
Data Science is the foundation of Artificial Intelligence (AI), providing the tools and methodologies needed to extract insights from data and develop intelligent systems. At its core, data science encompasses a blend of statistical analysis, data manipulation, machine learning, and visualization techniques, all essential for building robust AI applications. By understanding data science fundamentals, you gain the skills necessary to handle and analyze data, select the right models, and create data-driven AI solutions.
This article covers the essential data science concepts needed for AI, from data preparation and feature engineering to model selection and evaluation. For beginners, this guide serves as a roadmap to building strong data science skills for AI applications. For those with experience, it provides a refresher on critical concepts that drive AI development.
Understanding the Data Science Workflow
The data science workflow is a systematic approach to solving problems with data. It guides data scientists through various stages, from defining the problem to deploying an AI model. Here’s an overview of each step:
- Define the Problem: Understanding the problem is the first and most crucial step. Before working with data, it’s essential to clarify the objective. This could be a classification task, such as identifying spam emails, or a regression task, like predicting housing prices. A clear problem definition helps guide the data science process and ensures you choose the appropriate methods and metrics.
- Collect and Explore Data: Once the problem is defined, the next step is data collection. Data can come from multiple sources, including databases, APIs, and real-time sensors. After collection, exploratory data analysis (EDA) helps uncover patterns, detect anomalies, and understand the data structure. Visualization tools like Matplotlib and Seaborn are valuable for identifying trends and relationships between variables.
- Data Cleaning and Preparation: Raw data often contains errors, missing values, or outliers that need to be addressed. Cleaning and preparing data are critical steps to ensure accuracy in the final model. This stage involves handling missing values, transforming data types, and encoding categorical variables for machine learning compatibility.
- Feature Engineering: Feature engineering involves creating new variables (features) from existing ones to improve model performance. It may include scaling numerical data, encoding categorical variables, or creating interaction terms. Effective feature engineering can make the difference between a good and a great model.
- Model Selection and Training: After preparing the data, it’s time to select a model. Different algorithms are suited for different tasks—classification, regression, clustering, etc. Choosing the right model involves understanding the data and the complexity of the problem. Training the model on a portion of the data allows it to learn patterns and make predictions.
- Evaluation and Tuning: Model evaluation assesses the performance of the trained model on test data, ensuring it generalizes well. Metrics like accuracy, precision, recall, and F1-score provide insights into its effectiveness. If necessary, hyperparameter tuning improves model performance by adjusting algorithm-specific settings.
- Deployment and Monitoring: The final step is deploying the model for real-world use, whether through an application or an API. Monitoring the model in production ensures it continues to perform well over time, particularly as new data or environmental changes occur.
This workflow provides a structured approach to building AI solutions, ensuring that models are accurate, efficient, and ready for deployment.
Essential Data Science Concepts for AI
Several foundational concepts in data science form the basis for building effective AI models. Here are some of the core concepts that are indispensable for AI development:
1. Statistics and Probability
Statistics and probability are critical for understanding data patterns, variability, and relationships between variables. In AI, statistical methods help assess data distributions, sample sizes, and model assumptions. Key statistical concepts include:
- Descriptive Statistics: Metrics like mean, median, mode, variance, and standard deviation summarize data, offering insights into its distribution.
- Probability Distributions: Understanding normal, binomial, and Poisson distributions aids in modeling and interpreting data variability.
- Hypothesis Testing: Hypothesis testing allows data scientists to determine whether relationships observed in data are statistically significant. Techniques like t-tests, chi-square tests, and ANOVA help verify these relationships.
- Bayesian Probability: Bayesian approaches update probabilities based on new evidence and are widely used in probabilistic modeling and decision-making in AI.
2. Linear Algebra and Calculus
Linear algebra and calculus are foundational for understanding how machine learning algorithms work, especially in deep learning. AI models often represent data as vectors and matrices, making linear algebra essential for tasks like matrix operations and transformations.
- Vectors and Matrices: AI data is typically represented as multidimensional arrays or matrices, with each row or column representing data points or features.
- Matrix Multiplication: Matrix multiplication is central to the operations in neural networks, where weights and inputs are multiplied to produce outputs.
- Derivatives and Gradients: In optimization algorithms like gradient descent, derivatives calculate the rate of change, guiding the model to minimize error during training.
