learning a new skill. In the first, a teacher shows you examples with correct answers and you learn by studying these labeled examples—like learning math from a textbook with worked solutions. In the second, you’re given raw information without answers and must discover patterns on your own—like organizing a messy closet without instructions. In the third, you learn by trying different actions and receiving feedback on what works—like learning to ride a bicycle through practice and balance adjustments.
These three scenarios mirror the three fundamental approaches to machine learning: supervised learning, unsupervised learning, and reinforcement learning. While all three enable computers to learn from data, they differ dramatically in how they learn, what data they require, and what problems they solve best.
Understanding these differences is crucial for anyone working with machine learning. Choosing the wrong approach is like using a hammer when you need a screwdriver—the tool itself might be excellent, but it’s not right for the task. Business leaders need to know which approach fits their problems, data scientists must select appropriate methods for their projects, and developers should understand what each type can and cannot accomplish.
This comprehensive guide will demystify these three learning paradigms. We’ll explore how each works, when to use them, their strengths and limitations, and real-world applications. By the end, you’ll be able to identify which type of machine learning suits different problems and understand the fundamental principles that make each approach powerful.
The Fundamental Divide: How Machines Learn
Before diving into specifics, let’s establish the core distinction between these learning types. The differences center on three key questions:
What kind of data is available? Does your data include correct answers (labels), or is it raw, unlabeled information? Can you gather feedback through interaction?
What is the learning goal? Are you trying to predict specific outcomes, discover hidden patterns, or learn optimal behaviors through experience?
How does learning occur? Does the system learn from example-answer pairs, from finding structure in data, or from trial-and-error with feedback?
These questions determine which approach is appropriate. Let’s examine each type in depth.
Supervised Learning: Learning with a Teacher
Supervised learning is the most straightforward and commonly used approach to machine learning. The name comes from the idea of a “supervisor” or teacher providing correct answers during training.
How Supervised Learning Works
In supervised learning, you train a model using labeled data—data where both the input and the correct output are known. The process resembles how students learn from worked examples in a textbook.
The learning process follows these steps:
- Provide labeled examples: Show the algorithm input data paired with correct outputs
- Make predictions: The algorithm attempts to predict outputs for the training inputs
- Calculate errors: Compare predictions to actual correct outputs
- Adjust parameters: Modify the model to reduce errors
- Repeat: Continue until the model makes accurate predictions
Think of teaching a child to identify fruits. You show them an apple and say “this is an apple,” show them a banana and say “this is a banana,” and so on. After seeing enough examples, the child learns to identify fruits they haven’t seen before. Supervised learning works the same way—the algorithm learns from labeled examples and then generalizes to new, unseen data.
The Two Flavors of Supervised Learning
Supervised learning divides into two main categories based on what you’re predicting:
Classification: Predicting Categories
Classification predicts discrete categories or classes. The output is a label from a predefined set of options.
Common classification problems include:
Binary Classification (two possible outcomes):
- Is this email spam or legitimate?
- Will this customer churn or stay?
- Is this transaction fraudulent or legitimate?
- Does this patient have the disease or not?
Multi-class Classification (more than two outcomes):
- Which digit (0-9) is in this image?
- What species of flower is this?
- Which category does this news article belong to (sports, politics, entertainment, etc.)?
- What emotion does this text express (happy, sad, angry, neutral)?
Multi-label Classification (multiple categories can apply):
- Which topics does this article cover? (can have multiple tags)
- What objects appear in this image? (can detect multiple objects)
- Which symptoms does this patient exhibit? (can have several)
Classification algorithms include logistic regression, decision trees, random forests, support vector machines, and neural networks. The choice depends on the problem complexity, data characteristics, and interpretability requirements.
Regression: Predicting Continuous Values
Regression predicts numerical values on a continuous scale rather than discrete categories.
Common regression problems include:
Financial Prediction:
- What will be the stock price tomorrow?
- What price will this house sell for?
- What will be the company’s revenue next quarter?
- What is the customer’s lifetime value?
Physical Measurements:
- What will be the temperature tomorrow?
- How much energy will this building consume?
- What will be the patient’s blood pressure after treatment?
- How long will this machine part last before failure?
Business Metrics:
- How many units will we sell next month?
- What will be the website traffic next week?
