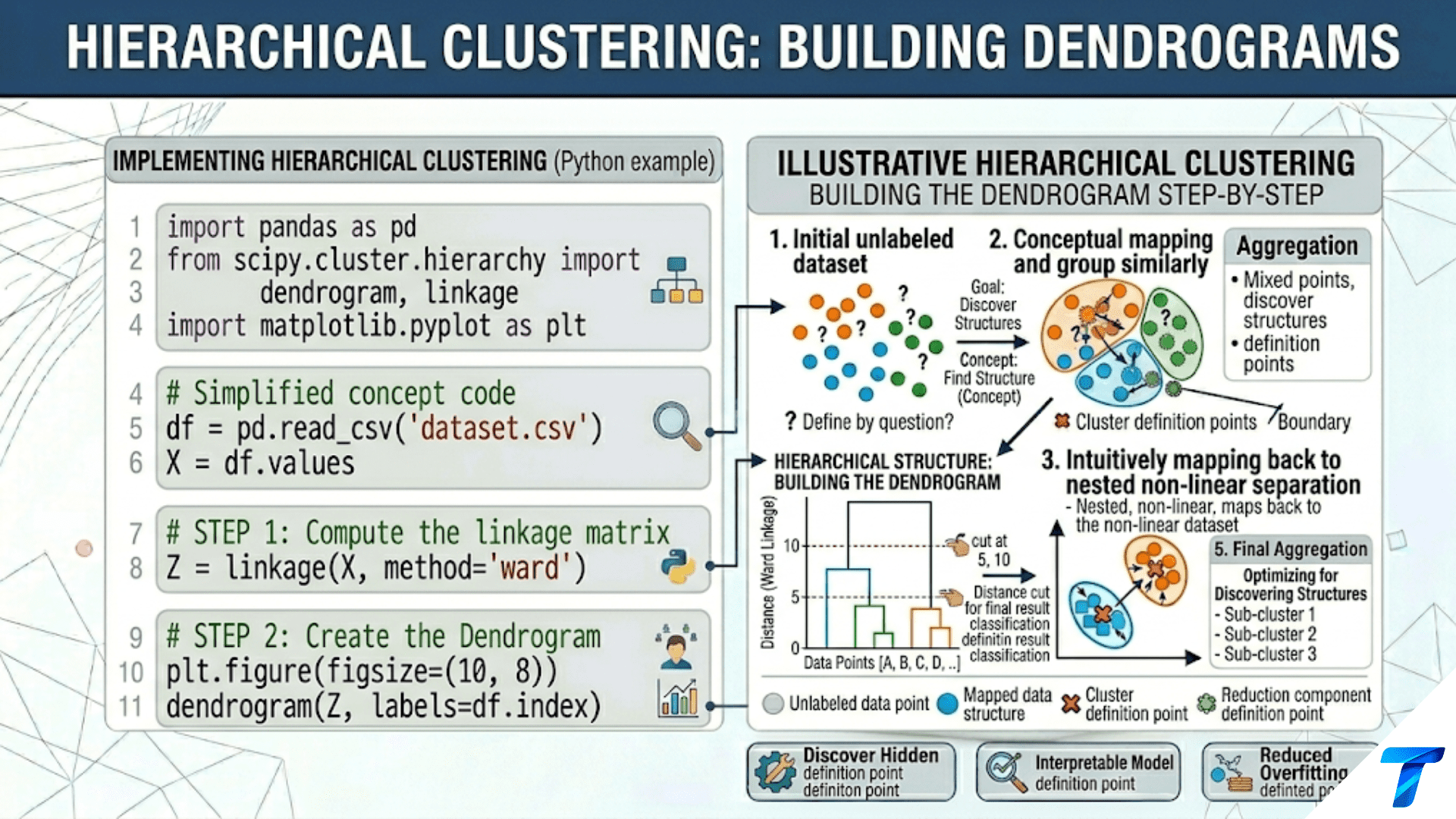
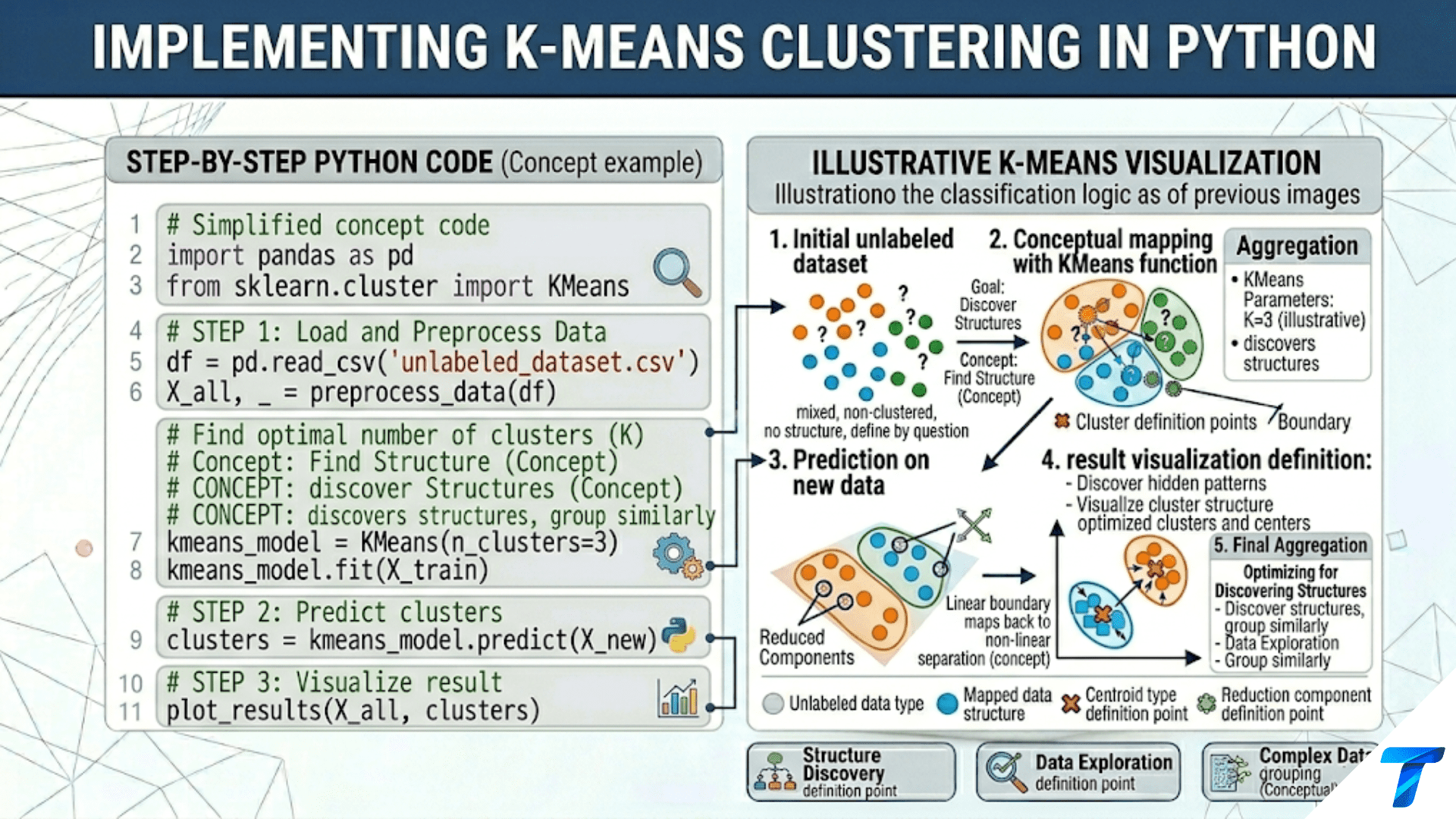
Introduction
As a software engineer, you have spent years building systems, writing clean code, and solving complex technical problems. Now you find yourself increasingly drawn to data science, whether because of the intellectual challenge, the business impact, or the explosive growth in the field. The question that keeps surfacing is whether you should make the transition and, more importantly, how to do it without abandoning the valuable experience you have accumulated.
The good news is that software engineers are uniquely positioned to transition into data science. You already possess many of the fundamental skills that data scientists use daily, from programming and debugging to system design and version control. Your engineering mindset, which emphasizes building robust and scalable solutions, translates remarkably well to the challenges of developing machine learning systems and data pipelines in production environments.
However, the transition is not without its challenges. Data science requires a different blend of skills that extends beyond pure software development. You will need to build statistical intuition, learn mathematical concepts that may not have been central to your engineering work, and develop the ability to extract insights from messy, real-world data. The analytical thinking that serves you well in engineering must expand to include statistical reasoning and domain expertise.
This comprehensive guide will walk you through every aspect of transitioning from software engineering to data science. You will learn which of your existing skills give you a competitive advantage, what new capabilities you need to develop, how to structure your learning journey, and practical strategies for making the career switch. By understanding both the similarities and differences between these fields, you can create a transition plan that builds on your strengths while systematically addressing your gaps.
Whether you are considering a complete career change or simply want to add data science capabilities to your engineering toolkit, this guide provides the roadmap you need to make informed decisions and take concrete action toward your goals.
Understanding the Landscape: Software Engineering vs Data Science
Before diving into the transition process, it is essential to understand what data science really entails and how it differs from software engineering. Many engineers hold misconceptions about what data scientists do daily, which can lead to surprises after making the switch.