- Eigenvalues and Eigenvectors: These concepts are used in dimensionality reduction techniques, such as Principal Component Analysis (PCA), which reduces the number of features while retaining essential data characteristics.
3. Data Preprocessing
Data preprocessing transforms raw data into a format suitable for machine learning models. This step is crucial because data quality affects model accuracy. Common preprocessing techniques include:
- Handling Missing Values: Missing values can be filled (imputed) with mean, median, or mode values, or in some cases, removed entirely.
- Normalization and Standardization: Scaling numerical features ensures that each feature contributes equally to the model. Normalization rescales data to a [0, 1] range, while standardization adjusts it to have a mean of 0 and standard deviation of 1.
- Encoding Categorical Variables: Categorical data must be converted into numerical format, typically using techniques like one-hot encoding or label encoding.
4. Feature Engineering
Feature engineering transforms or creates new features to enhance model performance. It involves domain knowledge, creativity, and experimentation to identify which features are most predictive for a given problem. Some key feature engineering techniques include:
- Polynomial Features: Creating polynomial features (e.g., square or cube of a variable) can capture non-linear relationships in the data.
- Interaction Features: Interaction features represent the combined effect of two or more variables, adding complexity to the model without increasing the data size.
- Binning: Continuous variables can be grouped into discrete bins, such as age ranges, which may improve model interpretability and performance.
- Feature Selection: Feature selection methods, such as recursive feature elimination (RFE) and Lasso regression, help identify the most relevant features, reducing dimensionality and improving model efficiency.
5. Machine Learning Algorithms
Machine learning algorithms form the backbone of AI, allowing models to learn patterns and make predictions. While there are numerous algorithms, some of the most commonly used ones in AI include:
- Linear Regression: A simple regression algorithm that predicts continuous values by fitting a linear relationship between input and output variables.
- Logistic Regression: A classification algorithm that predicts binary outcomes, often used for tasks like spam detection or medical diagnoses.
- Decision Trees and Random Forests: Decision trees split data into branches based on feature values, making predictions based on the resulting “leaves.” Random forests combine multiple decision trees to improve accuracy.
- k-Nearest Neighbors (k-NN): This algorithm classifies data points based on the classes of their nearest neighbors, making it ideal for classification tasks.
- Support Vector Machines (SVMs): SVMs create a hyperplane that separates data points into classes, commonly used for tasks that require high accuracy in complex datasets.
- Clustering (e.g., K-Means): Clustering groups similar data points into clusters, used in unsupervised learning for applications like customer segmentation.
Each algorithm has strengths and weaknesses, and selecting the right one depends on the nature of the data, the complexity of the problem, and the desired outcomes.
Data Visualization Techniques
Data visualization is crucial for data exploration, helping uncover patterns and insights that guide the modeling process. Visualization tools such as Matplotlib and Seaborn in Python allow data scientists to create informative charts and graphs, which aid in interpreting data and presenting findings effectively.
- Histograms: Show the distribution of numerical data, useful for identifying skewness, kurtosis, and outliers.
- Box Plots: Highlight the distribution, median, and potential outliers in a dataset, making it easier to identify variability.
- Scatter Plots: Display relationships between two continuous variables, helping to detect linear or non-linear trends.
- Heatmaps: Visualize the correlation matrix, showing relationships between features, which can help identify highly correlated variables.
Example of creating a simple histogram using Matplotlib:
import matplotlib.pyplot as plt
import pandas as pd
# Load sample data
data = pd.DataFrame({'scores': [80, 85, 90, 70, 75, 88, 92, 85, 78, 95]})
# Create histogram
plt.hist(data['scores'], bins=5, color='skyblue', edgecolor='black')
plt.xlabel('Scores')
plt.ylabel('Frequency')
plt.title('Score Distribution')
plt.show()Visualizations provide a better understanding of data distributions and relationships, making it easier to make informed decisions in data preprocessing and feature engineering.
Building Machine Learning Models
After preparing the data and selecting features, the next step is building machine learning models. The model you choose depends on the type of problem—classification, regression, clustering, etc. Here, we’ll focus on the basics of model building in Python using Scikit-Learn, a powerful library for machine learning.