- How many customer support tickets should we expect?
- What will be the conversion rate for this campaign?
Regression algorithms include linear regression, polynomial regression, ridge and lasso regression, regression trees, and neural networks configured for continuous output.
Real-World Supervised Learning Applications
Supervised learning powers countless applications we encounter daily:
Email Spam Filtering: Your email provider has trained models on millions of emails labeled as spam or legitimate. When a new email arrives, the model predicts which category it belongs to based on patterns it learned—suspicious words, sender characteristics, email structure, and more. Gmail’s spam filter catches over 99.9% of spam using supervised learning.
Medical Diagnosis: Radiologists have labeled thousands of medical images indicating whether tumors are present. Machine learning models trained on these labeled images can now assist in detecting cancers, sometimes matching or exceeding human expert accuracy. For example, Google’s DeepMind developed a model that detects breast cancer from mammograms with fewer false positives and false negatives than human radiologists.
Credit Scoring: Banks have historical data on loan applications including applicant information and whether loans were repaid. Models trained on this data predict whether new applicants are likely to repay, helping banks make lending decisions. These models consider hundreds of factors beyond traditional credit scores, enabling more nuanced risk assessment.
Speech Recognition: Voice assistants like Siri and Alexa use supervised learning trained on thousands of hours of recorded speech paired with transcriptions. The models learn to map audio patterns to words and can transcribe new speech with impressive accuracy.
Image Classification: Facebook automatically tags friends in photos using models trained on billions of labeled face images. The model learned distinctive facial features from labeled examples and can now identify individuals in new photos.
Sentiment Analysis: Companies analyze customer reviews using models trained on text labeled with sentiment (positive, negative, neutral). This helps businesses understand customer satisfaction, monitor brand reputation, and identify areas for improvement.
Advantages of Supervised Learning
Supervised learning offers several compelling benefits:
Clear Objectives: You know exactly what you want to predict, making it straightforward to evaluate success. Either the model correctly predicts the label or it doesn’t.
Strong Performance: When sufficient labeled data is available, supervised learning often achieves excellent accuracy. The direct feedback from labels enables efficient learning.
Well-Established Methods: Decades of research have produced robust, proven algorithms with extensive tooling and documentation. Solutions to common problems are well understood.
Measurable Results: Standard metrics (accuracy, precision, recall, F1 score, mean squared error) make it easy to compare models and track improvement.
Actionable Predictions: The outputs are directly useful—you get specific predictions you can act on, whether it’s classifying an email as spam or predicting a house price.
Limitations of Supervised Learning
Despite its power, supervised learning has significant constraints:
Requires Labeled Data: Creating labeled datasets is often expensive and time-consuming. Medical images need expert radiologists to label them. Legal documents need lawyers. Specialized domains may lack sufficient labeled data entirely.
Label Quality Matters: If labels are incorrect or inconsistent, the model learns the wrong patterns. Garbage in, garbage out. Even small percentages of mislabeled data can significantly impact performance.
Limited to Defined Tasks: The model only learns what it’s explicitly trained for. A model trained to identify cats and dogs cannot identify birds unless retrained with bird examples.
Doesn’t Discover New Patterns: Supervised learning finds patterns that predict known labels but doesn’t discover unexpected structures or relationships in data that weren’t part of the labeling scheme.
Static Knowledge: The model’s knowledge is frozen at training time. It doesn’t continue learning from new experiences after deployment unless explicitly retrained.
Can Perpetuate Biases: If training data reflects societal biases, the model learns and amplifies those biases. Hiring models trained on historically biased data may discriminate similarly.
Unsupervised Learning: Discovering Hidden Patterns
If supervised learning is like learning with a teacher, unsupervised learning is like exploring without guidance. The algorithm must find structure and patterns in data without being told what to look for.
How Unsupervised Learning Works
In unsupervised learning, the algorithm receives input data without corresponding labels or correct answers. The system must discover inherent structure, patterns, groupings, or relationships in the data independently.
This is considerably more challenging than supervised learning. Without explicit goals or feedback about correct answers, the algorithm must make assumptions about what constitutes interesting or meaningful patterns.