Software engineering primarily focuses on building systems that perform specific functions reliably, efficiently, and at scale. As a software engineer, you translate requirements into working code, design architectures that can handle growth, optimize performance, and ensure that systems behave predictably. Your success is measured by whether the system works as intended, how quickly it runs, how easily it can be maintained, and how well it scales with increasing demand.
Data science, in contrast, centers on extracting insights and making predictions from data. Data scientists spend significant time exploring datasets to understand patterns, cleaning messy data to make it usable, building statistical models to capture relationships, and communicating findings to stakeholders who will make decisions based on those insights. The work is inherently more exploratory and uncertain than traditional software engineering. You might spend days investigating a dataset only to discover that it does not contain the signal you hoped to find.
The day-to-day work differs substantially between these roles. A software engineer might spend their morning reviewing code in a pull request, their afternoon debugging a production issue, and their evening designing a new microservice architecture. A data scientist, by contrast, might start their day exploring a new dataset in a Jupyter notebook, spend the afternoon running experiments with different modeling approaches, and end the day creating visualizations to explain their findings to the product team.
The outputs also differ significantly. Software engineers produce working systems, features, and tools that users interact with directly. The quality of their work is usually evident through whether the application functions correctly and performs well. Data scientists produce insights, recommendations, and predictive models. The value of their work often depends on whether stakeholders understand and act on their findings, which introduces an additional layer of communication and influence.
The technical stack shows both overlap and divergence. Both fields use version control systems like Git, work with APIs and databases, and write code in languages like Python. However, data scientists rely heavily on statistical libraries, machine learning frameworks, and data manipulation tools that may be unfamiliar to engineers focused on application development. Conversely, many data scientists lack the deep understanding of software architecture, testing frameworks, and production deployment that engineers take for granted.