Step 1: Splitting the Dataset
Before training a model, the data is typically divided into training and testing sets. This split allows you to train the model on one portion of the data and evaluate its performance on a separate set, ensuring the model generalizes well to unseen data.
from sklearn.model_selection import train_test_split
import pandas as pd
# Sample data (Assuming 'features' and 'target' are defined)
X = pd.DataFrame({'feature1': [1, 2, 3, 4, 5], 'feature2': [10, 20, 30, 40, 50]})
y = [0, 1, 0, 1, 0]
# Split data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)The train_test_split function randomly splits the data into 70% training and 30% testing (adjustable via test_size), ensuring the model’s performance is assessed on unseen data.
Step 2: Choosing a Model
Selecting a model depends on the nature of the problem. Here are a few popular algorithms and their typical applications:
- Classification: Logistic Regression, k-Nearest Neighbors, Decision Trees, Support Vector Machines.
- Regression: Linear Regression, Ridge Regression, Decision Trees.
- Clustering: K-Means, Hierarchical Clustering.
- Dimensionality Reduction: Principal Component Analysis (PCA).
For this example, we’ll use a Logistic Regression model, a common choice for binary classification tasks.
from sklearn.linear_model import LogisticRegression
# Initialize the model
model = LogisticRegression()
# Train the model on the training data
model.fit(X_train, y_train)Step 3: Making Predictions
Once the model is trained, you can use it to make predictions on new data, such as the test set. These predictions allow you to compare the model’s output to actual values and assess its accuracy.
# Make predictions on the test data
y_pred = model.predict(X_test)Model Evaluation Metrics
Model evaluation metrics are essential for understanding a model’s performance. Different metrics provide insights into various aspects of a model’s accuracy and reliability, and the choice of metric depends on the specific goals of your project.
1. Accuracy
Accuracy is the most straightforward metric, measuring the percentage of correctly predicted instances out of all predictions. However, accuracy alone can be misleading for imbalanced datasets, where one class is more common than others.
- Formula
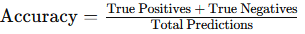
from sklearn.metrics import accuracy_score
# Calculate accuracy
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)2. Precision and Recall
Precision and Recall provide insights into a model’s performance, particularly for imbalanced datasets.
- Precision: Measures the proportion of positive predictions that are actually correct. It’s valuable when false positives are costly (e.g., spam detection).
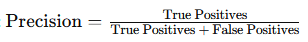
Recall: Measures the proportion of actual positives that the model correctly identifies, helpful when missing positive cases is costly (e.g., disease detection).
- Formula
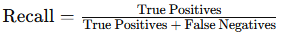
from sklearn.metrics import precision_score, recall_score
# Calculate precision and recall
precision = precision_score(y_test, y_pred)
recall = recall_score(y_test, y_pred)
print("Precision:", precision)
print("Recall:", recall)3. F1-Score
The F1-Score is the harmonic mean of precision and recall, balancing the two metrics. It’s particularly useful when you need a single metric that accounts for both false positives and false negatives.
- Formula
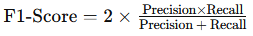
from sklearn.metrics import f1_score
# Calculate F1-Score
f1 = f1_score(y_test, y_pred)
print("F1-Score:", f1)4. ROC-AUC Score
The ROC-AUC Score (Receiver Operating Characteristic – Area Under Curve) evaluates the model’s ability to distinguish between classes across different probability thresholds. A higher ROC-AUC score indicates better discriminatory power.
from sklearn.metrics import roc_auc_score
# Calculate ROC-AUC score
roc_auc = roc_auc_score(y_test, model.predict_proba(X_test)[:, 1])
print("ROC-AUC Score:", roc_auc)The ROC-AUC score is widely used for binary classification tasks and is especially valuable for comparing different models.
Hyperparameter Tuning
Hyperparameters are settings that influence the behavior of machine learning algorithms. Unlike model parameters, which are learned during training, hyperparameters are set manually and impact the algorithm’s performance. Tuning these hyperparameters is essential to optimize model performance.