The learning process typically involves:
- Analyze the data: Examine characteristics, distributions, and relationships
- Identify patterns: Find natural groupings, correlations, or structures
- Create representations: Organize or transform the data to highlight discovered patterns
- Validate findings: Assess whether discovered patterns are meaningful and useful
Think of organizing a collection of photographs without any labels. You might notice some photos were taken outdoors and others indoors, some feature people and others don’t, some are landscapes and others are close-ups. You’re discovering natural groupings without anyone telling you what categories to use.
Major Types of Unsupervised Learning
Unsupervised learning encompasses several distinct approaches:
Clustering: Finding Natural Groups
Clustering algorithms divide data into groups where items within each group are more similar to each other than to items in other groups.
K-Means Clustering: Divides data into K groups by iteratively assigning points to the nearest cluster center and updating centers. Simple and efficient but requires specifying the number of clusters in advance.
Hierarchical Clustering: Builds a tree of clusters, allowing you to see relationships at different granularities. Doesn’t require pre-specifying cluster count but can be computationally expensive.
DBSCAN: Identifies clusters of arbitrary shape based on density, also finding outliers. Good for non-spherical clusters but sensitive to parameter choices.
Common clustering applications:
Customer Segmentation: Retailers cluster customers based on purchasing behavior, demographics, and engagement patterns to create targeted marketing campaigns. A company might discover segments like “budget-conscious families,” “premium seekers,” and “impulse buyers” without predefining these categories.
Document Organization: News aggregators cluster articles by topic without predefined categories. The system might automatically group articles about technology, politics, sports, and entertainment based on content similarity.
Anomaly Detection: Clustering helps identify unusual patterns. Points that don’t belong to any cluster are potential anomalies—fraudulent transactions, manufacturing defects, or network intrusions.
Image Segmentation: In computer vision, clustering groups pixels with similar colors or textures, helping identify distinct objects or regions in images without manual annotation.
Dimensionality Reduction: Simplifying Complexity
Dimensionality reduction techniques compress high-dimensional data into fewer dimensions while preserving important information. This serves multiple purposes: visualization, noise reduction, and computational efficiency.
Principal Component Analysis (PCA): Finds directions of maximum variance in data and projects onto these principal components. The most widely used dimensionality reduction technique.
t-SNE: Creates low-dimensional representations that preserve local structure, excellent for visualization. Often used to visualize high-dimensional data in 2D or 3D.
Autoencoders: Neural networks that learn compressed representations of data by training to reconstruct inputs. Can capture complex non-linear relationships.
Common dimensionality reduction applications:
Data Visualization: You cannot visualize 100-dimensional data directly, but dimensionality reduction can project it into 2D or 3D for visualization while maintaining meaningful relationships. Researchers use this to explore gene expression data, document collections, or customer behavior.
Feature Extraction: Reduce thousands of raw features to dozens of meaningful derived features, improving efficiency and sometimes performance. In image processing, this might compress thousands of pixel values into hundreds of higher-level features.
Noise Reduction: By focusing on principal components and discarding minor variations, dimensionality reduction can filter noise from data, like removing background noise from audio signals.
Compression: Store or transmit data more efficiently by representing it with fewer dimensions. This is similar to how JPEG compresses images—transforming data to a different representation that captures essential information with less space.
Association Rule Learning: Finding Relationships
Association rule learning discovers interesting relationships between variables in large datasets, often expressed as “if-then” rules.
Market Basket Analysis: Retailers analyze purchase data to find products frequently bought together. The classic example: “customers who buy diapers often buy beer” (actually found in real data). This informs product placement, promotions, and recommendations.
Apriori Algorithm: Identifies frequent itemsets and generates association rules based on support (how often items appear together) and confidence (how often the rule is true).
Web Usage Mining: Websites analyze clickstream data to understand common navigation patterns, informing site design and content organization.
Anomaly Detection: Spotting the Unusual
While clustering can identify outliers, dedicated anomaly detection algorithms specifically focus on finding unusual patterns.
Isolation Forest: Isolates anomalies by randomly partitioning data—anomalies are easier to isolate and require fewer partitions.
One-Class SVM: Learns a boundary around normal data; anything outside is considered anomalous.
Statistical Methods: Flag points that deviate significantly from expected distributions.
Applications include:
Fraud Detection: Identify unusual transaction patterns that may indicate fraud—unexpected locations, unusual amounts, atypical timing.