The problem-solving approach differs in subtle but important ways. Software engineering problems typically have clear success criteria. Either the feature works or it does not. Either the system scales to handle the load or it does not. Data science problems are often more ambiguous. How accurate does a prediction need to be to provide business value? Which features should you include in your model? How do you balance model complexity against interpretability? These questions rarely have single correct answers.
Risk and uncertainty play different roles in each field. In software engineering, you strive to eliminate uncertainty through testing, monitoring, and defensive coding. In data science, you embrace uncertainty and try to quantify it through statistical methods. A data scientist might say a prediction has an eighty-five percent confidence interval, acknowledging the inherent uncertainty in any model-based forecast.
The career trajectories also diverge. Software engineers typically progress from junior to senior engineer, then potentially to staff engineer, principal engineer, or engineering manager. Data scientists follow a similar junior to senior path but may branch into specialized roles like machine learning engineer, research scientist, or analytics manager. The skills that make you successful at each level differ between the fields.
Understanding these differences helps set realistic expectations for your transition. You are not simply learning a new programming framework or switching to a different tech stack. You are entering a field with different objectives, methodologies, and success metrics. Recognizing this helps you prepare mentally for the shift and focus your learning on the areas that matter most.
Your Software Engineering Advantages
Despite the differences between software engineering and data science, your engineering background provides substantial advantages that will accelerate your transition. Recognizing and leveraging these strengths allows you to focus your learning energy on genuinely new concepts rather than relearning skills you already possess.
Your programming proficiency is perhaps your single greatest advantage. Many aspiring data scientists struggle for months or years to become comfortable with Python or R. You already write code fluently, understand programming concepts like functions and loops, debug systematically, and can read documentation to learn new libraries. This foundation allows you to quickly pick up data science tools like pandas and scikit-learn because you understand the underlying programming concepts.
Your understanding of software development best practices sets you apart from many data scientists who learned to code specifically for data analysis. You know how to write modular, reusable code. You understand the value of testing and have experience writing unit tests. You use version control effectively and can collaborate on code through pull requests. These practices, which many data scientists struggle to adopt, come naturally to you from your engineering background.
Your ability to build production systems is increasingly valuable as data science matures beyond pure research. Companies realize that a brilliant model that never makes it to production provides no business value. As a software engineer transitioning to data science, you can not only build models but also deploy them, monitor them, and integrate them into existing systems. This combination of skills is rare and highly sought after.
Your debugging skills translate directly to data science work. When a model performs poorly or produces unexpected results, you approach the problem systematically. You form hypotheses about what might be wrong, test those hypotheses, and methodically narrow down the source of the issue. This debugging mindset proves invaluable when investigating why a model fails to generalize or why data pipeline produces incorrect outputs.
Your comfort with databases and SQL gives you a significant head start. Data scientists spend substantial time querying databases to extract the data they need for analysis. Your ability to write efficient SQL queries, understand database schemas, and optimize query performance means you can focus on analysis rather than struggling with data extraction.
Your experience with APIs and web services is increasingly relevant as data science systems become more integrated with production applications. You understand REST principles, know how to handle authentication, and can debug API calls when things go wrong. This knowledge proves essential when deploying models as services or integrating with external data sources.
Your algorithmic thinking provides a foundation for understanding machine learning algorithms. When you learn about decision trees, you can leverage your understanding of tree data structures. When you encounter gradient descent, your knowledge of optimization algorithms helps you grasp the concept more quickly. The algorithmic foundations from your computer science background transfer remarkably well to machine learning.
Your systems thinking helps you see the bigger picture of how data science fits into organizational workflows. You understand that models are not isolated entities but components in larger systems. This perspective helps you build solutions that actually work in production environments rather than just performing well in research settings.
Your comfort with the command line and development tools accelerates your ability to work efficiently. You already know how to navigate file systems, run scripts, manage environments, and use productivity tools. These seemingly minor advantages add up to significant time savings as you learn data science.
Your experience working on teams and communicating about technical topics prepares you for the collaborative nature of data science. You know how to participate in technical discussions, explain your reasoning, and incorporate feedback. These soft skills prove just as important in data science as in engineering.
The key is recognizing these advantages not as reasons to feel overconfident but as building blocks that allow you to focus your learning on the genuinely new aspects of data science. You do not need to spend months learning to program or understanding version control. Instead, you can dive directly into statistics, machine learning algorithms, and domain-specific data analysis techniques.
Essential Skills You Need to Develop
While your engineering background provides a strong foundation, data science requires specific skills that may be new to you. Understanding what you need to learn and why it matters helps you prioritize your study and avoid getting overwhelmed by the breadth of the field.
Statistics forms the theoretical foundation of data science in ways that go beyond typical software engineering work. While you may have taken statistics courses in university, data science requires deeper and more applied statistical knowledge. You need to understand probability distributions not just in the abstract but in terms of what they reveal about real data. You must grasp concepts like confidence intervals, hypothesis testing, and statistical significance well enough to know when they apply and when they mislead.
The key statistical concepts you need include understanding different types of distributions and when data follows them, knowing how to test whether an observed pattern is statistically significant or likely due to chance, understanding bias and variance and how they affect model performance, grasping correlation versus causation and the dangers of confusing them, and learning experimental design principles for A/B testing and controlled experiments.
These concepts matter because data science involves making inferences from samples to populations, quantifying uncertainty in predictions, and distinguishing signal from noise. Without statistical grounding, you risk building models that overfit to training data, drawing incorrect conclusions from experiments, or making predictions without understanding their reliability.
Linear algebra becomes essential as you move into machine learning. Many machine learning algorithms are most naturally expressed and understood in terms of matrices and vectors. Neural networks, principal component analysis, and recommendation systems all rely heavily on linear algebra. You need to understand matrix operations, vector spaces, eigenvalues and eigenvectors, and matrix factorization techniques.