Grid Search
Grid search is a brute-force approach where all possible combinations of hyperparameters are tested. This method can be time-consuming, but it’s thorough.
from sklearn.model_selection import GridSearchCV
# Define parameter grid
param_grid = {
'C': [0.1, 1, 10], # Regularization strength for logistic regression
'solver': ['liblinear', 'lbfgs']
}
# Initialize grid search
grid_search = GridSearchCV(LogisticRegression(), param_grid, cv=5)
grid_search.fit(X_train, y_train)
# Display the best parameters
print("Best Parameters:", grid_search.best_params_)
print("Best Score:", grid_search.best_score_)Random Search
Random search is a faster alternative where random combinations of hyperparameters are tested. It’s efficient and often yields good results in a fraction of the time needed for grid search.
from sklearn.model_selection import RandomizedSearchCV
from scipy.stats import uniform
# Define parameter distribution
param_dist = {
'C': uniform(loc=0.1, scale=10)
}
# Initialize random search
random_search = RandomizedSearchCV(LogisticRegression(), param_distributions=param_dist, n_iter=10, cv=5)
random_search.fit(X_train, y_train)
# Display the best parameters
print("Best Parameters:", random_search.best_params_)
print("Best Score:", random_search.best_score_)Hyperparameter tuning is crucial for optimizing model performance, and both grid and random search provide valuable strategies for testing parameter combinations.
Model Optimization Techniques
- Cross-Validation: Cross-validation divides the dataset into multiple folds, training and validating the model on each fold. This approach provides a more accurate assessment of model performance and reduces the risk of overfitting.
- Feature Scaling: Scaling features to a similar range can improve model performance, especially for algorithms like k-Nearest Neighbors (k-NN) and Support Vector Machines (SVMs).
- Feature Selection: Reducing the number of features can enhance model efficiency and accuracy by removing irrelevant or redundant data. Techniques like Recursive Feature Elimination (RFE) help identify the most important features.
- Regularization: Regularization prevents overfitting by penalizing large coefficients in models like linear regression and logistic regression. This approach keeps the model simpler and more generalizable.
- Ensemble Methods: Ensemble methods combine predictions from multiple models to achieve better accuracy. Popular techniques include Bagging, Boosting, and Stacking, with algorithms like Random Forests and Gradient Boosting widely used in practice.
Example of implementing feature scaling and regularization with logistic regression:
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
# Scale features
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# Initialize logistic regression with regularization
model = LogisticRegression(C=1.0, penalty='l2')
model.fit(X_train_scaled, y_train)These optimization techniques refine model performance, ensuring it generalizes well to new data while balancing complexity and accuracy.
Deploying AI Models in Production
Once an AI model is trained and optimized, the next step is deployment, where the model becomes part of a live system, making predictions on real-time data. Model deployment ensures that your AI solution is accessible, scalable, and ready for continuous use.
1. Saving and Loading Models
The first step in deployment is saving the trained model, so it can be reused without retraining. In Python, libraries like joblib and pickle make it easy to save and load models.
- Example: Saving and loading a model with
joblib:
import joblib
# Save the model
joblib.dump(model, 'model.pkl')
# Load the model
loaded_model = joblib.load('model.pkl')This approach allows you to store the model as a file, load it as needed, and use it in production environments for making predictions.
2. Deploying with Flask for a Web API
Flask, a lightweight Python web framework, is widely used to create a RESTful API for machine learning models. Using Flask, you can deploy a model as an API endpoint, which other applications can access for real-time predictions.
- Example: Setting up a simple Flask app to serve model predictions:
from flask import Flask, request, jsonify
import joblib
# Load the saved model
model = joblib.load('model.pkl')
# Initialize the Flask app
app = Flask(__name__)
@app.route('/predict', methods=['POST'])
def predict():
# Get JSON data from the request
data = request.get_json(force=True)
features = data['features']
# Make prediction
prediction = model.predict([features])
# Return prediction as JSON
return jsonify({'prediction': prediction[0]})
if __name__ == '__main__':
app.run(debug=True)In this setup, the model listens for POST requests at the /predict endpoint, where it accepts input data and returns predictions. This API can then be deployed on a cloud platform for production use.
3. Cloud Deployment
For large-scale applications, deploying models on cloud platforms like Amazon Web Services (AWS) SageMaker, Google Cloud AI Platform, or Microsoft Azure ML provides scalability, security, and access to powerful resources.
- Benefits:
- Scalability: Cloud services automatically adjust to handle increased demand.
- Security: Cloud providers offer robust security features, including encryption and access controls.
- Integrated Tools: Cloud platforms provide built-in monitoring, logging, and version control for easier management.
- Example: Using Google Cloud AI Platform, you can upload and deploy your model as a service, which can then be integrated with applications via REST API calls.
By deploying on the cloud, you can serve your model to a wide range of users and applications, ensuring reliable and scalable predictions.