Network Security: Detect abnormal network traffic that might indicate intrusions, malware, or DDoS attacks.
Manufacturing Quality Control: Identify defective products by detecting anomalous measurements or sensor readings.
Healthcare Monitoring: Flag unusual patient vital signs or test results that may indicate medical emergencies or errors.
Real-World Unsupervised Learning Applications
Recommendation Systems: Netflix and Spotify use unsupervised learning to discover latent factors explaining user preferences. They cluster users with similar tastes and content with similar characteristics, enabling recommendations without explicit labels about what people will enjoy.
Genomics Research: Scientists cluster genes based on expression patterns to discover previously unknown gene functions and relationships. This has led to insights about disease mechanisms and potential treatments.
Cybersecurity: Security systems establish baselines of normal network behavior using unsupervised learning, then flag deviations as potential threats. This catches novel attacks that signature-based systems would miss.
Market Research: Companies analyze customer survey responses and social media data using unsupervised learning to discover emerging trends, sentiment patterns, and customer concerns they weren’t explicitly looking for.
Astronomy: Astronomers use clustering to categorize celestial objects and dimensionality reduction to analyze multi-spectral data, leading to discoveries of new object types and phenomena.
Advantages of Unsupervised Learning
Unsupervised learning offers unique benefits:
No Labeling Required: The most significant advantage—you don’t need expensive, time-consuming labeling. You can work with raw data directly.
Discovers Unknown Patterns: Can reveal unexpected structures and relationships that humans didn’t anticipate or think to look for.
Handles Complex Data: Can process high-dimensional data and find meaningful low-dimensional representations.
Flexible Exploration: Enables open-ended exploration of data without predefined goals or hypotheses.
Scales with Data: Can leverage massive amounts of unlabeled data that would be impractical to label.
Limitations of Unsupervised Learning
Unsupervised learning also faces challenges:
Ambiguous Objectives: Without clear goals, it’s difficult to evaluate success. Are the discovered patterns meaningful or just noise?
Interpretation Challenges: Results often require domain expertise to interpret. A clustering algorithm creates groups, but understanding what those groups represent requires human insight.
Parameter Sensitivity: Many algorithms require parameter tuning (like number of clusters), and results can vary dramatically with different settings.
No Guarantees: There’s no guarantee that discovered patterns are useful for your actual needs. The algorithm finds what’s statistically interesting, which may not align with what’s practically valuable.
Evaluation Difficulty: Measuring quality is subjective. Unlike supervised learning where you can calculate accuracy against known labels, unsupervised learning lacks objective performance metrics.
Reinforcement Learning: Learning Through Experience
Reinforcement learning takes a completely different approach. Instead of learning from a static dataset, an agent learns by interacting with an environment and receiving feedback about its actions.
How Reinforcement Learning Works
Reinforcement learning is inspired by behavioral psychology—how animals and humans learn through rewards and punishments. The framework involves:
Agent: The learner or decision-maker (e.g., a robot, game-playing AI, or autonomous vehicle)
Environment: The world the agent interacts with (e.g., a physical space, game board, or market)
State: The current situation of the environment (e.g., robot’s position, game configuration, or market conditions)
Actions: Choices available to the agent (e.g., move forward, place a game piece, buy or sell)
Rewards: Feedback about action quality (e.g., +1 for good moves, -1 for bad moves)
Policy: The agent’s strategy for choosing actions—what the agent is learning
The learning process:
- Observe state: The agent perceives its current situation
- Choose action: Based on its current policy, the agent selects an action
- Receive reward: The environment provides feedback (positive or negative)
- Update policy: The agent adjusts its strategy to increase future rewards
- Repeat: Continue interacting and learning
The agent doesn’t know the best actions initially. It must explore different options, discover which actions lead to rewards, and gradually develop an effective policy through trial and error.
This differs fundamentally from supervised learning, where correct answers are provided. In reinforcement learning, the agent must figure out what works through experience. The reward signal provides guidance but doesn’t specify exactly what action to take.
Key Concepts in Reinforcement Learning
Several important concepts shape how reinforcement learning works:
Exploration vs. Exploitation
The agent faces a crucial dilemma: should it exploit what it currently knows works (taking actions it knows give rewards) or explore new actions that might work even better?