This does not mean you need to become a mathematician. Rather, you need enough linear algebra to understand what algorithms are doing under the hood and to read research papers or documentation that explain techniques in mathematical notation. Many engineers find that learning linear algebra in the context of actual machine learning applications proves more intuitive than abstract mathematical treatments.
Calculus, particularly derivatives and gradients, is crucial for understanding how machine learning models learn. Gradient descent, the optimization algorithm at the heart of most machine learning, relies on calculating derivatives to determine how to adjust model parameters. Understanding calculus helps you grasp why certain optimization algorithms work, how learning rates affect training, and what causes models to get stuck in local minima.
Again, you do not need to become an expert in advanced calculus. Focus on understanding derivatives, partial derivatives, the chain rule, and how these concepts apply to optimizing loss functions in machine learning models.
Data manipulation and analysis with libraries like pandas becomes a daily activity. While you know Python, you may not have used it extensively for data analysis. Learning to efficiently filter, transform, aggregate, and reshape data using pandas is essential. This includes understanding DataFrames and Series, indexing and selection operations, groupby operations for aggregation, merging and joining datasets, and handling missing data.
Pandas often feels quirky compared to other Python libraries because it was designed with R’s data frame model in mind. Investing time to learn pandas idioms and best practices pays dividends in your daily efficiency.
Data visualization requires both technical skills and design sensibility. You need to learn libraries like matplotlib and seaborn for creating plots in Python. More importantly, you need to develop judgment about which visualizations effectively communicate different types of information and how to design clear, honest visualizations that illuminate rather than obscure.
Effective visualization involves understanding when to use scatter plots versus line charts versus bar charts, how to choose appropriate color schemes, how to create visualizations that are accessible to people with color blindness, when to use logarithmic scales, and how to avoid misleading visualizations.
Machine learning algorithms form the core technical knowledge of data science. You need to understand the major algorithm families, what problems they solve, their strengths and limitations, and when to apply them. This includes supervised learning algorithms like linear regression, logistic regression, decision trees, random forests, gradient boosting, and neural networks, as well as unsupervised learning methods like clustering and dimensionality reduction.
Understanding these algorithms means knowing not just how to call them from a library but how they work internally, what assumptions they make about data, and how to diagnose when they fail. This deeper understanding helps you choose appropriate algorithms and debug unexpected behavior.
Feature engineering, the process of creating useful input variables for models from raw data, is where much of the art in data science resides. While software engineering has design patterns, data science has feature engineering patterns. You need to learn techniques like encoding categorical variables, creating interaction features, handling temporal features, scaling numerical features, and extracting features from text or images.
Domain knowledge proves surprisingly important in data science. Understanding the business context, industry dynamics, and subject matter helps you ask the right questions, engineer relevant features, and interpret results sensibly. While you may not start with domain knowledge in a new field, cultivating the habit of learning about the domains you work in distinguishes good data scientists from great ones.
Communication skills take on heightened importance in data science compared to pure software engineering. You need to explain complex analytical findings to non-technical stakeholders, create compelling visualizations and presentations, write clear documentation, and translate business problems into analytical questions. Your engineering background helps with technical communication, but you need to expand your communication toolkit to include storytelling with data.
Experimentation and A/B testing methodology becomes crucial if you work on products. Understanding how to design experiments, choose sample sizes, account for multiple testing, and interpret results correctly requires both statistical knowledge and practical experience.
These skills form the essential toolkit for data science work. You do not need to master everything before starting your transition, but understanding what you eventually need to learn helps you create a structured learning path.
Creating Your Learning Roadmap
With clarity about what you need to learn, the next step is creating a structured learning plan that builds skills systematically rather than jumping randomly between topics. A well-designed roadmap balances theoretical understanding with practical application and prevents the overwhelming feeling of needing to learn everything at once.
Start with the mathematical foundations before diving into machine learning algorithms. This might feel slow initially, but it pays enormous dividends. Begin with statistics, focusing on descriptive statistics, probability distributions, hypothesis testing, and confidence intervals. Work through practical examples using real datasets rather than just reading about abstract concepts. The goal is intuitive understanding, not mathematical rigor.
For learning statistics, consider resources like the “Think Stats” book which teaches statistics using Python code, making it particularly accessible for engineers. Work through exercises that involve analyzing actual datasets so you develop a feel for how statistical concepts apply to real data.
Once you have basic statistical grounding, add linear algebra fundamentals. Focus on vectors, matrices, matrix operations, and eigenvalues. Learn these concepts in the context of machine learning applications rather than pure mathematics. Understanding how principal component analysis uses eigenvalues proves more motivating than abstract linear algebra theorems.
Khan Academy offers excellent linear algebra courses that build intuition through visualizations. Supplement this with linear algebra explanations in machine learning contexts to see why these concepts matter.
Add basic calculus focused on derivatives and optimization. You need to understand what a derivative represents, how to calculate simple derivatives, what gradients are, and how gradient descent works. This foundation makes learning about neural network training much clearer.
With mathematical foundations in place, begin exploring machine learning systematically. Start with supervised learning and simple algorithms like linear regression. Understanding linear regression deeply provides insights that transfer to more complex algorithms. Work through the process of loading data, splitting it into training and test sets, fitting a model, making predictions, and evaluating performance.
Use scikit-learn’s documentation and tutorials as your primary resource. The library is well-designed for learning, and its consistent API across algorithms makes it easy to experiment with different approaches. Build simple projects that apply linear regression to real datasets.
Progress to classification problems using logistic regression. This introduces new concepts like probability predictions, decision boundaries, and classification metrics. Understanding the difference between regression and classification, and how to evaluate each, is fundamental.