Monitoring Model Performance in Production
Once a model is deployed, it’s important to monitor its performance over time. Changes in real-world data, also known as data drift, can reduce model accuracy, making monitoring essential for maintaining performance.
1. Setting Up Monitoring Metrics
Establishing key metrics to track is essential. The metrics depend on the application, but common ones include:
- Accuracy: Measures how often predictions match actual outcomes.
- Latency: Tracks the time taken by the model to make predictions, critical in real-time applications.
- Throughput: Monitors the volume of data processed, useful for scaling.
These metrics can be logged and visualized in tools like Prometheus and Grafana or integrated with cloud monitoring solutions such as AWS CloudWatch or Google Cloud Monitoring.
2. Detecting Data Drift
Data drift occurs when the data distribution changes over time, which can reduce model performance. Monitoring data drift involves analyzing incoming data and comparing it to the data the model was trained on. Drift can be detected by measuring statistical changes in key features or by observing declining performance metrics.
- Example: Calculating drift with statistical tests, such as the Kolmogorov-Smirnov test, helps detect significant differences in data distributions.
3. Automating Retraining with New Data
To maintain performance, models often need to be retrained periodically with fresh data. Automating this process can involve setting up a pipeline that regularly updates the model:
- Data Collection: Collect new labeled data from production.
- Model Retraining: Retrain the model on combined old and new data.
- Evaluation: Test the new model against benchmarks to ensure improvement.
- Deployment: Replace the existing model with the updated one if it performs better.
Automation tools like Apache Airflow or cloud-based workflows allow you to set up these retraining pipelines, ensuring your model stays accurate.
Model Maintenance and Best Practices
Maintaining models in production requires ongoing attention to ensure they remain accurate, efficient, and secure. Here are some best practices for long-term model maintenance:
1. Version Control for Models
Just as with software development, maintaining version control for AI models is crucial. Version control helps track model changes over time, enabling you to revert to previous versions if necessary. Tools like DVC (Data Version Control) and MLflow allow you to track model versions, parameters, and performance.
- Example: Using MLflow to log and version models:
import mlflow
# Log model with MLflow
mlflow.log_param("model_type", "LogisticRegression")
mlflow.log_metric("accuracy", accuracy)
mlflow.sklearn.log_model(model, "logistic_regression_model")MLflow provides a central place to manage model artifacts and metadata, streamlining the versioning process.
2. Security and Access Management
In production environments, protecting the model and data is essential. Implementing access controls, encryption, and regular security audits can help maintain data integrity and prevent unauthorized access. Most cloud providers offer built-in security features, including role-based access control (RBAC) and encryption at rest and in transit.
3. Regular Performance Audits
Conducting periodic audits to evaluate model performance on new data ensures that the model remains accurate. Performance audits involve comparing predictions to actual outcomes and assessing whether the model still meets accuracy standards.
4. Model Explainability and Interpretability
In some applications, it’s critical to understand why a model makes specific predictions, especially in regulated industries like finance and healthcare. Explainable AI (XAI) techniques, such as LIME (Local Interpretable Model-agnostic Explanations) and SHAP (SHapley Additive exPlanations), help interpret model decisions.
- Example: Using SHAP to interpret model predictions:
import shap
# Initialize SHAP explainer
explainer = shap.Explainer(model, X_train)
shap_values = explainer(X_test)
# Plot SHAP values
shap.summary_plot(shap_values, X_test)SHAP and LIME allow you to see how individual features contribute to each prediction, helping build trust with users and stakeholders.
5. Continuous Improvement with Feedback Loops
Establishing a feedback loop in production enables models to learn from user interactions and real-world outcomes. Feedback loops provide new labeled data for retraining, allowing the model to improve and adapt to changing patterns.
For example, in recommendation systems, feedback from user ratings or interactions can be used to refine the model, ensuring recommendations remain relevant and engaging.
Conclusion
Data science fundamentals are crucial for developing, deploying, and maintaining AI models effectively. From understanding data distributions to building, tuning, and evaluating models, each step plays a role in creating reliable AI solutions. With proper deployment strategies and regular monitoring, AI models can provide consistent, high-quality predictions in production environments.
As AI continues to grow, mastering data science fundamentals will prepare you to address complex challenges, from data drift and model retraining to security and interpretability. By following these best practices, you’ll be equipped to create AI solutions that are not only accurate but also scalable and resilient in real-world applications.



{kind=link}