Too much exploitation means the agent might miss better strategies. Too much exploration wastes time on inferior actions. Effective reinforcement learning balances both—exploring enough to find good strategies while exploiting known good actions to maximize rewards.
Common approaches include epsilon-greedy (explore randomly with small probability), upper confidence bounds (prefer actions with uncertain rewards), and sophisticated methods that decay exploration over time.
Credit Assignment
When a sequence of actions leads to a reward, which actions deserve credit? In chess, winning the game results from many moves—how much did each contribute?
This temporal credit assignment problem is central to reinforcement learning. Algorithms must determine which past actions were responsible for eventual rewards, even when feedback is delayed.
Methods like temporal difference learning and Monte Carlo approaches tackle this differently, updating value estimates based on immediate versus cumulative rewards.
Discount Factors
Should the agent prioritize immediate rewards or long-term gains? A discount factor determines how much the agent values future rewards versus immediate ones.
With high discount (close to 1), the agent considers long-term consequences. With low discount (close to 0), it focuses on immediate rewards. The right balance depends on the problem—financial trading might require longer-term thinking than navigating a simple maze.
Value Functions and Q-Learning
Value functions estimate how good particular states or state-action pairs are. Two main types:
State value function V(s): Expected cumulative reward from state s
Action-value function Q(s,a): Expected cumulative reward from taking action a in state s
Q-learning, a popular reinforcement learning algorithm, learns Q-values for all state-action pairs, enabling the agent to choose actions that maximize expected rewards.
Deep Q-Networks (DQN) combine Q-learning with deep neural networks, enabling reinforcement learning to handle complex environments with high-dimensional state spaces.
Policy Gradient Methods
Instead of learning value functions, policy gradient methods directly learn the policy—the mapping from states to actions. These methods optimize the policy to maximize expected rewards.
This approach works well when the action space is large or continuous (e.g., robot movements) where enumerating all possible actions is impractical.
Real-World Reinforcement Learning Applications
Reinforcement learning has achieved remarkable successes in recent years:
Game Playing: DeepMind’s AlphaGo defeated the world champion in Go, a game with more possible positions than atoms in the universe. AlphaZero learned to play chess, shogi, and Go at superhuman levels purely through self-play, with no human guidance beyond the rules. OpenAI’s Dota 2 bot defeated professional players in a complex, real-time strategy game.
Robotics: Robots use reinforcement learning to learn manipulation tasks like grasping objects, assembling parts, or navigating environments. Boston Dynamics’ robots develop locomotion strategies through reinforcement learning combined with classical control. Industrial robots optimize assembly processes by learning from experience.
Autonomous Vehicles: Self-driving cars use reinforcement learning to learn driving policies, making decisions about acceleration, braking, and steering based on sensor inputs and traffic conditions. The vehicles improve by accumulating driving experience.
Resource Management: Google uses reinforcement learning to optimize data center cooling, reducing energy consumption by 40%. Reinforcement learning manages power grids, optimizes traffic lights to reduce congestion, and schedules complex manufacturing operations.
Finance: Trading algorithms use reinforcement learning to develop strategies, learning from market feedback which trades are profitable. Portfolio management systems optimize asset allocation based on returns and risk.
Healthcare: Reinforcement learning personalizes treatment plans, learning from patient responses which interventions work best. It optimizes medication dosages, schedules, and treatment sequences.
Recommendation Systems: Companies like YouTube and TikTok use reinforcement learning to optimize content recommendations, learning from user engagement which content keeps people watching.
Natural Language Processing: ChatGPT and similar language models are fine-tuned using reinforcement learning from human feedback (RLHF), where human preferences serve as rewards to align model behavior with desired outcomes.
Advantages of Reinforcement Learning
Reinforcement learning offers distinctive strengths:
Learns from Interaction: Doesn’t require pre-labeled datasets—learns from experience in the environment.
Handles Sequential Decisions: Excels at problems requiring long sequences of decisions where current actions affect future states.
Discovers Novel Strategies: Can develop approaches humans never considered, sometimes finding superhuman solutions.
Adapts to Changes: Continues learning from new experiences, adapting to evolving environments.