Move on to decision trees and ensemble methods like random forests and gradient boosting. These algorithms introduce new concepts like feature importance, overfitting prevention through ensembles, and hyperparameter tuning. Decision trees in particular are intuitive and help develop model interpretation skills.
Explore unsupervised learning through clustering and dimensionality reduction. K-means clustering provides an accessible introduction to unsupervised methods, while principal component analysis introduces dimensionality reduction. These techniques prove valuable for exploratory data analysis.
Throughout this learning journey, work with real datasets rather than toy examples. Kaggle provides thousands of datasets across diverse domains. Choose datasets that interest you personally, as intrinsic motivation sustains learning far better than forcing yourself through boring exercises.
Build projects that apply what you learn. After learning about classification, build a spam detector or sentiment analyzer. After learning about regression, build a price predictor. These projects serve multiple purposes. They reinforce your learning, create portfolio pieces, and reveal gaps in your understanding that pure studying misses.
Dedicate significant time to pandas and data manipulation. Most data science work involves cleaning and transforming data before any modeling happens. Work through the pandas documentation systematically, learning to perform common operations efficiently. Practice reshaping data, handling missing values, merging datasets, and aggregating by groups.
Learn data visualization through a combination of studying principles and practicing with libraries. Read about visualization theory from sources like Edward Tufte’s work or “The Visual Display of Quantitative Information.” Practice creating visualizations with matplotlib and seaborn, focusing on clarity and honesty in presentation.
Integrate statistical thinking throughout your learning. When you build models, think about what assumptions they make. When you see results, ask whether they could occur by chance. When you make predictions, quantify their uncertainty. This statistical perspective is what transforms you from an engineer who happens to use machine learning libraries into a data scientist.
Consider following a structured course or program to provide scaffolding and accountability. Fast.ai offers excellent free courses that teach through practical projects. The Georgia Tech Online Master’s in Analytics provides rigorous education while you work. Coursera, edX, and DataCamp offer numerous options at varying levels of depth and commitment.
Set aside regular, dedicated learning time rather than sporadic cramming. An hour each day proves more effective than marathon weekend sessions. Consistency builds momentum and allows your brain to consolidate learning between sessions.
Join study groups or find a learning partner. Explaining concepts to others and discussing approaches to problems deepens your understanding. Online communities like the fast.ai forums or local data science meetups provide opportunities to connect with other learners.
Document your learning journey through blog posts or notes. Writing about what you learn forces you to articulate your understanding clearly and reveals gaps in your knowledge. These artifacts also serve as portfolio pieces and demonstrate your commitment to learning.
Expect this learning process to take six to twelve months of consistent effort before you feel competent enough to pursue data science roles professionally. This timeline assumes spending several hours per week on focused learning. The goal is not to rush through material but to build deep, durable understanding.
Building Your Data Science Portfolio
As a software engineer, you understand the value of a strong portfolio. Your GitHub profile likely showcases your engineering work. Now you need to build a portfolio that demonstrates data science capabilities. The strategies differ slightly from engineering portfolios, as data science projects need to showcase analytical thinking and communication skills in addition to technical implementation.
Choose portfolio projects that demonstrate diverse skills rather than building variations of the same thing. Your portfolio should show you can handle regression problems, classification problems, and unsupervised learning. It should demonstrate work with structured data, text data, and perhaps image data. This breadth signals versatility to potential employers.
Select projects that tell a story and solve real problems. A project that predicts housing prices using standard datasets is fine as a learning exercise but does not stand out. A project that analyzes neighborhood characteristics to help homebuyers identify undervalued areas tells a more compelling story. The difference lies in framing the problem in business terms and showing how your analysis provides actionable insights.
Start each project by clearly defining the problem you aim to solve. Why does this problem matter? What decisions could someone make with your analysis? Who would benefit from solving this problem? This problem framing demonstrates business acumen and shows you think beyond just applying algorithms.
Document your exploratory data analysis thoroughly. Show how you explored the dataset, what patterns you discovered, what hypotheses you formed, and how you tested those hypotheses. This documentation reveals your analytical thinking process, which is often more impressive than the final model you build.
Explain your feature engineering decisions. What features did you create and why? How did you handle categorical variables? What transformations did you apply to numerical features? Feature engineering is where domain knowledge and creativity intersect, and demonstrating thoughtful feature engineering impresses data science interviewers.
Compare multiple modeling approaches in your projects. Build a simple baseline model, then try progressively more sophisticated approaches. Explain why each approach might work better or worse for your problem. This comparison demonstrates that you understand different algorithms and can make informed choices between them.
Include visualizations throughout your analysis. Use plots to explore data distributions, show relationships between variables, illustrate model performance, and communicate insights. High-quality visualizations signal that you can communicate findings effectively to non-technical audiences.
Discuss model performance honestly, including limitations. No model is perfect. Explaining where your model struggles and why shows maturity and critical thinking. Suggest how future work could address these limitations.
Deploy at least one project as a working application. Create a simple web interface using Streamlit or Flask that allows users to interact with your model. This demonstrates you can move beyond notebooks to create deployable systems, leveraging your software engineering background.
Write excellent README files for each project. Explain the problem, describe the data, summarize your approach, present key findings, and provide instructions for running the code. These READMEs should be comprehensive enough that someone could understand your project without reading the code.
Include technical depth where appropriate. Show that you understand the mathematics behind algorithms you use. Explain how you tuned hyperparameters and why. Demonstrate knowledge of statistical concepts by discussing confidence intervals, statistical significance, or cross-validation strategies.