Optimizes for Goals: Directly optimizes for desired outcomes (maximizing rewards) rather than matching labeled examples.
Limitations of Reinforcement Learning
Reinforcement learning also faces significant challenges:
Sample Inefficiency: Often requires enormous amounts of experience to learn effectively. AlphaGo played millions of games during training. This is impractical when real-world interaction is expensive or dangerous.
Exploration Challenges: In complex environments, the agent might never discover effective strategies through random exploration. Guiding exploration is difficult.
Reward Design Complexity: Specifying good reward functions is surprisingly difficult. Poorly designed rewards lead to agents gaming the system—achieving high rewards in unintended ways.
Computational Demands: Training sophisticated reinforcement learning agents requires substantial computational resources, often taking days or weeks even on powerful hardware.
Safety Concerns: During learning, agents make mistakes. In physical systems or critical applications, these mistakes can be dangerous or costly.
Difficulty of Credit Assignment: Determining which actions led to rewards remains challenging, especially with long sequences and sparse rewards.
Limited Transferability: Agents trained in one environment often perform poorly in even slightly different environments, limiting generalization.
Comparing the Three Approaches: A Comprehensive Analysis
To solidify understanding, let’s compare these approaches across multiple dimensions:
| Dimension | Supervised Learning | Unsupervised Learning | Reinforcement Learning |
|---|---|---|---|
| Data Requirement | Labeled data (inputs + correct outputs) | Unlabeled data (inputs only) | Environment interaction + reward signals |
| Learning Signal | Correct answers provided by labels | Inherent data structure | Rewards/penalties from environment |
| Primary Goal | Predict outputs for new inputs | Discover patterns and structure | Learn optimal behavior policy |
| Feedback Type | Direct: exact correct answer | None: find your own patterns | Indirect: quality of outcomes |
| Common Tasks | Classification, regression, prediction | Clustering, dimensionality reduction, anomaly detection | Control, optimization, sequential decision-making |
| Evaluation | Objective metrics (accuracy, error) | Subjective interpretation, domain-dependent | Cumulative reward over time |
| Data Efficiency | Moderate: needs labeled examples | High: uses raw data | Low: needs many interactions |
| Human Involvement | High: labeling data | Low: minimal supervision | Moderate: designing rewards |
| Best For | Well-defined prediction problems with labeled data | Exploratory analysis, unknown patterns | Sequential decisions, optimization, adaptation |
| Example Problems | Spam detection, image recognition, price prediction | Customer segmentation, data visualization, outlier detection | Game playing, robotics, resource allocation |
| Training Complexity | Moderate: straightforward optimization | Low to moderate: convergence can be tricky | High: complex optimization, exploration |
| Deployment Considerations | Static model, periodic retraining | Results guide analysis/decisions | Continuous learning possible |
| Interpretability | Variable: depends on algorithm | Often difficult: patterns aren’t labeled | Very difficult: complex policies |
Hybrid Approaches: Best of Multiple Worlds
In practice, many real-world systems combine multiple learning approaches:
Semi-Supervised Learning: Uses small amounts of labeled data with large amounts of unlabeled data. The model learns from labels but also discovers structure in unlabeled data, improving performance beyond what labeled data alone would achieve. This addresses the expensive labeling problem while maintaining some supervision.
Self-Supervised Learning: Creates supervisory signals from the data itself. For example, language models predict the next word in a sentence—the text provides both input and target. Image models might predict missing parts of images. This enables learning from vast unlabeled datasets.
Transfer Learning: Models trained on one task (often using supervised learning) are adapted to different but related tasks, sometimes using reinforcement learning or unsupervised learning for adaptation. This leverages knowledge from data-rich domains to data-poor ones.
Hierarchical Reinforcement Learning: Combines reinforcement learning at multiple levels—higher levels learn strategies, lower levels learn basic skills. This improves sample efficiency and enables learning complex behaviors.
Curiosity-Driven Learning: Combines reinforcement learning with unsupervised learning, where agents are rewarded for discovering novel patterns or states, encouraging systematic exploration.
Choosing the Right Approach: Decision Framework
How do you determine which type of machine learning to use? Consider these factors:
Question 1: What Data Do You Have?
Labeled data available: Supervised learning is typically the best choice. If you have input-output pairs, why not use them?