Avoid tutorial projects that thousands of other people have completed identically. The Titanic dataset and Iris classification are useful for learning but do not differentiate your portfolio. Choose less common datasets or apply techniques to novel problems.
Consider contributing to open-source data science projects. Contributing bug fixes, documentation improvements, or small features to libraries like pandas or scikit-learn demonstrates collaborative skills and deep understanding of the tools. These contributions carry weight because they help the broader community.
Write blog posts explaining your projects or teaching concepts you have learned. Publishing on Medium, your personal blog, or dev.to increases your visibility and demonstrates communication skills. These posts also help you develop the ability to explain technical concepts clearly, which proves essential in data science roles.
Present your work at meetups or conferences if opportunities arise. Public speaking about your projects demonstrates confidence and communication ability. Local data science meetups often welcome presentations from people working on interesting projects.
Aim for three to five substantial portfolio projects that demonstrate different skills and approaches. Quality matters far more than quantity. A few excellent, well-documented projects make a stronger impression than dozens of rushed, poorly documented ones.
Update your portfolio as you learn new techniques. If you build a project early in your learning journey, consider revisiting it later to apply more sophisticated approaches. Showing evolution in your work demonstrates continuous learning and improvement.
Networking and Community Engagement
Transitioning careers requires more than just developing skills. You need to build connections in the data science community, learn about opportunities, and become visible to potential employers. Strategic networking accelerates your transition and opens doors that might otherwise remain closed.
Attend local data science meetups in your area. These gatherings bring together practitioners at various career stages and provide opportunities to learn about what data scientists actually do daily. Listen to presentations about real projects, ask questions, and introduce yourself to other attendees. Mention that you are transitioning from software engineering, as this often sparks interesting conversations about how your background prepares you for data science.
Participate actively in online communities. The data science subreddit, Cross Validated on Stack Exchange, and forums like fast.ai attract practitioners who enjoy discussing technical topics. Answer questions where you can, ask thoughtful questions about concepts you are learning, and engage in discussions. This participation builds your reputation and helps you learn from others’ experiences.
Follow data science practitioners and thought leaders on Twitter and LinkedIn. Many data scientists share insights, resources, and job opportunities through social media. Engage with their content thoughtfully by sharing your perspective or asking questions. This visibility can lead to valuable connections.
Contribute to discussions on Kaggle. Participate in competitions not necessarily to win but to learn and engage with other participants. Read kernel notebooks that others share, comment thoughtfully, and share your own approaches. The Kaggle community is generally welcoming and collaborative.
Join local chapters of professional organizations like Women in Machine Learning or Data Science Association chapters. These groups often organize events, workshops, and networking opportunities specifically designed to help people connect and learn.
Reach out directly to data scientists at companies you admire. Most people enjoy talking about their work and career paths. Send a brief, thoughtful message explaining that you are transitioning from software engineering to data science and would appreciate fifteen minutes of their time to learn about their experience. Be specific about what you hope to learn rather than asking vague questions like “How did you get into data science?”
Attend conferences when possible. While conferences can be expensive, they provide concentrated opportunities for learning and networking. Even attending virtually offers value through access to talks and online discussion forums. Events like PyData, Strata Data Conference, or domain-specific conferences in healthcare, finance, or other fields of interest expose you to current industry practices.
Connect with other people making similar transitions. Learning alongside peers provides motivation, accountability, and opportunities to share resources. Consider forming or joining a study group focused on data science learning.
Share your learning journey publicly. Write about projects you complete, concepts you find challenging, or resources you find helpful. This content helps others who are learning and demonstrates your commitment and growing expertise. It also makes you discoverable to potential employers or mentors.
Seek out mentorship opportunities. Some organizations offer formal mentorship programs matching aspiring data scientists with experienced practitioners. Even informal mentorship, where you periodically discuss your progress and get advice from someone further along in their data science career, proves invaluable.
Be helpful to others who are earlier in their journey. As you learn, share resources, answer questions, and offer encouragement. This generosity builds goodwill and often leads to unexpected opportunities. The data science community values people who contribute to collective learning.
Maintain your software engineering connections even as you build data science networks. Your engineering background is an asset, and some of the most interesting opportunities arise at the intersection of engineering and data science. Former colleagues may know about roles that need someone with both skill sets.
Attend company tech talks or panel discussions about data science. Many companies host public events to share their work and attract talent. These events provide insights into how different organizations approach data science and may lead to conversations with hiring managers.
Remember that networking is about building genuine relationships, not just collecting contacts. Focus on being helpful, curious, and authentic. People remember individuals who engage thoughtfully and offer value to conversations rather than those who simply promote themselves.
Navigating the Job Search
When you feel ready to pursue data science roles professionally, your software engineering background shapes your job search strategy. Understanding how to position yourself and which opportunities to pursue increases your chances of a successful transition.
Target roles that value your engineering background highly. Machine learning engineer positions often bridge data science and software engineering, requiring both model building skills and production deployment capabilities. These roles leverage your engineering strengths while allowing you to grow your data science skills. Similarly, data engineer roles with analytical components or positions focused on building data platforms may provide a smoother transition than pure research scientist roles.
Consider looking for data science roles at companies that value production-ready solutions over cutting-edge research. Many companies need data scientists who can deploy models and integrate them with existing systems more than they need researchers pushing the boundaries of algorithmic innovation. Your ability to write production code, understand system architecture, and debug complex issues is highly valuable in these contexts.
Look for opportunities at companies where you already have domain knowledge. If you have worked on fintech applications, pursuing data science roles in financial services gives you an advantage. Your understanding of the domain helps you ramp up more quickly and contribute sooner.