Only unlabeled data: Unsupervised learning is your option. Look for clustering, dimensionality reduction, or pattern discovery.
Can interact with environment: Reinforcement learning becomes viable if you can try actions and observe outcomes.
Small labeled + large unlabeled: Consider semi-supervised learning to leverage both.
Question 2: What’s Your Goal?
Predict specific outcomes: Supervised learning excels at prediction—classification or regression.
Discover unknown patterns: Unsupervised learning explores without predefined objectives.
Optimize sequential decisions: Reinforcement learning handles decision sequences and control problems.
Understand data structure: Unsupervised learning reveals inherent organization and relationships.
Question 3: What Are Your Constraints?
Limited labeling budget: Unsupervised or reinforcement learning avoid labeling costs.
Safety-critical application: Supervised learning provides more predictable behavior; reinforcement learning’s trial-and-error can be dangerous.
Need interpretability: Some supervised methods (like decision trees) are more interpretable than reinforcement learning policies or unsupervised clusters.
Computational resources: Reinforcement learning often requires substantial computation; supervised learning is typically more efficient.
Real-time learning needed: Reinforcement learning can adapt online; supervised models typically require batch retraining.
Question 4: What’s Your Domain?
Prediction tasks with historical data: Supervised learning (medical diagnosis, credit scoring, demand forecasting)
Exploratory analysis: Unsupervised learning (market research, scientific discovery, data exploration)
Control and optimization: Reinforcement learning (robotics, game playing, resource management)
Recommendation systems: Hybrid approaches combining supervised, unsupervised, and reinforcement learning
Practical Examples Across All Three Types
Let’s examine specific scenarios showing how each approach solves similar problems differently:
Scenario 1: Understanding Customer Behavior
Supervised Learning Approach: Predict customer churn using historical data labeled with whether customers left or stayed. Train a classifier on features like usage patterns, billing history, and support interactions. Deploy the model to identify at-risk customers for retention campaigns.
Unsupervised Learning Approach: Cluster customers into segments based on behavior patterns without predefined categories. Discover natural groupings like “power users,” “casual users,” and “barely engaged.” Tailor marketing and product offerings to each segment.
Reinforcement Learning Approach: Learn an optimal policy for customer engagement—when to send offers, what content to recommend, how to price services. The agent tries different strategies and learns from customer responses (rewards) like purchases, engagement, or retention.
Scenario 2: Managing Traffic Flow
Supervised Learning Approach: Predict traffic congestion using historical traffic data labeled with congestion levels. Train a model on factors like time of day, weather, events, and historical patterns. Use predictions to inform drivers about expected conditions.
Unsupervised Learning Approach: Cluster traffic patterns to identify typical scenarios—rush hour patterns, weekend patterns, event-related patterns. Discover anomalous patterns that might indicate accidents or unusual events.
Reinforcement Learning Approach: Learn optimal traffic light timing policies. The agent controls traffic lights, receiving rewards for smooth traffic flow and penalties for congestion. Through trial and error, it learns timing strategies that minimize wait times and maximize throughput.
Scenario 3: Drug Discovery
Supervised Learning Approach: Predict molecular properties or drug effectiveness using labeled data from past experiments. Train models on molecular structures paired with measured properties. Screen new molecules by predicting which are likely to be effective.
Unsupervised Learning Approach: Cluster molecules by structural similarity to find families with related properties. Reduce dimensionality of chemical space for visualization and exploration. Discover unexpected relationships between structure and function.
Reinforcement Learning Approach: Learn to generate new molecular structures with desired properties. The agent proposes molecules (actions), receives rewards based on predicted effectiveness, and learns which structural modifications lead to better drugs.