Tailor your resume to emphasize transferable skills while showing commitment to data science. Your software engineering experience demonstrates valuable capabilities, but you need to show that you have invested in learning data science specifically. Include your portfolio projects prominently, listing them with brief descriptions of the problem solved, techniques used, and results achieved. Quantify impact where possible.
In your resume summary or objective, explicitly state your transition. Something like “Software engineer with five years of experience building scalable systems, now transitioning to data science with focus on deploying machine learning models in production environments” clearly communicates your situation and unique value proposition.
Highlight projects, courses, or certifications that demonstrate your data science learning. List relevant coursework, online programs you have completed, or certifications you have earned. This shows deliberate investment in transitioning rather than casual interest.
Prepare to address the transition in interviews. You will likely be asked why you are moving from software engineering to data science. Craft a narrative that emphasizes genuine interest, specific aspects of data science that attract you, and how your background prepares you for success. Avoid framing it as simply wanting a change or being bored with engineering, as this raises concerns about commitment.
Practice explaining your portfolio projects in depth. Be prepared to discuss technical details of your approach, alternative methods you considered, challenges you faced, and lessons you learned. Data science interviews often involve deep dives into past projects to assess your thinking process and technical depth.
Prepare for technical interviews that may differ from software engineering interviews. Data science interviews often include statistical questions, machine learning algorithm explanations, case studies where you propose analytical approaches to business problems, and practical coding challenges involving data manipulation and analysis. Review common interview questions and practice explaining concepts clearly.
Be ready to demonstrate your thinking process. Many data science interviews include open-ended problems where interviewers want to see how you approach ambiguous situations. Practice thinking aloud, asking clarifying questions, and working through problems systematically.
Leverage your network for referrals. Applications submitted through internal referrals receive more attention than applications through general job boards. Reach out to connections you have made in the data science community and ask if they know of appropriate opportunities.
Consider contract or freelance work as a bridge. Taking on short-term projects builds experience, expands your portfolio, and may lead to full-time opportunities. Platforms like Toptal, Upwork, or specialized data science consulting networks connect freelancers with clients needing analytical work.
Be patient and persistent. Career transitions take time, and you may face rejections, especially early in your search. Each interview provides learning opportunities and helps you refine your approach. Use feedback to improve your interviewing skills and fill knowledge gaps.
Consider roles with titles like “data scientist” but also “machine learning engineer,” “analytics engineer,” “research engineer,” or “data platform engineer.” The boundaries between these roles blur, and many would provide excellent entry points for your transition.
Be open to taking a slight step back in seniority if necessary. If you are a senior software engineer, you might need to accept a mid-level data science role initially. Think of this as an investment that allows you to grow into senior data science roles faster than someone without your technical background.
Research companies thoroughly before applying. Understand what data science means in their context, what problems their data teams solve, and what technologies they use. Tailoring your application to each company’s specific needs dramatically increases your success rate compared to generic applications.
Making the Transition: Practical Considerations
Beyond skills and job searching, practical considerations affect how and when you make your transition. Thinking through these factors helps you create a realistic plan that fits your circumstances.
Evaluate your financial situation and create a transition plan that works for your reality. If you have sufficient savings, you might choose to leave your current role and focus full-time on learning data science and job searching. This accelerates your transition but carries financial risk. Alternatively, you might continue working while learning data science in evenings and weekends, which is slower but more secure financially.
Many engineers successfully transition while maintaining their current roles by dedicating consistent time outside work hours to learning. This requires discipline and time management but proves entirely feasible. Set aside specific times for studying, treat them as non-negotiable appointments, and protect this time from other commitments.
Consider whether your current company has data science opportunities. Internal transitions often prove easier than external ones because you already understand the business, have established credibility, and can leverage existing relationships. Talk to your manager about your interest in data science and explore whether you could gradually take on more analytical projects while maintaining your engineering responsibilities.
Some companies allow engineers to rotate through data science teams temporarily, providing invaluable learning opportunities and trial periods to see if you truly enjoy the work. Propose this if your company has rotation programs or seems open to professional development opportunities.
Look for hybrid opportunities that blend engineering and data science. Many organizations need people who can both build models and deploy them to production. Positioning yourself in these hybrid roles lets you transition gradually while leveraging your engineering strengths.
Time your transition thoughtfully based on your learning progress and market conditions. Do not rush into job searching before you feel ready, as unsuccessful interview experiences can damage your confidence. Conversely, do not wait for perfect mastery of every concept, as you learn enormously through actual work experience.
A reasonable signal that you are ready to start applying is having completed several substantial portfolio projects, feeling comfortable explaining machine learning concepts and statistical principles, being able to manipulate data efficiently with pandas, and successfully solving practice interview questions and case studies.
Prepare for the possibility that your first data science role might come with a pay cut compared to your software engineering compensation, especially if you are moving from a senior engineering role to a junior or mid-level data science role. View this as a temporary investment that positions you for long-term growth in a new field. As you gain data science experience, compensation typically increases rapidly.
Consider geographical factors in your transition. Some locations have many more data science opportunities than others. Cities like San Francisco, New York, Seattle, and Boston have concentrated data science job markets. Remote work has expanded opportunities, but many companies still prefer local candidates, especially for entry-level roles where mentorship is important.
Think about work-life balance during your transition. Learning data science while working full-time is demanding. Be realistic about what you can sustain without burning out. It is better to study consistently for an hour each day than to push yourself to exhaustion with unsustainable schedules.
Maintain your mental and physical health throughout the transition. Career changes are stressful, and adding intense learning on top of full-time work can strain your wellbeing. Exercise regularly, sleep adequately, and maintain social connections. These factors directly affect your learning efficiency and resilience during challenging moments.
Communicate with family or partners about your transition plans. They will be affected by the time you invest in learning and potential financial implications. Having their support and understanding makes the journey significantly easier.