Common Challenges and Solutions
Each learning type faces characteristic challenges with emerging solutions:
Supervised Learning Challenges
Challenge: Labeling is expensive and time-consuming
- Solution: Active learning (strategically select most informative examples to label), crowdsourcing, semi-supervised learning, transfer learning from pre-labeled datasets
Challenge: Class imbalance (rare positive examples)
- Solution: Resampling techniques, cost-sensitive learning, anomaly detection approaches, synthetic data generation
Challenge: Distribution shift (training data differs from deployment)
- Solution: Domain adaptation, continuous monitoring and retraining, robust models less sensitive to distribution changes
Unsupervised Learning Challenges
Challenge: Difficult to evaluate quality
- Solution: Domain expertise for interpretation, multiple algorithms for validation, visualization techniques, task-specific downstream evaluation
Challenge: Parameter tuning (e.g., number of clusters)
- Solution: Stability analysis across parameter ranges, silhouette scores and other quality metrics, hierarchical approaches that don’t require pre-specification
Challenge: Computational complexity with high-dimensional data
- Solution: Dimensionality reduction before clustering, approximation methods, distributed computing, efficient algorithms like mini-batch k-means
Reinforcement Learning Challenges
Challenge: Sample inefficiency requires massive interaction
- Solution: Model-based RL (learn environment model), transfer learning, curriculum learning (start with easier tasks), learning from demonstrations
Challenge: Reward design is difficult
- Solution: Inverse reinforcement learning (learn rewards from expert behavior), reward shaping, multi-objective optimization, human-in-the-loop refinement
Challenge: Exploration in complex environments
- Solution: Intrinsic motivation (curiosity-driven exploration), hierarchical RL, guided exploration using prior knowledge, count-based exploration bonuses
The Future: Emerging Trends and Directions
Machine learning continues evolving rapidly. Several trends are shaping the future:
Cross-Paradigm Integration
Future systems increasingly combine multiple learning types. Language models use self-supervised pre-training (unsupervised), task-specific fine-tuning (supervised), and human feedback optimization (reinforcement learning). This multi-stage approach leverages the strengths of each paradigm.
Meta-Learning and Few-Shot Learning
Learning to learn—developing models that can quickly adapt to new tasks with minimal examples. This addresses supervised learning’s data hunger and enables rapid adaptation across domains.
Causal Learning
Moving beyond correlation to understand causation. This helps models generalize better and enables reasoning about interventions and counterfactuals—critical for decision-making applications.
Continual Learning
Enabling models to learn continuously from new data without forgetting previously learned knowledge. This addresses the static nature of traditional supervised learning and the sample inefficiency of reinforcement learning.
Explainable and Interpretable AI
Making all learning types more transparent and understandable. This is crucial for high-stakes applications where understanding why a model made a decision matters as much as accuracy.
Efficient Learning
Reducing computational and data requirements through better algorithms, architectures, and training procedures. This democratizes access to machine learning and reduces environmental impact.
Conclusion: Choosing Your Path
Supervised learning, unsupervised learning, and reinforcement learning represent fundamentally different approaches to machine intelligence. Each has distinct strengths, limitations, and ideal applications:
Supervised learning excels when you have labeled data and clear prediction goals. It’s the workhorse of machine learning, powering most commercial applications from spam filters to medical diagnosis.
Unsupervised learning shines for exploratory analysis and pattern discovery when labels are unavailable or too expensive. It reveals hidden structures and enables working with vast amounts of unlabeled data.
Reinforcement learning tackles sequential decision-making and optimization through interaction. It enables agents to learn complex behaviors and discover novel strategies through experience.
Understanding these differences empowers you to choose appropriate approaches for your problems. In practice, many systems combine multiple paradigms, leveraging supervised learning’s efficiency, unsupervised learning’s exploratory power, and reinforcement learning’s adaptability.
As you continue your machine learning journey, you’ll develop intuition for which approach fits different scenarios. You’ll learn to recognize prediction problems suitable for supervised learning, exploratory questions calling for unsupervised methods, and control challenges requiring reinforcement learning.
The field continues evolving, with new algorithms, hybrid approaches, and applications emerging constantly. But these three fundamental paradigms—learning from labels, learning from structure, and learning from experience—provide the foundation for understanding both current systems and future developments.
Whether you’re a practitioner building machine learning systems, a business leader evaluating AI opportunities, or a curious learner exploring this transformative technology, grasping these core learning types equips you to navigate the machine learning landscape effectively. The key is matching the right tool to the task—understanding not just what each approach does, but when and why to use it.
The future of machine learning likely lies not in choosing one approach over others, but in intelligently combining them, creating systems that leverage supervised learning’s precision, unsupervised learning’s discovery, and reinforcement learning’s adaptability. Understanding all three gives you the complete toolkit for tackling the diverse challenges of artificial intelligence.