Set realistic milestones and celebrate progress. Learning data science is a marathon, not a sprint. Acknowledge small victories like completing a course, finishing a project, or having a good interview experience. These celebrations maintain motivation during the inevitable periods of slow progress or frustration.
Common Pitfalls and How to Avoid Them
Engineers transitioning to data science often encounter predictable challenges. Recognizing these pitfalls helps you avoid or navigate them more effectively.
One common mistake is underestimating the importance of statistics. Engineers often want to jump directly into machine learning algorithms and model building without first developing statistical foundations. This leads to building models without understanding their assumptions, interpreting results incorrectly, or drawing invalid conclusions from data. Invest time in statistics early, even if it feels less exciting than coding machine learning models.
Another pitfall is focusing excessively on tools at the expense of concepts. Learning the latest deep learning framework is less important than understanding when and why to use deep learning. Tools change rapidly, but fundamental concepts endure. Build your learning on conceptual foundations first, then layer on tools and frameworks.
Many engineers make the mistake of only working with clean, prepared datasets. Real-world data science involves substantial time cleaning messy data, handling missing values, and resolving inconsistencies. Seek out projects with realistic, messy data to develop these essential skills.
Some engineers overemphasize prediction accuracy while ignoring model interpretability. In many business contexts, stakeholders need to understand why a model makes certain predictions. A slightly less accurate model that provides clear explanations often proves more valuable than a black-box model with marginally better performance. Develop appreciation for the interpretability versus accuracy tradeoff.
Neglecting communication skills undermines many otherwise talented data scientists. You might build brilliant models, but if you cannot explain your findings to non-technical stakeholders, your impact is limited. Practice explaining technical concepts to non-technical audiences, create clear visualizations, and develop storytelling skills around data.
Another common error is applying machine learning to problems that do not need it. Sometimes simple statistical analysis, business logic, or even manual rules solve problems more effectively than complex models. Develop judgment about when machine learning adds value and when simpler approaches suffice.
Some engineers become overwhelmed by the breadth of data science and try to learn everything simultaneously. This scattered approach leads to superficial knowledge across many topics without depth in any. Instead, build expertise systematically, mastering fundamentals before moving to advanced topics.
Imposter syndrome affects many people transitioning careers, and engineers moving to data science are no exception. You may feel behind because you are learning concepts that seem basic to experienced data scientists. Remember that your engineering background provides unique value, and everyone started where you are now. Focus on continuous improvement rather than comparing yourself to others.
Isolation during self-study can slow your progress and reduce motivation. Engage with learning communities, find study partners, and participate in discussions. Learning alongside others provides accountability, different perspectives, and emotional support during challenging periods.
Some engineers give up too quickly when faced with mathematical concepts that feel difficult. Statistics and linear algebra may require more effort than learning a new programming language, but they become accessible with persistent effort. Break down challenging topics into smaller pieces, find multiple explanations from different sources, and work through examples until concepts click.
Conclusion: Your Path Forward
Transitioning from software engineering to data science is a significant career move that requires dedication, strategic learning, and patience. However, your engineering background provides substantial advantages that position you for success. You bring valuable skills in programming, system design, debugging, and production deployment that many data scientists lack.
The journey begins with building mathematical and statistical foundations that may feel unfamiliar initially but become intuitive with practice. These foundations support your understanding of machine learning algorithms and statistical inference. Supplement theoretical learning with practical projects that apply concepts to real datasets and create portfolio pieces demonstrating your capabilities.
Structure your learning to build systematically from fundamentals to advanced topics rather than jumping randomly between concepts. Invest in understanding not just how to use tools but why they work and when they apply. This deeper understanding distinguishes competent practitioners from those who merely call library functions without comprehension.
Build a portfolio that showcases diverse skills through well-documented projects solving meaningful problems. Leverage your software engineering background by deploying models, creating applications, and demonstrating production-ready solutions. Communicate your work through excellent documentation, visualizations, and blog posts that establish your expertise and visibility.
Engage actively with the data science community through meetups, online forums, conferences, and social media. Build genuine relationships with practitioners who can offer advice, share opportunities, and provide insights into the field. These connections accelerate your learning and create pathways to opportunities.
Approach your job search strategically by targeting roles that value your engineering background, such as machine learning engineer or data scientist positions focused on deployment and production systems. Prepare thoroughly for interviews by practicing technical explanations, solving case studies, and articulating your unique value proposition as an engineer transitioning to data science.
Be patient with yourself throughout this transition. Building genuine competence takes time, and you will face moments of frustration and self-doubt. Progress comes from consistent effort over months, not from cramming or seeking shortcuts. Celebrate small victories and maintain perspective during setbacks.
Remember that this transition is not about abandoning your engineering expertise but about expanding your capabilities to include analytical and statistical skills that complement your technical foundation. The combination of strong engineering practices and data science knowledge is increasingly valuable as organizations recognize that successful data science requires both analytical insight and robust implementation.
Your path forward is clear. Begin building statistical foundations while working on practical projects. Document your learning and create portfolio pieces. Engage with the community and network strategically. When ready, pursue opportunities that leverage both your engineering background and developing data science skills. The transition requires effort and commitment, but the destination, a career combining technical depth with analytical insight and business impact is well worth the journey.
As you progress, you will discover that data science and software engineering are not separate fields but deeply interconnected domains. The best data scientists write excellent code, and increasingly, the best engineers understand data and statistical thinking. Your transition is not a leap into the unknown but rather an expansion of your professional identity to encompass a broader range of valuable skills. This growth benefits not only your career but also the organizations fortunate enough to employ someone who bridges these critical disciplines.